
Program | Technical Program
Presentation by the TPC
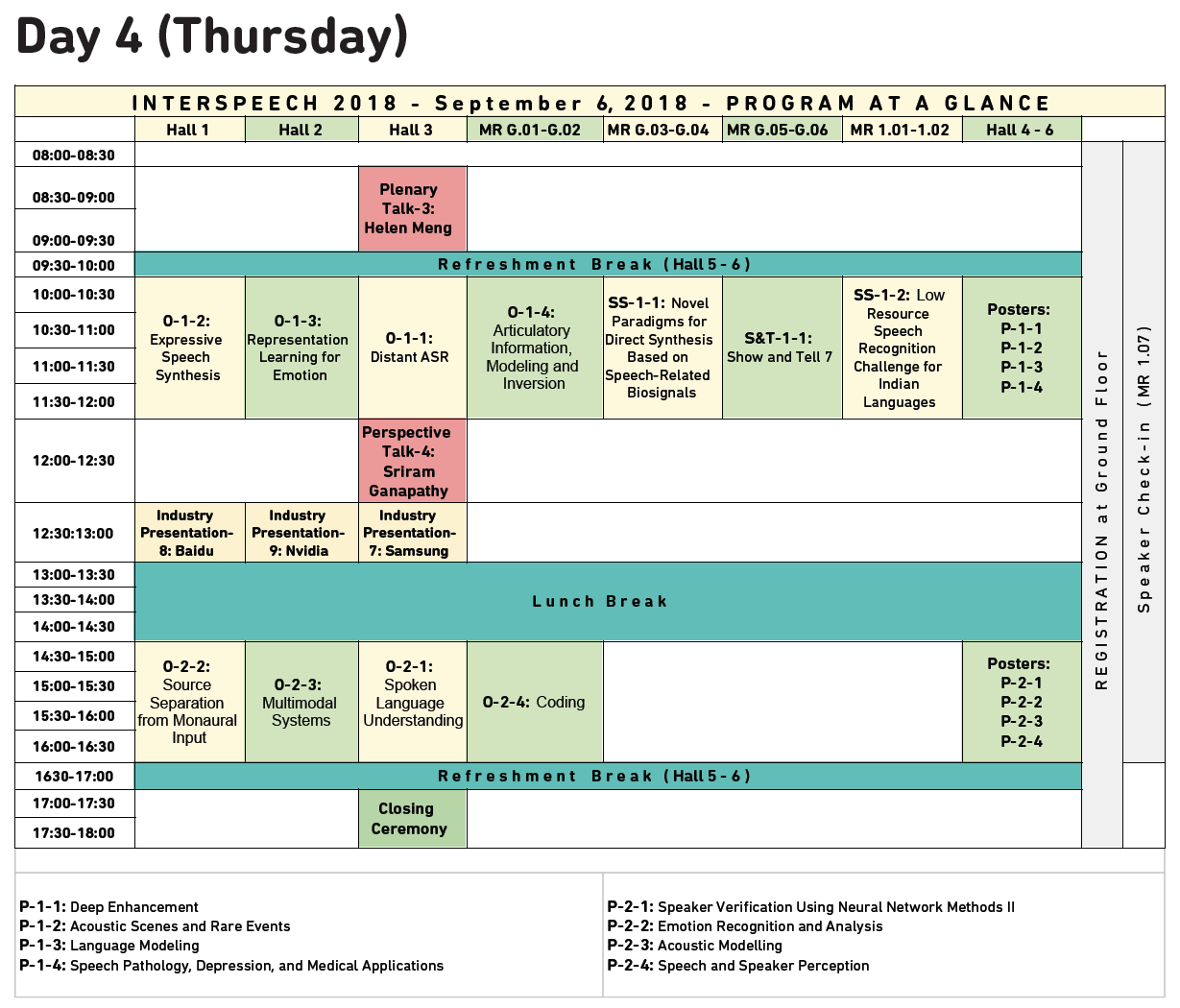
Program at a glance

Interspeech 2018 papers on ISCA Archive
Day-wise Program View




Session-wise Program View
- Mon-O-1-1-1 (1746) Semi-Supervised End-to-End Speech Recognition
- Mon-O-1-1-2 (1616) Improved Training of End-to-end Attention Models for Speech Recognition
- Mon-O-1-1-3 (1423) End-to-end Speech Recognition Using Lattice-free MMI
- Mon-O-1-1-4 (1301) Multi-channel Attention for End-to-End Speech Recognition
- Mon-O-1-1-5 (1898) Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
- Mon-O-1-1-6 (1025) Compression of End-to-End Models
- Mon-O-1-1-2 (1616) Improved Training of End-to-end Attention Models for Speech Recognition
- Mon-O-1-1-3 (1423) End-to-end Speech Recognition Using Lattice-free MMI
- Mon-O-1-1-4 (1301) Multi-channel Attention for End-to-End Speech Recognition
- Mon-O-1-1-5 (1898) Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
- Mon-O-1-1-6 (1025) Compression of End-to-End Models
- Mon-O-1-2-1 (2075) Learning Interpretable Control Dimensions for Speech Synthesis by Using External Data
- Mon-O-1-2-2 (1227) Investigating Accuracy of Pitch-accent Annotations in Neural Network-based Speech Synthesis and Denoising Effects
- Mon-O-1-2-3 (1214) An Exploration of Local Speaking Rate Variations in Mandarin Read Speech
- Mon-O-1-2-4 (1472) BLSTM-CRF Based End-to-End Prosodic Boundary Prediction with Context Sensitive Embeddings in a Text-to-Speech Front-End
- Mon-O-1-2-5 (1499) Wavelet Analysis of Speaker Dependent and Independent Prosody for Voice Conversion
- Mon-O-1-2-6 (1706) Improving Mongolian Phrase Break Prediction by Using Syllable and Morphological Embeddings with BiLSTM Model
- Mon-O-1-2-2 (1227) Investigating Accuracy of Pitch-accent Annotations in Neural Network-based Speech Synthesis and Denoising Effects
- Mon-O-1-2-3 (1214) An Exploration of Local Speaking Rate Variations in Mandarin Read Speech
- Mon-O-1-2-4 (1472) BLSTM-CRF Based End-to-End Prosodic Boundary Prediction with Context Sensitive Embeddings in a Text-to-Speech Front-End
- Mon-O-1-2-5 (1499) Wavelet Analysis of Speaker Dependent and Independent Prosody for Voice Conversion
- Mon-O-1-2-6 (1706) Improving Mongolian Phrase Break Prediction by Using Syllable and Morphological Embeddings with BiLSTM Model
- Mon-O-1-3-1 (41) Improved Supervised Locality Preserving Projection for I-vector Based Speaker Verification
- Mon-O-1-3-2 (1103) Double Joint Bayesian Modeling of DNN Local I-Vector for Text Dependent Speaker Verification with Random Digit Strings
- Mon-O-1-3-3 (2128) Fast Variational Bayes for Heavy-tailed PLDA Applied to I-vectors and X-vectors
- Mon-O-1-3-4 (2289) Integrated Presentation Attack Detection and Automatic Speaker Verification: Common Features and Gaussian Back-end Fusion
- Mon-O-1-3-5 (1280) A Generalization of PLDA for Joint Modeling of Speaker Identity and Multiple Nuisance Conditions
- Mon-O-1-3-6 (2474) An Investigation of Non-linear I-vectors for Speaker Verification
- Mon-O-1-3-2 (1103) Double Joint Bayesian Modeling of DNN Local I-Vector for Text Dependent Speaker Verification with Random Digit Strings
- Mon-O-1-3-3 (2128) Fast Variational Bayes for Heavy-tailed PLDA Applied to I-vectors and X-vectors
- Mon-O-1-3-4 (2289) Integrated Presentation Attack Detection and Automatic Speaker Verification: Common Features and Gaussian Back-end Fusion
- Mon-O-1-3-5 (1280) A Generalization of PLDA for Joint Modeling of Speaker Identity and Multiple Nuisance Conditions
- Mon-O-1-3-6 (2474) An Investigation of Non-linear I-vectors for Speaker Verification
- Mon-O-1-4-1 (1722) CNN Based Query by Example Spoken Term Detection
- Mon-O-1-4-2 (1010) Learning Acoustic Word Embeddings with Temporal Context for Query-by-Example Speech Search
- Mon-O-1-4-3 (1788) Siamese Recurrent Auto-encoder Representation for Query-by-Example Spoken Term Detection
- Mon-O-1-4-4 (1459) Fast Derivation of Cross-lingual Document Vectors from Self-attentive Neural Machine Translation Model
- Mon-O-1-4-5 (1016) LSTM Based Attentive Fusion of Spectral and Prosodic Information for Keyword Spotting in Hindi Language
- Mon-O-1-4-6 (1436) Spoken Keyword Detection Using Joint DTW-CNN
- Mon-O-1-4-2 (1010) Learning Acoustic Word Embeddings with Temporal Context for Query-by-Example Speech Search
- Mon-O-1-4-3 (1788) Siamese Recurrent Auto-encoder Representation for Query-by-Example Spoken Term Detection
- Mon-O-1-4-4 (1459) Fast Derivation of Cross-lingual Document Vectors from Self-attentive Neural Machine Translation Model
- Mon-O-1-4-5 (1016) LSTM Based Attentive Fusion of Spectral and Prosodic Information for Keyword Spotting in Hindi Language
- Mon-O-1-4-6 (1436) Spoken Keyword Detection Using Joint DTW-CNN
- Mon-SS-1-1-1 (51) The INTERSPEECH 2018 Computational Paralinguistics Challenge: Atypical & Self-Assessed Affect, Crying & Heart Beats
- Mon-SS-1-1-2 (-) Heart Beat Sub-Challenge
- Mon-SS-1-1-3 (2413) An Ensemble of Transfer, Semi-supervised and Supervised Learning Methods for Pathological Heart Sound Classification
- Mon-SS-1-1-4 (-) Crying Sub-Challenge
- Mon-SS-1-1-5 (2187) Monitoring Infant’S Emotional Cry in Domestic Environments Using the Capsule Network Architecture
- Mon-SS-1-1-6 (1959) Neural Network Architecture That Combines Temporal and Summative Features for Infant Cry Classification in the Interspeech 2018 Computational Paralinguistics Challenge
- Mon-SS-1-1-7 (1914) Evolving Learning for Analysing Mood-Related Infant Vocalisation
- Mon-SS-1-1-8 (-) Atypical Affect Sub-Challenge
- Mon-SS-1-1-9 (1238) Deep Learning in Paralinguistic Recognition Tasks: Are Hand-crafted Features Still Relevant?
- Mon-SS-1-1-10 (1832) Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition
- Mon-SS-1-1-11 (1401) Using Voice Quality Supervectors for Affect Identification
- Mon-SS-1-1-12 (2581) An End-to-End Deep Learning Framework for Speech Emotion Recognition of Atypical Individuals
- Mon-SS-1-1-2 (-) Heart Beat Sub-Challenge
- Mon-SS-1-1-3 (2413) An Ensemble of Transfer, Semi-supervised and Supervised Learning Methods for Pathological Heart Sound Classification
- Mon-SS-1-1-4 (-) Crying Sub-Challenge
- Mon-SS-1-1-5 (2187) Monitoring Infant’S Emotional Cry in Domestic Environments Using the Capsule Network Architecture
- Mon-SS-1-1-6 (1959) Neural Network Architecture That Combines Temporal and Summative Features for Infant Cry Classification in the Interspeech 2018 Computational Paralinguistics Challenge
- Mon-SS-1-1-7 (1914) Evolving Learning for Analysing Mood-Related Infant Vocalisation
- Mon-SS-1-1-8 (-) Atypical Affect Sub-Challenge
- Mon-SS-1-1-9 (1238) Deep Learning in Paralinguistic Recognition Tasks: Are Hand-crafted Features Still Relevant?
- Mon-SS-1-1-10 (1832) Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition
- Mon-SS-1-1-11 (1401) Using Voice Quality Supervectors for Affect Identification
- Mon-SS-1-1-12 (2581) An End-to-End Deep Learning Framework for Speech Emotion Recognition of Atypical Individuals
- Mon-S&T-1-1-1 (3002) DialogOS: Simple and extensible dialogue modeling
- Mon-S&T-1-1-2 (3003) A Framework for Speech Recognition Benchmarking
- Mon-S&T-1-1-3 (3004) Flexible tongue housed in a static model of the vocal tract with jaws, lips and teeth
- Mon-S&T-1-1-4 (3005) Voice Analysis Using Acoustic and Throat Microphones for Speech Therapy
- Mon-S&T-1-1-5 (3006) A Robust Context-Dependent Speech-to-Speech Phraselator Toolkit for Alexa
- Mon-S&T-1-1-2 (3003) A Framework for Speech Recognition Benchmarking
- Mon-S&T-1-1-3 (3004) Flexible tongue housed in a static model of the vocal tract with jaws, lips and teeth
- Mon-S&T-1-1-4 (3005) Voice Analysis Using Acoustic and Throat Microphones for Speech Therapy
- Mon-S&T-1-1-5 (3006) A Robust Context-Dependent Speech-to-Speech Phraselator Toolkit for Alexa
- Mon-P-1-1-1 (1032) Discriminating Nasals and Approximants in English Language Using Zero Time Windowing
- Mon-P-1-1-2 (1404) Gestural Lenition of Rhotics Captures Variation in Brazilian Portuguese
- Mon-P-1-1-3 (1958) Identification and Classification of Fricatives in Speech Using Zero Time Windowing Method
- Mon-P-1-1-4 (1185) GlobalTIMIT: Acoustic-Phonetic Datasets for the World’S Languages
- Mon-P-1-1-5 (1074) Structural Effects on Properties of Consonantal Gestures in Tashlhiyt
- Mon-P-1-1-6 (1457) The Retroflex-dental Contrast in Punjabi Stops and Nasals: a Principal Component Analysis of Ultrasound Images
- Mon-P-1-1-7 (1225) Vowels and Diphthongs in Hangzhou Wu Chinese Dialect
- Mon-P-1-1-8 (1176) Resyllabification in Indian Languages and Its Implications in Text-to-speech Systems
- Mon-P-1-1-9 (2352) Voice Source Contribution to Prominence Perception: Rd Implementation
- Mon-P-1-1-10 (2532) On the Relationship between Glottal Pulse Shape and Its Spectrum: Correlations of Open Quotient, Pulse Skew and Peak Flow with Source Harmonic Amplitudes
- Mon-P-1-1-11 (1649) The Individual and the System: Assessing the Stability of the Output of a Semi-automatic Forensic Voice Comparison System
- Mon-P-1-1-12 (2498) Breathy to Tense Voice Discrimination using Zero-Time Windowing Cepstral Coefficients (ZTWCCs)
- Mon-P-1-1-13 (1899) Analysis of Breathiness in Contextual Vowel of Voiceless Nasals in Mizo
- Mon-P-1-1-2 (1404) Gestural Lenition of Rhotics Captures Variation in Brazilian Portuguese
- Mon-P-1-1-3 (1958) Identification and Classification of Fricatives in Speech Using Zero Time Windowing Method
- Mon-P-1-1-4 (1185) GlobalTIMIT: Acoustic-Phonetic Datasets for the World’S Languages
- Mon-P-1-1-5 (1074) Structural Effects on Properties of Consonantal Gestures in Tashlhiyt
- Mon-P-1-1-6 (1457) The Retroflex-dental Contrast in Punjabi Stops and Nasals: a Principal Component Analysis of Ultrasound Images
- Mon-P-1-1-7 (1225) Vowels and Diphthongs in Hangzhou Wu Chinese Dialect
- Mon-P-1-1-8 (1176) Resyllabification in Indian Languages and Its Implications in Text-to-speech Systems
- Mon-P-1-1-9 (2352) Voice Source Contribution to Prominence Perception: Rd Implementation
- Mon-P-1-1-10 (2532) On the Relationship between Glottal Pulse Shape and Its Spectrum: Correlations of Open Quotient, Pulse Skew and Peak Flow with Source Harmonic Amplitudes
- Mon-P-1-1-11 (1649) The Individual and the System: Assessing the Stability of the Output of a Semi-automatic Forensic Voice Comparison System
- Mon-P-1-1-12 (2498) Breathy to Tense Voice Discrimination using Zero-Time Windowing Cepstral Coefficients (ZTWCCs)
- Mon-P-1-1-13 (1899) Analysis of Breathiness in Contextual Vowel of Voiceless Nasals in Mizo
- Mon-P-1-2-1 (2429) Infant Emotional Outbursts Detection in Infant-parent Spoken Interactions
- Mon-P-1-2-2 (2466) Deep Neural Networks for Emotion Recognition Combining Audio and Transcripts
- Mon-P-1-2-3 (2478) Preference Learning with Qualitative Agreement for Sentence Level Emotional Annotations
- Mon-P-1-2-4 (1625) Transfer Learning for Improving Speech Emotion Classification Accuracy
- Mon-P-1-2-5 (1851) What Do Classifiers Actually Learn? a Case Study on Emotion Recognition Datasets
- Mon-P-1-2-6 (2043) State of Mind: Classification through Self-reported Affect and Word Use in Speech.
- Mon-P-1-2-7 (1477) Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition
- Mon-P-1-2-8 (2015) End-to-end Deep Neural Network Age Estimation
- Mon-P-1-2-9 (1462) Improving Gender Identification in Movie Audio Using Cross-Domain Data
- Mon-P-1-2-10 (1240) On Learning to Identify Genders from Raw Speech Signal Using CNNs
- Mon-P-1-2-11 (2321) Denoising and Raw-waveform Networks for Weakly-Supervised Gender Identification on Noisy Speech
- Mon-P-1-2-12 (2372) The Effect of Exposure to High Altitude and Heat on Speech Articulatory Coordination
- Mon-P-1-2-2 (2466) Deep Neural Networks for Emotion Recognition Combining Audio and Transcripts
- Mon-P-1-2-3 (2478) Preference Learning with Qualitative Agreement for Sentence Level Emotional Annotations
- Mon-P-1-2-4 (1625) Transfer Learning for Improving Speech Emotion Classification Accuracy
- Mon-P-1-2-5 (1851) What Do Classifiers Actually Learn? a Case Study on Emotion Recognition Datasets
- Mon-P-1-2-6 (2043) State of Mind: Classification through Self-reported Affect and Word Use in Speech.
- Mon-P-1-2-7 (1477) Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition
- Mon-P-1-2-8 (2015) End-to-end Deep Neural Network Age Estimation
- Mon-P-1-2-9 (1462) Improving Gender Identification in Movie Audio Using Cross-Domain Data
- Mon-P-1-2-10 (1240) On Learning to Identify Genders from Raw Speech Signal Using CNNs
- Mon-P-1-2-11 (2321) Denoising and Raw-waveform Networks for Weakly-Supervised Gender Identification on Noisy Speech
- Mon-P-1-2-12 (2372) The Effect of Exposure to High Altitude and Heat on Speech Articulatory Coordination
- Mon-P-1-3-1 (1603) Permutation Invariant Training of Generative Adversarial Network for Monaural Speech Separation
- Mon-P-1-3-2 (1205) Deep Extractor Network for Target Speaker Recovery from Single Channel Speech Mixtures
- Mon-P-1-3-3 (1269) Joint Localization and Classification of Multiple Sound Sources Using a Multi-task Neural Network
- Mon-P-1-3-4 (1281) Detection of Glottal Closure Instants from Speech Signals: a Convolutional Neural Network Based Method
- Mon-P-1-3-5 (1652) Robust TDOA Estimation Based on Time-Frequency Masking and Deep Neural Networks
- Mon-P-1-3-6 (1671) Waveform to Single Sinusoid Regression to Estimate the F0 Contour from Noisy Speech Using Recurrent Deep Neural Networks
- Mon-P-1-3-7 (1845) Reducing Interference with Phase Recovery in DNN-based Monaural Singing Voice Separation
- Mon-P-1-3-8 (1258) Nebula: F0 Estimation and Voicing Detection by Modeling the Statistical Properties of Feature Extractors
- Mon-P-1-3-9 (2290) Real-time Single-channel Dereverberation and Separation with Time-domain Audio Separation Network
- Mon-P-1-3-10 (2326) Music Source Activity Detection and Separation Using Deep Attractor Network
- Mon-P-1-3-11 (2561) Improving Mandarin Tone Recognition Using Convolutional Bidirectional Long Short-Term Memory with Attention
- Mon-P-1-3-2 (1205) Deep Extractor Network for Target Speaker Recovery from Single Channel Speech Mixtures
- Mon-P-1-3-3 (1269) Joint Localization and Classification of Multiple Sound Sources Using a Multi-task Neural Network
- Mon-P-1-3-4 (1281) Detection of Glottal Closure Instants from Speech Signals: a Convolutional Neural Network Based Method
- Mon-P-1-3-5 (1652) Robust TDOA Estimation Based on Time-Frequency Masking and Deep Neural Networks
- Mon-P-1-3-6 (1671) Waveform to Single Sinusoid Regression to Estimate the F0 Contour from Noisy Speech Using Recurrent Deep Neural Networks
- Mon-P-1-3-7 (1845) Reducing Interference with Phase Recovery in DNN-based Monaural Singing Voice Separation
- Mon-P-1-3-8 (1258) Nebula: F0 Estimation and Voicing Detection by Modeling the Statistical Properties of Feature Extractors
- Mon-P-1-3-9 (2290) Real-time Single-channel Dereverberation and Separation with Time-domain Audio Separation Network
- Mon-P-1-3-10 (2326) Music Source Activity Detection and Separation Using Deep Attractor Network
- Mon-P-1-3-11 (2561) Improving Mandarin Tone Recognition Using Convolutional Bidirectional Long Short-Term Memory with Attention
- Mon-P-1-4-1 (68) Vowel Space as a Tool to Evaluate Articulation Problems
- Mon-P-1-4-2 (1054) Towards a Better Characterization of Parkinsonian Speech: a Multidimensional Acoustic Study
- Mon-P-1-4-3 (1125) Self-similarity Matrix Based Intelligibility Assessment of Cleft Lip and Palate Speech
- Mon-P-1-4-4 (1251) Pitch-Adaptive Front-end Feature for Hypernasality Detection
- Mon-P-1-4-5 (2389) Detection of Amyotrophic Lateral Sclerosis (ALS) via Acoustic Analysis
- Mon-P-1-4-6 (1665) Detection of Glottal Activity Errors in Production of Stop Consonants in Children with Cleft Lip and Palate
- Mon-P-1-4-2 (1054) Towards a Better Characterization of Parkinsonian Speech: a Multidimensional Acoustic Study
- Mon-P-1-4-3 (1125) Self-similarity Matrix Based Intelligibility Assessment of Cleft Lip and Palate Speech
- Mon-P-1-4-4 (1251) Pitch-Adaptive Front-end Feature for Hypernasality Detection
- Mon-P-1-4-5 (2389) Detection of Amyotrophic Lateral Sclerosis (ALS) via Acoustic Analysis
- Mon-P-1-4-6 (1665) Detection of Glottal Activity Errors in Production of Stop Consonants in Children with Cleft Lip and Palate
- Mon-O-2-1-1 (1392) Cold Fusion: Training Seq2Seq Models Together with Language Models
- Mon-O-2-1-2 (1766) Investigation on Estimation of Sentence Probability by Combining Forward, Backward and Bi-directional LSTM-RNNs
- Mon-O-2-1-3 (2057) Subword and Crossword Units for CTC Acoustic Models
- Mon-O-2-1-4 (1430) Neural Error Corrective Language Models for Automatic Speech Recognition
- Mon-O-2-1-5 (62) Entity-Aware Language Model as an Unsupervised Reranker
- Mon-O-2-1-6 (1727) Character-level Language Modeling with Gated Hierarchical Recurrent Neural Networks
- Mon-O-2-1-2 (1766) Investigation on Estimation of Sentence Probability by Combining Forward, Backward and Bi-directional LSTM-RNNs
- Mon-O-2-1-3 (2057) Subword and Crossword Units for CTC Acoustic Models
- Mon-O-2-1-4 (1430) Neural Error Corrective Language Models for Automatic Speech Recognition
- Mon-O-2-1-5 (62) Entity-Aware Language Model as an Unsupervised Reranker
- Mon-O-2-1-6 (1727) Character-level Language Modeling with Gated Hierarchical Recurrent Neural Networks
- Mon-O-2-2-1 (2443) Acoustic-Prosodic Indicators of Deception and Trust in Interview Dialogues
- Mon-O-2-2-2 (2269) Deep Personality Recognition for Deception Detection
- Mon-O-2-2-3 (1373) Cross-cultural (A)symmetries in Audio-visual Attitude Perception
- Mon-O-2-2-4 (1222) An Active Feature Transformation Method for Attitude Recognition of Video Bloggers
- Mon-O-2-2-5 (1523) Automatic Assessment of Individual Culture Attribute of Power Distance Using a Social Context-Enhanced Prosodic Network Representation
- Mon-O-2-2-6 (2502) Analysis and Detection of Phonation Modes in Singing Voice using Excitation Source Features and Single Frequency Filtering Cepstral Coefficients (SFFCC)
- Mon-O-2-2-2 (2269) Deep Personality Recognition for Deception Detection
- Mon-O-2-2-3 (1373) Cross-cultural (A)symmetries in Audio-visual Attitude Perception
- Mon-O-2-2-4 (1222) An Active Feature Transformation Method for Attitude Recognition of Video Bloggers
- Mon-O-2-2-5 (1523) Automatic Assessment of Individual Culture Attribute of Power Distance Using a Social Context-Enhanced Prosodic Network Representation
- Mon-O-2-2-6 (2502) Analysis and Detection of Phonation Modes in Singing Voice using Excitation Source Features and Single Frequency Filtering Cepstral Coefficients (SFFCC)
- Mon-O-2-3-1 (1351) A Deep Learning Method for Pathological Voice Detection Using Convolutional Deep Belief Networks
- Mon-O-2-3-2 (1754) Dysarthric Speech Recognition Using Time-delay Neural Network Based Denoising Autoencoder
- Mon-O-2-3-3 (1988) A Multitask Learning Approach to Assess the Dysarthria Severity in Patients with Parkinson's Disease
- Mon-O-2-3-4 (2398) The Use of Machine Learning and Phonetic Endophenotypes to Discover Genetic Variants Associated with Speech Sound Disorder
- Mon-O-2-3-5 (2391) Whistle-blowing ASRs: Evaluating the Need for More Inclusive Speech Recognition Systems
- Mon-O-2-3-6 (1751) Data Augmentation Using Healthy Speech for Dysarthric Speech Recognition
- Mon-O-2-3-2 (1754) Dysarthric Speech Recognition Using Time-delay Neural Network Based Denoising Autoencoder
- Mon-O-2-3-3 (1988) A Multitask Learning Approach to Assess the Dysarthria Severity in Patients with Parkinson's Disease
- Mon-O-2-3-4 (2398) The Use of Machine Learning and Phonetic Endophenotypes to Discover Genetic Variants Associated with Speech Sound Disorder
- Mon-O-2-3-5 (2391) Whistle-blowing ASRs: Evaluating the Need for More Inclusive Speech Recognition Systems
- Mon-O-2-3-6 (1751) Data Augmentation Using Healthy Speech for Dysarthric Speech Recognition
- Mon-O-2-4-1 (1272) Improving Sparse Representations in Exemplar-Based Voice Conversion with a Phoneme-Selective Objective Function
- Mon-O-2-4-2 (1295) Learning Structured Dictionaries for Exemplar-based Voice Conversion
- Mon-O-2-4-3 (1662) Exemplar-Based Spectral Detail Compensation for Voice Conversion
- Mon-O-2-4-4 (1487) Whispered Speech to Neutral Speech Conversion Using Bidirectional LSTMs
- Mon-O-2-4-5 (1504) Voice Conversion across Arbitrary Speakers Based on a Single Target-Speaker Utterance
- Mon-O-2-4-6 (1830) Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
- Mon-O-2-4-2 (1295) Learning Structured Dictionaries for Exemplar-based Voice Conversion
- Mon-O-2-4-3 (1662) Exemplar-Based Spectral Detail Compensation for Voice Conversion
- Mon-O-2-4-4 (1487) Whispered Speech to Neutral Speech Conversion Using Bidirectional LSTMs
- Mon-O-2-4-5 (1504) Voice Conversion across Arbitrary Speakers Based on a Single Target-Speaker Utterance
- Mon-O-2-4-6 (1830) Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
- Mon-SS-2-1-1 (-) Self-assessed Affect Sub-Challenge
- Mon-SS-2-1-2 (1610) Attention-based Sequence Classification for Affect Detection
- Mon-SS-2-1-3 (2019) Computational Paralinguistics: Automatic Assessment of Emotions, Mood and Behavioural State from Acoustics of Speech
- Mon-SS-2-1-4 (2149) Investigating Utterance Level Representations for Detecting Intent from Acoustics
- Mon-SS-2-1-5 (2298) LSTM Based Cross-corpus and Cross-task Acoustic Emotion Recognition
- Mon-SS-2-1-6 (2360) Implementing Fusion Techniques for the Classification of Paralinguistic Information
- Mon-SS-2-1-7 (1076) General Utterance-Level Feature Extraction for Classifying Crying Sounds, Atypical & Self-Assessed Affect and Heart Beats
- Mon-SS-2-1-8 (2261) Self-Assessed Affect Recognition Using Fusion of Attentional BLSTM and Static Acoustic Features
- Mon-SS-2-1-9 (1331) Vocalic, Lexical and Prosodic Cues for the INTERSPEECH 2018 Self-Assessed Affect Challenge
- Mon-SS-2-1-10 (-) The INTERSPEECH 2018 Computational Paralinguistics Challenge: Summary of result
- Mon-SS-2-1-2 (1610) Attention-based Sequence Classification for Affect Detection
- Mon-SS-2-1-3 (2019) Computational Paralinguistics: Automatic Assessment of Emotions, Mood and Behavioural State from Acoustics of Speech
- Mon-SS-2-1-4 (2149) Investigating Utterance Level Representations for Detecting Intent from Acoustics
- Mon-SS-2-1-5 (2298) LSTM Based Cross-corpus and Cross-task Acoustic Emotion Recognition
- Mon-SS-2-1-6 (2360) Implementing Fusion Techniques for the Classification of Paralinguistic Information
- Mon-SS-2-1-7 (1076) General Utterance-Level Feature Extraction for Classifying Crying Sounds, Atypical & Self-Assessed Affect and Heart Beats
- Mon-SS-2-1-8 (2261) Self-Assessed Affect Recognition Using Fusion of Attentional BLSTM and Static Acoustic Features
- Mon-SS-2-1-9 (1331) Vocalic, Lexical and Prosodic Cues for the INTERSPEECH 2018 Self-Assessed Affect Challenge
- Mon-SS-2-1-10 (-) The INTERSPEECH 2018 Computational Paralinguistics Challenge: Summary of result
- Mon-S&T-2-1-1 (3008) Intonation tutor by SPIRE (In-SPIRE): An online tool for an automatic feedback to the second language learners in learning intonation
- Mon-S&T-2-1-2 (3045) Game-based spoken dialog language learning applications for young students
- Mon-S&T-2-1-3 (3011) The IBM Virtual Voice Creator
- Mon-S&T-2-1-4 (3012) Mobile Application for Learning Languages for the Unlettered
- Mon-S&T-2-1-5 (3014) Mandarin-English Code-switching Speech Recognition
- Mon-S&T-2-1-2 (3045) Game-based spoken dialog language learning applications for young students
- Mon-S&T-2-1-3 (3011) The IBM Virtual Voice Creator
- Mon-S&T-2-1-4 (3012) Mobile Application for Learning Languages for the Unlettered
- Mon-S&T-2-1-5 (3014) Mandarin-English Code-switching Speech Recognition
- Mon-P-2-1-1 (1581) Joint Learning of Domain Classification and Out-of-Domain Detection with Dynamic Class Weighting for Satisficing False Acceptance Rates
- Mon-P-2-1-2 (2084) Analyzing Vocal Tract Movements During Speech Accommodation
- Mon-P-2-1-3 (1039) Cross-Lingual Multi-Task Neural Architecture for Spoken Language Understanding
- Mon-P-2-1-4 (1333) Statistical Model Compression for Small-Footprint Natural Language Understanding
- Mon-P-2-1-5 (1679) Comparison of an End-to-end Trainable Dialogue System with a Modular Statistical Dialogue System
- Mon-P-2-1-6 (1419) A Discriminative Acoustic-Prosodic Approach for Measuring Local Entrainment
- Mon-P-2-1-7 (2124) Investigating Speech Features for Continuous Turn-Taking Prediction Using LSTMs
- Mon-P-2-1-8 (1348) Classification of Correction Turns in Multilingual Dialogue Corpus
- Mon-P-2-1-9 (1035) Contextual Slot Carryover for Disparate Schemas
- Mon-P-2-1-10 (1013) Capsule Networks for Low Resource Spoken Language Understanding
- Mon-P-2-1-11 (2436) Intent Discovery through Unsupervised Semantic Text Clustering
- Mon-P-2-1-12 (2011) Multimodal Polynomial Fusion for Detecting Driver Distraction
- Mon-P-2-1-13 (2067) Engagement Recognition in Spoken Dialogue via Neural Network by Aggregating Different Annotators' Models
- Mon-P-2-1-14 (1254) A First Investigation of the Timing of Turn-taking in Ruuli
- Mon-P-2-1-2 (2084) Analyzing Vocal Tract Movements During Speech Accommodation
- Mon-P-2-1-3 (1039) Cross-Lingual Multi-Task Neural Architecture for Spoken Language Understanding
- Mon-P-2-1-4 (1333) Statistical Model Compression for Small-Footprint Natural Language Understanding
- Mon-P-2-1-5 (1679) Comparison of an End-to-end Trainable Dialogue System with a Modular Statistical Dialogue System
- Mon-P-2-1-6 (1419) A Discriminative Acoustic-Prosodic Approach for Measuring Local Entrainment
- Mon-P-2-1-7 (2124) Investigating Speech Features for Continuous Turn-Taking Prediction Using LSTMs
- Mon-P-2-1-8 (1348) Classification of Correction Turns in Multilingual Dialogue Corpus
- Mon-P-2-1-9 (1035) Contextual Slot Carryover for Disparate Schemas
- Mon-P-2-1-10 (1013) Capsule Networks for Low Resource Spoken Language Understanding
- Mon-P-2-1-11 (2436) Intent Discovery through Unsupervised Semantic Text Clustering
- Mon-P-2-1-12 (2011) Multimodal Polynomial Fusion for Detecting Driver Distraction
- Mon-P-2-1-13 (2067) Engagement Recognition in Spoken Dialogue via Neural Network by Aggregating Different Annotators' Models
- Mon-P-2-1-14 (1254) A First Investigation of the Timing of Turn-taking in Ruuli
- Mon-P-2-2-1 (1042) Spoofing Detection Using Adaptive Weighting Framework and Clustering Analysis
- Mon-P-2-2-2 (1297) Exploration of Compressed ILPR Features for Replay Attack Detection
- Mon-P-2-2-3 (1473) Detection of Replay-Spoofing Attacks Using Frequency Modulation Features
- Mon-P-2-2-4 (1675) Effectiveness of Speech Demodulation-Based Features for Replay Detection
- Mon-P-2-2-5 (1687) Novel Variable Length Energy Separation Algorithm Using Instantaneous Amplitude Features for Replay Detection
- Mon-P-2-2-6 (1693) Feature with Complementarity of Statistics and Principal Information for Spoofing Detection
- Mon-P-2-2-7 (2001) Multiple Phase Information Combination for Replay Attacks Detection
- Mon-P-2-2-8 (1574) Frequency Domain Linear Prediction Features for Replay Spoofing Attack Detection
- Mon-P-2-2-9 (1651) Auditory Filterbank Learning for Temporal Modulation Features in Replay Spoof Speech Detection
- Mon-P-2-2-10 (1819) Deep Siamese Architecture Based Replay Detection for Secure Voice Biometric
- Mon-P-2-2-11 (1909) A Deep Identity Representation for Noise Robust Spoofing Detection
- Mon-P-2-2-12 (2279) End-To-End Audio Replay Attack Detection Using Deep Convolutional Networks with Attention
- Mon-P-2-2-13 (1494) Decision-level Feature Switching as a Paradigm for Replay Attack Detection
- Mon-P-2-2-14 (1846) Modulation Dynamic Features for the Detection of Replay Attacks
- Mon-P-2-2-2 (1297) Exploration of Compressed ILPR Features for Replay Attack Detection
- Mon-P-2-2-3 (1473) Detection of Replay-Spoofing Attacks Using Frequency Modulation Features
- Mon-P-2-2-4 (1675) Effectiveness of Speech Demodulation-Based Features for Replay Detection
- Mon-P-2-2-5 (1687) Novel Variable Length Energy Separation Algorithm Using Instantaneous Amplitude Features for Replay Detection
- Mon-P-2-2-6 (1693) Feature with Complementarity of Statistics and Principal Information for Spoofing Detection
- Mon-P-2-2-7 (2001) Multiple Phase Information Combination for Replay Attacks Detection
- Mon-P-2-2-8 (1574) Frequency Domain Linear Prediction Features for Replay Spoofing Attack Detection
- Mon-P-2-2-9 (1651) Auditory Filterbank Learning for Temporal Modulation Features in Replay Spoof Speech Detection
- Mon-P-2-2-10 (1819) Deep Siamese Architecture Based Replay Detection for Secure Voice Biometric
- Mon-P-2-2-11 (1909) A Deep Identity Representation for Noise Robust Spoofing Detection
- Mon-P-2-2-12 (2279) End-To-End Audio Replay Attack Detection Using Deep Convolutional Networks with Attention
- Mon-P-2-2-13 (1494) Decision-level Feature Switching as a Paradigm for Replay Attack Detection
- Mon-P-2-2-14 (1846) Modulation Dynamic Features for the Detection of Replay Attacks
- Mon-P-2-3-1 (1062) On the Usefulness of the Speech Phase Spectrum for Pitch Extraction
- Mon-P-2-3-2 (1230) Time-regularized Linear Prediction for Noise-robust Extraction of the Spectral Envelope of Speech
- Mon-P-2-3-3 (1536) Auditory Filterbank Learning Using ConvRBM for Infant Cry Classification
- Mon-P-2-3-4 (1538) Effectiveness of Dynamic Features in INCA and Temporal Context-INCA
- Mon-P-2-3-5 (1224) Singing Voice Phoneme Segmentation by Hierarchically Inferring Syllable and Phoneme Onset Positions
- Mon-P-2-3-6 (1661) Novel Empirical Mode Decomposition Cepstral Features for Replay Spoof Detection
- Mon-P-2-3-7 (1702) Novel Linear Frequency Residual Cepstral Features for Replay Attack Detection
- Mon-P-2-3-8 (1921) Analysis of Sparse Representation Based Feature on Speech Mode Classification
- Mon-P-2-3-9 (1937) Multicomponent 2-D AM-FM Modeling of Speech Spectrograms
- Mon-P-2-3-10 (1987) An Optimization Framework for Recovery of Speech from Phase-Encoded Spectrograms
- Mon-P-2-3-11 (2430) Speaker Recognition with Nonlinear Distortion: Clipping Analysis and Impact
- Mon-P-2-3-12 (1128) Linear Prediction Residual Based Short-term Cepstral Features for Replay Attacks Detection
- Mon-P-2-3-13 (1947) Analysis of Variational Mode Functions for Robust Detection of Vowels
- Mon-P-2-3-2 (1230) Time-regularized Linear Prediction for Noise-robust Extraction of the Spectral Envelope of Speech
- Mon-P-2-3-3 (1536) Auditory Filterbank Learning Using ConvRBM for Infant Cry Classification
- Mon-P-2-3-4 (1538) Effectiveness of Dynamic Features in INCA and Temporal Context-INCA
- Mon-P-2-3-5 (1224) Singing Voice Phoneme Segmentation by Hierarchically Inferring Syllable and Phoneme Onset Positions
- Mon-P-2-3-6 (1661) Novel Empirical Mode Decomposition Cepstral Features for Replay Spoof Detection
- Mon-P-2-3-7 (1702) Novel Linear Frequency Residual Cepstral Features for Replay Attack Detection
- Mon-P-2-3-8 (1921) Analysis of Sparse Representation Based Feature on Speech Mode Classification
- Mon-P-2-3-9 (1937) Multicomponent 2-D AM-FM Modeling of Speech Spectrograms
- Mon-P-2-3-10 (1987) An Optimization Framework for Recovery of Speech from Phase-Encoded Spectrograms
- Mon-P-2-3-11 (2430) Speaker Recognition with Nonlinear Distortion: Clipping Analysis and Impact
- Mon-P-2-3-12 (1128) Linear Prediction Residual Based Short-term Cepstral Features for Replay Attacks Detection
- Mon-P-2-3-13 (1947) Analysis of Variational Mode Functions for Robust Detection of Vowels
- Mon-P-2-4-1 (1030) Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition
- Mon-P-2-4-2 (1212) Segmental Encoder-Decoder Models for Large Vocabulary Automatic Speech Recognition
- Mon-P-2-4-3 (1049) Acoustic Modeling with DFSMN-CTC and Joint CTC-CE Learning
- Mon-P-2-4-4 (1888) End-to-End Speech Command Recognition with Capsule Network
- Mon-P-2-4-5 (2414) End-to-End Speech Recognition from the Raw Waveform
- Mon-P-2-4-6 (1452) A Multistage Training Framework for Acoustic-to-Word Model
- Mon-P-2-4-7 (1107) Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese
- Mon-P-2-4-8 (1486) Densely Connected Networks for Conversational Speech Recognition
- Mon-P-2-4-9 (1655) Multi-Head Decoder for End-to-End Speech Recognition
- Mon-P-2-4-10 (1543) Compressing End-to-end ASR Networks by Tensor-Train Decomposition
- Mon-P-2-4-11 (2341) Speech2Vec: a Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
- Mon-P-2-4-12 (1086) Extending Recurrent Neural Aligner for Streaming End-to-End Speech Recognition in Mandarin
- Mon-P-2-4-2 (1212) Segmental Encoder-Decoder Models for Large Vocabulary Automatic Speech Recognition
- Mon-P-2-4-3 (1049) Acoustic Modeling with DFSMN-CTC and Joint CTC-CE Learning
- Mon-P-2-4-4 (1888) End-to-End Speech Command Recognition with Capsule Network
- Mon-P-2-4-5 (2414) End-to-End Speech Recognition from the Raw Waveform
- Mon-P-2-4-6 (1452) A Multistage Training Framework for Acoustic-to-Word Model
- Mon-P-2-4-7 (1107) Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese
- Mon-P-2-4-8 (1486) Densely Connected Networks for Conversational Speech Recognition
- Mon-P-2-4-9 (1655) Multi-Head Decoder for End-to-End Speech Recognition
- Mon-P-2-4-10 (1543) Compressing End-to-end ASR Networks by Tensor-Train Decomposition
- Mon-P-2-4-11 (2341) Speech2Vec: a Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
- Mon-P-2-4-12 (1086) Extending Recurrent Neural Aligner for Streaming End-to-End Speech Recognition in Mandarin
- Mon-P-2-5-1 (1135) Joint Noise and Reverberation Adaptive Learning for Robust Speaker DOA Estimation with an Acoustic Vector Sensor
- Mon-P-2-5-2 (1248) Multiple Concurrent Sound Source Tracking Based on Observation-Guided Adaptive Particle Filter
- Mon-P-2-5-3 (1310) Harmonic-Percussive Source Separation of Polyphonic Music by Suppressing Impulsive Noise Events
- Mon-P-2-5-4 (1606) Speaker Activity Detection and Minimum Variance Beamforming for Source Separation
- Mon-P-2-5-5 (1615) Sparsity-Constrained Weight Mapping for Head-Related Transfer Functions Individualization from Anthropometric Features
- Mon-P-2-5-6 (1732) Speech Source Separation Using ICA in Constant Q Transform Domain
- Mon-P-2-5-7 (1739) Multi-talker Speech Separation Based on Permutation Invariant Training and Beamforming
- Mon-P-2-5-8 (1840) Expectation-Maximization Algorithms for Itakura-Saito Nonnegative Matrix Factorization
- Mon-P-2-5-9 (2173) Subband Weighting for Binaural Speech Source Localization
- Mon-P-2-5-2 (1248) Multiple Concurrent Sound Source Tracking Based on Observation-Guided Adaptive Particle Filter
- Mon-P-2-5-3 (1310) Harmonic-Percussive Source Separation of Polyphonic Music by Suppressing Impulsive Noise Events
- Mon-P-2-5-4 (1606) Speaker Activity Detection and Minimum Variance Beamforming for Source Separation
- Mon-P-2-5-5 (1615) Sparsity-Constrained Weight Mapping for Head-Related Transfer Functions Individualization from Anthropometric Features
- Mon-P-2-5-6 (1732) Speech Source Separation Using ICA in Constant Q Transform Domain
- Mon-P-2-5-7 (1739) Multi-talker Speech Separation Based on Permutation Invariant Training and Beamforming
- Mon-P-2-5-8 (1840) Expectation-Maximization Algorithms for Itakura-Saito Nonnegative Matrix Factorization
- Mon-P-2-5-9 (2173) Subband Weighting for Binaural Speech Source Localization
- Tue-O-1-1-1 (1244) Learning to Adapt: a Meta-learning Approach for Speaker Adaptation
- Tue-O-1-1-2 (2432) Speaker Adaptation and Adaptive Training for Jointly Optimised Tandem Systems
- Tue-O-1-1-3 (2022) Comparison of BLSTM-Layer-Specific Affine Transformations for Speaker Adaptation
- Tue-O-1-1-4 (1612) Correlational Networks for Speaker Normalization in Automatic Speech Recognition
- Tue-O-1-1-5 (1558) Machine Speech Chain with One-shot Speaker Adaptation
- Tue-O-1-1-6 (2246) Domain Adaptation Using Factorized Hidden Layer for Robust Automatic Speech Recognition
- Tue-O-1-1-2 (2432) Speaker Adaptation and Adaptive Training for Jointly Optimised Tandem Systems
- Tue-O-1-1-3 (2022) Comparison of BLSTM-Layer-Specific Affine Transformations for Speaker Adaptation
- Tue-O-1-1-4 (1612) Correlational Networks for Speaker Normalization in Automatic Speech Recognition
- Tue-O-1-1-5 (1558) Machine Speech Chain with One-shot Speaker Adaptation
- Tue-O-1-1-6 (2246) Domain Adaptation Using Factorized Hidden Layer for Robust Automatic Speech Recognition
- Tue-O-1-2-1 (1154) Waveform-Based Speaker Representations for Speech Synthesis
- Tue-O-1-2-2 (1561) Incremental TTS for Japanese Language
- Tue-O-1-2-3 (1265) Transfer Learning Based Progressive Neural Networks for Acoustic Modeling in Statistical Parametric Speech Synthesis
- Tue-O-1-2-4 (1590) A Unified Framework for the Generation of Glottal Signals in Deep Learning-based Parametric Speech Synthesis Systems
- Tue-O-1-2-5 (1598) Acoustic Modeling Using Adversarially Trained Variational Recurrent Neural Network for Speech Synthesis
- Tue-O-1-2-6 (1970) On the Application and Compression of Deep Time Delay Neural Network for Embedded Statistical Parametric Speech Synthesis
- Tue-O-1-2-2 (1561) Incremental TTS for Japanese Language
- Tue-O-1-2-3 (1265) Transfer Learning Based Progressive Neural Networks for Acoustic Modeling in Statistical Parametric Speech Synthesis
- Tue-O-1-2-4 (1590) A Unified Framework for the Generation of Glottal Signals in Deep Learning-based Parametric Speech Synthesis Systems
- Tue-O-1-2-5 (1598) Acoustic Modeling Using Adversarially Trained Variational Recurrent Neural Network for Speech Synthesis
- Tue-O-1-2-6 (1970) On the Application and Compression of Deep Time Delay Neural Network for Embedded Statistical Parametric Speech Synthesis
- Tue-O-1-3-1 (1377) Integrating Recurrence Dynamics for Speech Emotion Recognition
- Tue-O-1-3-2 (1858) Towards Temporal Modelling of Categorical Speech Emotion Recognition
- Tue-O-1-3-3 (1132) Emotion Recognition from Human Speech Using Temporal Information and Deep Learning
- Tue-O-1-3-4 (2508) Role of Regularization in the Prediction of Valence from Speech
- Tue-O-1-3-5 (1872) Learning Spontaneity to Improve Emotion Recognition in Speech
- Tue-O-1-3-6 (2464) Predicting Categorical Emotions by Jointly Learning Primary and Secondary Emotions through Multitask Learning
- Tue-O-1-3-2 (1858) Towards Temporal Modelling of Categorical Speech Emotion Recognition
- Tue-O-1-3-3 (1132) Emotion Recognition from Human Speech Using Temporal Information and Deep Learning
- Tue-O-1-3-4 (2508) Role of Regularization in the Prediction of Valence from Speech
- Tue-O-1-3-5 (1872) Learning Spontaneity to Improve Emotion Recognition in Speech
- Tue-O-1-3-6 (2464) Predicting Categorical Emotions by Jointly Learning Primary and Secondary Emotions through Multitask Learning
- Tue-O-1-4-1 (1760) Picture Naming or Word Reading: Does the Modality Affect Speech Motor Adaptation and Its Transfer?
- Tue-O-1-4-2 (1825) Measuring the Band Importance Function for Mandarin Chinese with an Bayesian Adaptive Procedure
- Tue-O-1-4-3 (2420) Wide Learning for Auditory Comprehension
- Tue-O-1-4-4 (1728) Analyzing Reaction Time Sequences from Human Participants in Auditory Experiments
- Tue-O-1-4-5 (1374) Prediction of Perceived Speech Quality Using Deep Machine Listening
- Tue-O-1-4-6 (1375) Prediction of Subjective Listening Effort from Acoustic Data with Non-Intrusive Deep Models
- Tue-O-1-4-2 (1825) Measuring the Band Importance Function for Mandarin Chinese with an Bayesian Adaptive Procedure
- Tue-O-1-4-3 (2420) Wide Learning for Auditory Comprehension
- Tue-O-1-4-4 (1728) Analyzing Reaction Time Sequences from Human Participants in Auditory Experiments
- Tue-O-1-4-5 (1374) Prediction of Perceived Speech Quality Using Deep Machine Listening
- Tue-O-1-4-6 (1375) Prediction of Subjective Listening Effort from Acoustic Data with Non-Intrusive Deep Models
- Tue-O-1-5-1 (1293) A Case Study on the Importance of Belief State Representation for Dialogue Policy Management
- Tue-O-1-5-2 (1442) Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers
- Tue-O-1-5-3 (2527) Conversational Analysis Using Utterance-level Attention-based Bidirectional Recurrent Neural Networks
- Tue-O-1-5-4 (2005) A Comparative Study of Statistical Conversion of Face to Voice Based on Their Subjective Impressions
- Tue-O-1-5-5 (1007) Follow-up Question Generation Using Pattern-based Seq2Seq with a Small Corpus for Interview Coaching
- Tue-O-1-5-6 (2446) Coherence Models for Dialogue
- Tue-O-1-5-2 (1442) Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers
- Tue-O-1-5-3 (2527) Conversational Analysis Using Utterance-level Attention-based Bidirectional Recurrent Neural Networks
- Tue-O-1-5-4 (2005) A Comparative Study of Statistical Conversion of Face to Voice Based on Their Subjective Impressions
- Tue-O-1-5-5 (1007) Follow-up Question Generation Using Pattern-based Seq2Seq with a Small Corpus for Interview Coaching
- Tue-O-1-5-6 (2446) Coherence Models for Dialogue
- Tue-SS-1-1-1 (-) Introduction
- Tue-SS-1-1-2 (2529) Indian languages ASR: A multilingual phone recognition framework with IPA based common phone-set, predicted articulatory features and feature fusion
- Tue-SS-1-1-3 (1139) Rapid Collection of Spontaneous Speech Corpora Using Telephonic Community Forums
- Tue-SS-1-1-4 (1555) Effect of TTS Generated Audio on OOV Detection and Word Error Rate in ASR for Low-resource Languages
- Tue-SS-1-1-5 (2133) Development of Large Vocabulary Speech Recognition System with Keyword Search for Manipuri
- Tue-SS-1-1-6 (2125) Robust Mizo Continuous Speech Recognition
- Tue-SS-1-1-7 (2486) Semi-supervised and Active-learning Scenarios: Efficient Acoustic Model Refinement for a Low Resource Indian Language
- Tue-SS-1-1-8 (2122) Automatic Speech Recognition with Articulatory Information and a Unified Dictionary for Hindi, Marathi, Bengali, and Oriya
- Tue-SS-1-1-9 (-) All papers in this special session
- Tue-SS-1-1-10 (-) Discussion/Q&A
- Tue-SS-1-1-2 (2529) Indian languages ASR: A multilingual phone recognition framework with IPA based common phone-set, predicted articulatory features and feature fusion
- Tue-SS-1-1-3 (1139) Rapid Collection of Spontaneous Speech Corpora Using Telephonic Community Forums
- Tue-SS-1-1-4 (1555) Effect of TTS Generated Audio on OOV Detection and Word Error Rate in ASR for Low-resource Languages
- Tue-SS-1-1-5 (2133) Development of Large Vocabulary Speech Recognition System with Keyword Search for Manipuri
- Tue-SS-1-1-6 (2125) Robust Mizo Continuous Speech Recognition
- Tue-SS-1-1-7 (2486) Semi-supervised and Active-learning Scenarios: Efficient Acoustic Model Refinement for a Low Resource Indian Language
- Tue-SS-1-1-8 (2122) Automatic Speech Recognition with Articulatory Information and a Unified Dictionary for Hindi, Marathi, Bengali, and Oriya
- Tue-SS-1-1-9 (-) All papers in this special session
- Tue-SS-1-1-10 (-) Discussion/Q&A
- Tue-S&T-1-1-1 (3015) Captaina: Integrated pronunciation practice and data collection portal
- Tue-S&T-1-1-2 (3016) auMina - Enterprise Speech Analytics
- Tue-S&T-1-1-3 (3017) HoloCompanion: An MR Friend for EveryOne
- Tue-S&T-1-1-4 (3018) akeira - Virtual Assistant
- Tue-S&T-1-1-5 (3019) Brain-Computer Interface using Electroencephalogram signatures of Eye Blinks
- Tue-S&T-1-1-2 (3016) auMina - Enterprise Speech Analytics
- Tue-S&T-1-1-3 (3017) HoloCompanion: An MR Friend for EveryOne
- Tue-S&T-1-1-4 (3018) akeira - Virtual Assistant
- Tue-S&T-1-1-5 (3019) Brain-Computer Interface using Electroencephalogram signatures of Eye Blinks
- Tue-P-1-1-1 (61) Voice Comparison and Rhythm: Behavioral Differences between Target and Non-target Comparisons
- Tue-P-1-1-2 (1246) Co-whitening of I-vectors for Short and Long Duration Speaker Verification
- Tue-P-1-1-3 (1446) Compensation for Domain Mismatch in Text-independent Speaker Recognition
- Tue-P-1-1-4 (1500) Joint Learning of J-Vector Extractor and Joint Bayesian Model for Text Dependent Speaker Verification
- Tue-P-1-1-5 (1422) Latent Factor Analysis of Deep Bottleneck Features for Speaker Verification with Random Digit Strings
- Tue-P-1-1-6 (1929) VoxCeleb2: Deep Speaker Recognition
- Tue-P-1-1-7 (2012) Supervised I-vector Modeling - Theory and Applications
- Tue-P-1-1-8 (2412) LOCUST - Longitudinal Corpus and Toolset for Speaker Verification
- Tue-P-1-1-9 (2071) Analysis of Language Dependent Front-End for Speaker Recognition - Tue-P-1-1-10 (2221) Robust Speaker Recognition from Distant Speech under Real Reverberant Environments Using Speaker Embeddings
- Tue-P-1-1-11 (2394) Investigation on Bandwidth Extension for Speaker Recognition
- Tue-P-1-1-12 (1696) On Learning Vocal Tract System Related Speaker Discriminative Information from Raw Signal Using CNNs
- Tue-P-1-1-13 (1759) On Convolutional LSTM Modeling for Joint Wake-Word Detection and Text Dependent Speaker Verification
- Tue-P-1-1-14 (1593) Cosine Metric Learning for Speaker Verification in the I-vector Space
- Tue-P-1-1-15 (1363) An Unsupervised Neural Prediction Framework for Learning Speaker Embeddings Using Recurrent Neural Networks
- Tue-P-1-1-2 (1246) Co-whitening of I-vectors for Short and Long Duration Speaker Verification
- Tue-P-1-1-3 (1446) Compensation for Domain Mismatch in Text-independent Speaker Recognition
- Tue-P-1-1-4 (1500) Joint Learning of J-Vector Extractor and Joint Bayesian Model for Text Dependent Speaker Verification
- Tue-P-1-1-5 (1422) Latent Factor Analysis of Deep Bottleneck Features for Speaker Verification with Random Digit Strings
- Tue-P-1-1-6 (1929) VoxCeleb2: Deep Speaker Recognition
- Tue-P-1-1-7 (2012) Supervised I-vector Modeling - Theory and Applications
- Tue-P-1-1-8 (2412) LOCUST - Longitudinal Corpus and Toolset for Speaker Verification
- Tue-P-1-1-9 (2071) Analysis of Language Dependent Front-End for Speaker Recognition - Tue-P-1-1-10 (2221) Robust Speaker Recognition from Distant Speech under Real Reverberant Environments Using Speaker Embeddings
- Tue-P-1-1-11 (2394) Investigation on Bandwidth Extension for Speaker Recognition
- Tue-P-1-1-12 (1696) On Learning Vocal Tract System Related Speaker Discriminative Information from Raw Signal Using CNNs
- Tue-P-1-1-13 (1759) On Convolutional LSTM Modeling for Joint Wake-Word Detection and Text Dependent Speaker Verification
- Tue-P-1-1-14 (1593) Cosine Metric Learning for Speaker Verification in the I-vector Space
- Tue-P-1-1-15 (1363) An Unsupervised Neural Prediction Framework for Learning Speaker Embeddings Using Recurrent Neural Networks
- Tue-P-1-2-1 (1223) A New Framework for Supervised Speech Enhancement in the Time Domain
- Tue-P-1-2-2 (1294) Speech Enhancement Using the Minimum-probability-of-error Criterion
- Tue-P-1-2-3 (1387) Exploring the Relationship between Conic Affinity of NMF Dictionaries and Speech Enhancement Metrics
- Tue-P-1-2-4 (1650) Using Shifted Real Spectrum Mask as Training Target for Supervised Speech Separation
- Tue-P-1-2-5 (1928) Enhancement of Noisy Speech Signal by Non-Local Means Estimation of Variational Mode Functions
- Tue-P-1-2-6 (1950) Phase-locked Loop Based Phase Estimation in Single Channel Speech Enhancement
- Tue-P-1-2-7 (2409) Cycle-Consistent Speech Enhancement
- Tue-P-1-2-8 (1955) Visual Speech Enhancement
- Tue-P-1-2-9 (2031) Implementation of Digital Hearing Aid as a Smartphone Application
- Tue-P-1-2-10 (1046) Bone-Conduction Sensor Assisted Noise Estimation for Improved Speech Enhancement
- Tue-P-1-2-11 (2213) Artificial Bandwidth Extension with Memory Inclusion Using Semi-supervised Stacked Auto-encoders
- Tue-P-1-2-12 (2383) Large Vocabulary Concatenative Resynthesis
- Tue-P-1-2-13 (2439) Concatenative Resynthesis with Improved Training Signals for Speech Enhancement
- Tue-P-1-2-2 (1294) Speech Enhancement Using the Minimum-probability-of-error Criterion
- Tue-P-1-2-3 (1387) Exploring the Relationship between Conic Affinity of NMF Dictionaries and Speech Enhancement Metrics
- Tue-P-1-2-4 (1650) Using Shifted Real Spectrum Mask as Training Target for Supervised Speech Separation
- Tue-P-1-2-5 (1928) Enhancement of Noisy Speech Signal by Non-Local Means Estimation of Variational Mode Functions
- Tue-P-1-2-6 (1950) Phase-locked Loop Based Phase Estimation in Single Channel Speech Enhancement
- Tue-P-1-2-7 (2409) Cycle-Consistent Speech Enhancement
- Tue-P-1-2-8 (1955) Visual Speech Enhancement
- Tue-P-1-2-9 (2031) Implementation of Digital Hearing Aid as a Smartphone Application
- Tue-P-1-2-10 (1046) Bone-Conduction Sensor Assisted Noise Estimation for Improved Speech Enhancement
- Tue-P-1-2-11 (2213) Artificial Bandwidth Extension with Memory Inclusion Using Semi-supervised Stacked Auto-encoders
- Tue-P-1-2-12 (2383) Large Vocabulary Concatenative Resynthesis
- Tue-P-1-2-13 (2439) Concatenative Resynthesis with Improved Training Signals for Speech Enhancement
- Tue-P-1-3-1 (1047) Comparison of Syllabification Algorithms and Training Strategies for Robust Word Count Estimation across Different Languages and Recording Conditions
- Tue-P-1-3-2 (1115) A Comparison of Input Types to a Deep Neural Network-based Forced Aligner
- Tue-P-1-3-3 (1151) Joint Learning Using Denoising Variational Autoencoders for Voice Activity Detection
- Tue-P-1-3-4 (1203) Information Bottleneck Based Percussion Instrument Diarization System for Taniavartanam Segments of Carnatic Music Concerts
- Tue-P-1-3-5 (1431) Robust Voice Activity Detection Using Frequency Domain Long-Term Differential Entropy
- Tue-P-1-3-6 (1531) Device-directed Utterance Detection
- Tue-P-1-3-7 (1692) Acoustic-Prosodic Features of Tabla Bol Recitation and Correspondence with the Tabla Imitation
- Tue-P-1-3-8 (1807) Who Said That? a Comparative Study of Non-negative Matrix Factorization Techniques
- Tue-P-1-3-9 (2028) AVA-Speech: a Densely Labeled Dataset of Speech Activity in Movies
- Tue-P-1-3-10 (2490) Audiovisual Speech Activity Detection with Advanced Long Short-Term Memory
- Tue-P-1-3-11 (2537) Towards Automatic Speech Identification from Vocal Tract Shape Dynamics in Real-time MRI
- Tue-P-1-3-2 (1115) A Comparison of Input Types to a Deep Neural Network-based Forced Aligner
- Tue-P-1-3-3 (1151) Joint Learning Using Denoising Variational Autoencoders for Voice Activity Detection
- Tue-P-1-3-4 (1203) Information Bottleneck Based Percussion Instrument Diarization System for Taniavartanam Segments of Carnatic Music Concerts
- Tue-P-1-3-5 (1431) Robust Voice Activity Detection Using Frequency Domain Long-Term Differential Entropy
- Tue-P-1-3-6 (1531) Device-directed Utterance Detection
- Tue-P-1-3-7 (1692) Acoustic-Prosodic Features of Tabla Bol Recitation and Correspondence with the Tabla Imitation
- Tue-P-1-3-8 (1807) Who Said That? a Comparative Study of Non-negative Matrix Factorization Techniques
- Tue-P-1-3-9 (2028) AVA-Speech: a Densely Labeled Dataset of Speech Activity in Movies
- Tue-P-1-3-10 (2490) Audiovisual Speech Activity Detection with Advanced Long Short-Term Memory
- Tue-P-1-3-11 (2537) Towards Automatic Speech Identification from Vocal Tract Shape Dynamics in Real-time MRI
- Tue-P-1-4-1 (1057) Structured Word Embedding for Low Memory Neural Network Language Model
- Tue-P-1-4-2 (2185) Role Play Dialogue Aware Language Models Based on Conditional Hierarchical Recurrent Encoder-Decoder
- Tue-P-1-4-3 (1979) Efficient Keyword Spotting Using Time Delay Neural Networks
- Tue-P-1-4-4 (2062) Automatic DNN Node Pruning Using Mixture Distribution-based Group Regularization
- Tue-P-1-4-5 (2195) Conditional Computation-Based Recurrent Neural Networks for Computationally Efficient Acoustic Modelling
- Tue-P-1-4-6 (2162) Leveraging Translations for Speech Transcription in Low-resource Settings
- Tue-P-1-4-7 (1381) Sequence-to-sequence Neural Network Model with 2D Attention for Learning Japanese Pitch Accents
- Tue-P-1-4-8 (2211) Task Specific Sentence Embeddings for ASR Error Detection
- Tue-P-1-4-9 (1055) Low-Latency Neural Speech Translation
- Tue-P-1-4-10 (1326) Low-Resource Speech-to-Text Translation
- Tue-P-1-4-11 (2032) VoiceGuard: Secure and Private Speech Processing
- Tue-P-1-4-2 (2185) Role Play Dialogue Aware Language Models Based on Conditional Hierarchical Recurrent Encoder-Decoder
- Tue-P-1-4-3 (1979) Efficient Keyword Spotting Using Time Delay Neural Networks
- Tue-P-1-4-4 (2062) Automatic DNN Node Pruning Using Mixture Distribution-based Group Regularization
- Tue-P-1-4-5 (2195) Conditional Computation-Based Recurrent Neural Networks for Computationally Efficient Acoustic Modelling
- Tue-P-1-4-6 (2162) Leveraging Translations for Speech Transcription in Low-resource Settings
- Tue-P-1-4-7 (1381) Sequence-to-sequence Neural Network Model with 2D Attention for Learning Japanese Pitch Accents
- Tue-P-1-4-8 (2211) Task Specific Sentence Embeddings for ASR Error Detection
- Tue-P-1-4-9 (1055) Low-Latency Neural Speech Translation
- Tue-P-1-4-10 (1326) Low-Resource Speech-to-Text Translation
- Tue-P-1-4-11 (2032) VoiceGuard: Secure and Private Speech Processing
- Tue-O-2-1-1 (1234) Single-channel Speech Dereverberation via Generative Adversarial Training
- Tue-O-2-1-2 (1296) Single-Channel Dereverberation Using Direct MMSE Optimization and Bidirectional LSTM Networks
- Tue-O-2-1-3 (1660) Single-channel Late Reverberation Power Spectral Density Estimation Using Denoising Autoencoders
- Tue-O-2-1-4 (1834) A Non-convolutive NMF Model for Speech Dereverberation
- Tue-O-2-1-5 (2238) Cross-Corpora Convolutional Deep Neural Network Dereverberation Preprocessing for Speaker Verification and Speech Enhancement
- Tue-O-2-1-6 (2306) Dereverberation and Beamforming in Robust Far-Field Speaker Recognition
- Tue-O-2-1-2 (1296) Single-Channel Dereverberation Using Direct MMSE Optimization and Bidirectional LSTM Networks
- Tue-O-2-1-3 (1660) Single-channel Late Reverberation Power Spectral Density Estimation Using Denoising Autoencoders
- Tue-O-2-1-4 (1834) A Non-convolutive NMF Model for Speech Dereverberation
- Tue-O-2-1-5 (2238) Cross-Corpora Convolutional Deep Neural Network Dereverberation Preprocessing for Speaker Verification and Speech Enhancement
- Tue-O-2-1-6 (2306) Dereverberation and Beamforming in Robust Far-Field Speaker Recognition
- Tue-O-2-2-1 (990) Comparing the Max and Noisy-Or Pooling Functions in Multiple Instance Learning for Weakly Supervised Sequence Learning Tasks
- Tue-O-2-2-2 (2338) A Simple Model for Detection of Rare Sound Events
- Tue-O-2-2-3 (1152) Temporal Transformer Networks for Acoustic Scene Classification
- Tue-O-2-2-4 (1552) Temporal Attentive Pooling for Acoustic Event Detection
- Tue-O-2-2-5 (2323) R-CRNN: Region-based Convolutional Recurrent Neural Network for Audio Event Detection
- Tue-O-2-2-6 (2559) Detecting Media Sound Presence in Acoustic Scenes
- Tue-O-2-2-2 (2338) A Simple Model for Detection of Rare Sound Events
- Tue-O-2-2-3 (1152) Temporal Transformer Networks for Acoustic Scene Classification
- Tue-O-2-2-4 (1552) Temporal Attentive Pooling for Acoustic Event Detection
- Tue-O-2-2-5 (2323) R-CRNN: Region-based Convolutional Recurrent Neural Network for Audio Event Detection
- Tue-O-2-2-6 (2559) Detecting Media Sound Presence in Acoustic Scenes
- Tue-O-2-3-1 (1232) S4D: Speaker Diarization Toolkit in Python
- Tue-O-2-3-2 (1364) Multimodal Speaker Segmentation and Diarization Using Lexical and Acoustic Cues via Sequence to Sequence Neural Networks
- Tue-O-2-3-3 (1654) Combined Speaker Clustering and Role Recognition in Conversational Speech
- Tue-O-2-3-4 (2324) The ACLEW DiViMe: an Easy-to-use Diarization Tool
- Tue-O-2-3-5 (1878) Automatic Detection of Multi-speaker Fragments with High Time Resolution
- Tue-O-2-3-6 (1750) Neural Speech Turn Segmentation and Affinity Propagation for Speaker Diarization
- Tue-O-2-3-2 (1364) Multimodal Speaker Segmentation and Diarization Using Lexical and Acoustic Cues via Sequence to Sequence Neural Networks
- Tue-O-2-3-3 (1654) Combined Speaker Clustering and Role Recognition in Conversational Speech
- Tue-O-2-3-4 (2324) The ACLEW DiViMe: an Easy-to-use Diarization Tool
- Tue-O-2-3-5 (1878) Automatic Detection of Multi-speaker Fragments with High Time Resolution
- Tue-O-2-3-6 (1750) Neural Speech Turn Segmentation and Affinity Propagation for Speaker Diarization
- Tue-O-2-4-1 (1638) Pitch or Phonation: on the Glottalization in Tone Productions in the Ruokeng Hui Chinese Dialect
- Tue-O-2-4-2 (2288) Speaker-specific Structure in German Voiceless Stop Voice Onset Times
- Tue-O-2-4-3 (2165) Creak in the Respiratory Cycle
- Tue-O-2-4-4 (2598) Acoustic Analysis of Whispery Voice Disguise in Mandarin Chinese
- Tue-O-2-4-5 (1542) The Zurich Corpus of Vowel and Voice Quality, Version 1.0
- Tue-O-2-4-6 (1677) Weighting of Coda Voicing Cues: Glottalisation and Vowel Duration
- Tue-O-2-4-2 (2288) Speaker-specific Structure in German Voiceless Stop Voice Onset Times
- Tue-O-2-4-3 (2165) Creak in the Respiratory Cycle
- Tue-O-2-4-4 (2598) Acoustic Analysis of Whispery Voice Disguise in Mandarin Chinese
- Tue-O-2-4-5 (1542) The Zurich Corpus of Vowel and Voice Quality, Version 1.0
- Tue-O-2-4-6 (1677) Weighting of Coda Voicing Cues: Glottalisation and Vowel Duration
- Tue-O-2-5-1 (1908) Revealing Spatiotemporal Brain Dynamics of Speech Production Based on EEG and Eye Movement
- Tue-O-2-5-2 (2072) Neural Response Development During Distributional Learning
- Tue-O-2-5-3 (2130) Learning Two Tone Languages Enhances the Brainstem Encoding of Lexical Tones
- Tue-O-2-5-4 (2505) Perceptual Sensitivity to Spectral Change in Australian English Close Front Vowels: an Electroencephalographic Investigation
- Tue-O-2-5-5 (1024) Effective Acoustic Cue Learning Is Not Just Statistical, It Is Discriminative
- Tue-O-2-5-6 (1676) Analyzing EEG Signals in Auditory Speech Comprehension Using Temporal Response Functions and Generalized Additive Models
- Tue-O-2-5-2 (2072) Neural Response Development During Distributional Learning
- Tue-O-2-5-3 (2130) Learning Two Tone Languages Enhances the Brainstem Encoding of Lexical Tones
- Tue-O-2-5-4 (2505) Perceptual Sensitivity to Spectral Change in Australian English Close Front Vowels: an Electroencephalographic Investigation
- Tue-O-2-5-5 (1024) Effective Acoustic Cue Learning Is Not Just Statistical, It Is Discriminative
- Tue-O-2-5-6 (1676) Analyzing EEG Signals in Auditory Speech Comprehension Using Temporal Response Functions and Generalized Additive Models
- Tue-SS-2-1-1 (1896) Information Encoding by Deep Neural Networks: What Can We Learn?
- Tue-SS-2-1-2 (1034) Scalable Factorized Hierarchical Variational Autoencoder Training
- Tue-SS-2-1-3 (1153) State Gradients for RNN Memory Analysis
- Tue-SS-2-1-4 (2462) Exploring How Phone Classification Neural Networks Learn Phonetic Information by Visualising and Interpreting Bottleneck Features
- Tue-SS-2-1-5 (2082) Memory Time Span in LSTMs for Multi-Speaker Source Separation
- Tue-SS-2-1-6 (1707) Visualizing Phoneme Category Adaptation in Deep Neural Networks
- Tue-SS-2-1-2 (1034) Scalable Factorized Hierarchical Variational Autoencoder Training
- Tue-SS-2-1-3 (1153) State Gradients for RNN Memory Analysis
- Tue-SS-2-1-4 (2462) Exploring How Phone Classification Neural Networks Learn Phonetic Information by Visualising and Interpreting Bottleneck Features
- Tue-SS-2-1-5 (2082) Memory Time Span in LSTMs for Multi-Speaker Source Separation
- Tue-SS-2-1-6 (1707) Visualizing Phoneme Category Adaptation in Deep Neural Networks
- Tue-S&T-2-1-1 (3022) Early vocabulary development through picture-based software solutions
- Tue-S&T-2-1-2 (3026) Automatic detection of expressiveness in oral reading
- Tue-S&T-2-1-3 (3027) PannoMulloKathan: Voice enabled Mobile App for Agricultural Commodity Price Dissemination in Bengali Language
- Tue-S&T-2-1-4 (3028) Visualizing Punctuation Restoration in Speech Transcripts with Prosograph
- Tue-S&T-2-1-5 (3029) CACTAS - Collaborative Audio Categorization and Transcription for ASR Systems
- Tue-S&T-2-1-2 (3026) Automatic detection of expressiveness in oral reading
- Tue-S&T-2-1-3 (3027) PannoMulloKathan: Voice enabled Mobile App for Agricultural Commodity Price Dissemination in Bengali Language
- Tue-S&T-2-1-4 (3028) Visualizing Punctuation Restoration in Speech Transcripts with Prosograph
- Tue-S&T-2-1-5 (3029) CACTAS - Collaborative Audio Categorization and Transcription for ASR Systems
- Tue-P-2-1-1 (2087) FACTS: a Hierarchical Task-based Control Model of Speech Incorporating Sensory Feedback
- Tue-P-2-1-2 (2592) Sensorimotor response to tongue displacement imagery by talkers with Parkinson’s disease
- Tue-P-2-1-3 (1267) Automatic Pronunciation Evaluation of Singing
- Tue-P-2-1-4 (2299) Classification of Nonverbal Human Produced Audio Events: a Pilot Study
- Tue-P-2-1-5 (995) UltraFit: a Speaker-friendly Headset for Ultrasound Recordings in Speech Sciences
- Tue-P-2-1-6 (1038) Articulatory Consequences of Vocal Effort Elicitation Method
- Tue-P-2-1-7 (1233) Age-related Effects on Sensorimotor Control of Speech Production
- Tue-P-2-1-8 (2512) An Ultrasound Study of Gemination in Coronal Stops in Eastern Oromo
- Tue-P-2-1-9 (1646) Processing Transition Regions of Glottal Stop Substituted /S/ for Intelligibility Enhancement of Cleft Palate Speech
- Tue-P-2-1-10 (1907) Reconstructing Neutral Speech from Tracheoesophageal Speech
- Tue-P-2-1-11 (2544) Automatic Evaluation of Soft Articulatory Contact for Stuttering Treatment
- Tue-P-2-1-12 (1575) Korean Singing Voice Synthesis Based on LSTM Recurrent Neural Network
- Tue-P-2-1-13 (60) The Trajectory of Voice Onset Time with Vocal Aging
- Tue-P-2-1-2 (2592) Sensorimotor response to tongue displacement imagery by talkers with Parkinson’s disease
- Tue-P-2-1-3 (1267) Automatic Pronunciation Evaluation of Singing
- Tue-P-2-1-4 (2299) Classification of Nonverbal Human Produced Audio Events: a Pilot Study
- Tue-P-2-1-5 (995) UltraFit: a Speaker-friendly Headset for Ultrasound Recordings in Speech Sciences
- Tue-P-2-1-6 (1038) Articulatory Consequences of Vocal Effort Elicitation Method
- Tue-P-2-1-7 (1233) Age-related Effects on Sensorimotor Control of Speech Production
- Tue-P-2-1-8 (2512) An Ultrasound Study of Gemination in Coronal Stops in Eastern Oromo
- Tue-P-2-1-9 (1646) Processing Transition Regions of Glottal Stop Substituted /S/ for Intelligibility Enhancement of Cleft Palate Speech
- Tue-P-2-1-10 (1907) Reconstructing Neutral Speech from Tracheoesophageal Speech
- Tue-P-2-1-11 (2544) Automatic Evaluation of Soft Articulatory Contact for Stuttering Treatment
- Tue-P-2-1-12 (1575) Korean Singing Voice Synthesis Based on LSTM Recurrent Neural Network
- Tue-P-2-1-13 (60) The Trajectory of Voice Onset Time with Vocal Aging
- Tue-P-2-2-1 (1768) The Fifth `CHiME' Speech Separation and Recognition Challenge: Dataset, Task and Baselines
- Tue-P-2-2-2 (1454) Voices Obscured in Complex Environmental Settings (VOiCES) Corpus
- Tue-P-2-2-3 (1262) Building State-of-the-art Distant Speech Recognition Using the CHiME-4 Challenge with a Setup of Speech Enhancement Baseline
- Tue-P-2-2-4 (1097) Unsupervised Adaptation with Interpretable Disentangled Representations for Distant Conversational Speech Recognition
- Tue-P-2-2-5 (1780) Investigating Generative Adversarial Networks Based Speech Dereverberation for Robust Speech Recognition
- Tue-P-2-2-6 (1547) Monaural Multi-Talker Speech Recognition with Attention Mechanism and Gated Convolutional Networks
- Tue-P-2-2-7 (1721) Weighting Time-Frequency Representation of Speech Using Auditory Saliency for Automatic Speech Recognition
- Tue-P-2-2-8 (1453) Acoustic Modeling from Frequency Domain Representations of Speech
- Tue-P-2-2-9 (1828) Non-Uniform Spectral Smoothing for Robust Children's Speech Recognition
- Tue-P-2-2-10 (1134) Bidirectional Long-Short Term Memory Network-based Estimation of Reliable Spectral Component Locations
- Tue-P-2-2-11 (2156) Speech Emotion Recognition by Combining Amplitude and Phase Information Using Convolutional Neural Network
- Tue-P-2-2-12 (2377) Bubble Cooperative Networks for Identifying Important Speech Cues
- Tue-P-2-2-2 (1454) Voices Obscured in Complex Environmental Settings (VOiCES) Corpus
- Tue-P-2-2-3 (1262) Building State-of-the-art Distant Speech Recognition Using the CHiME-4 Challenge with a Setup of Speech Enhancement Baseline
- Tue-P-2-2-4 (1097) Unsupervised Adaptation with Interpretable Disentangled Representations for Distant Conversational Speech Recognition
- Tue-P-2-2-5 (1780) Investigating Generative Adversarial Networks Based Speech Dereverberation for Robust Speech Recognition
- Tue-P-2-2-6 (1547) Monaural Multi-Talker Speech Recognition with Attention Mechanism and Gated Convolutional Networks
- Tue-P-2-2-7 (1721) Weighting Time-Frequency Representation of Speech Using Auditory Saliency for Automatic Speech Recognition
- Tue-P-2-2-8 (1453) Acoustic Modeling from Frequency Domain Representations of Speech
- Tue-P-2-2-9 (1828) Non-Uniform Spectral Smoothing for Robust Children's Speech Recognition
- Tue-P-2-2-10 (1134) Bidirectional Long-Short Term Memory Network-based Estimation of Reliable Spectral Component Locations
- Tue-P-2-2-11 (2156) Speech Emotion Recognition by Combining Amplitude and Phase Information Using Convolutional Neural Network
- Tue-P-2-2-12 (2377) Bubble Cooperative Networks for Identifying Important Speech Cues
- Tue-P-2-3-1 (34) Real-Time Scoring of an Oral Reading Assessment on Mobile Devices
- Tue-P-2-3-2 (1087) A Deep Learning Approach to Assessing Non-native Pronunciation of English Using Phone Distances
- Tue-P-2-3-3 (1270) Paired Phone-Posteriors Approach to ESL Pronunciation Quality Assessment
- Tue-P-2-3-4 (1350) Investigating the Role of L1 in Automatic Pronunciation Evaluation of L2 Speech
- Tue-P-2-3-5 (1312) Impact of ASR Performance on Free Speaking Language Assessment
- Tue-P-2-3-6 (1644) Automatic Miscue Detection Using RNN Based Models with Data Augmentation
- Tue-P-2-3-7 (1860) A Study of Objective Measurement of Comprehensibility through Native Speakers' Shadowing of Learners' Utterances
- Tue-P-2-3-8 (2138) Factorized Deep Neural Network Adaptation for Automatic Scoring of L2 Speech in English Speaking Tests
- Tue-P-2-3-9 (2297) On the Difficulties of Automatic Speech Recognition for Kindergarten-Aged Children
- Tue-P-2-3-10 (2118) Improved Acoustic Modelling for Automatic Literacy Assessment of Children
- Tue-P-2-3-2 (1087) A Deep Learning Approach to Assessing Non-native Pronunciation of English Using Phone Distances
- Tue-P-2-3-3 (1270) Paired Phone-Posteriors Approach to ESL Pronunciation Quality Assessment
- Tue-P-2-3-4 (1350) Investigating the Role of L1 in Automatic Pronunciation Evaluation of L2 Speech
- Tue-P-2-3-5 (1312) Impact of ASR Performance on Free Speaking Language Assessment
- Tue-P-2-3-6 (1644) Automatic Miscue Detection Using RNN Based Models with Data Augmentation
- Tue-P-2-3-7 (1860) A Study of Objective Measurement of Comprehensibility through Native Speakers' Shadowing of Learners' Utterances
- Tue-P-2-3-8 (2138) Factorized Deep Neural Network Adaptation for Automatic Scoring of L2 Speech in English Speaking Tests
- Tue-P-2-3-9 (2297) On the Difficulties of Automatic Speech Recognition for Kindergarten-Aged Children
- Tue-P-2-3-10 (2118) Improved Acoustic Modelling for Automatic Literacy Assessment of Children
- Tue-SS-2-2-1 (1319) Anomaly Detection Approach for Pronunciation Verification of Disordered Speech Using Speech Attribute Features
- Tue-SS-2-2-2 (1399) Effectiveness of Voice Quality Features in Detecting Depression
- Tue-SS-2-2-3 (1465) Fusing Text-dependent Word-level i-Vector Models to Screen ‘at Risk’ Child Speech
- Tue-SS-2-2-4 (1471) Testing Paradigms for Assistive Hearing Devices in Diverse Acoustic Environments
- Tue-SS-2-2-5 (1514) Detection of Dementia from Responses to Atypical Questions Asked by Embodied Conversational Agents
- Tue-SS-2-2-6 (1521) Acoustic Features Associated with Sustained Vowel and Continuous Speech Productions by Chinese Children with Functional Articulation Disorders
- Tue-SS-2-2-7 (1631) Estimation of Hypernasality Scores from Cleft Lip and Palate Speech
- Tue-SS-2-2-8 (1713) Detecting Alzheimer’s Disease Using Gated Convolutional Neural Network from Audio Data
- Tue-SS-2-2-9 (2475) Automatic Detection of Orofacial Impairment in Stroke
- Tue-SS-2-2-10 (2522) Detecting Depression with Audio/Text Sequence Modeling of Interviews
- Tue-SS-2-2-2 (1399) Effectiveness of Voice Quality Features in Detecting Depression
- Tue-SS-2-2-3 (1465) Fusing Text-dependent Word-level i-Vector Models to Screen ‘at Risk’ Child Speech
- Tue-SS-2-2-4 (1471) Testing Paradigms for Assistive Hearing Devices in Diverse Acoustic Environments
- Tue-SS-2-2-5 (1514) Detection of Dementia from Responses to Atypical Questions Asked by Embodied Conversational Agents
- Tue-SS-2-2-6 (1521) Acoustic Features Associated with Sustained Vowel and Continuous Speech Productions by Chinese Children with Functional Articulation Disorders
- Tue-SS-2-2-7 (1631) Estimation of Hypernasality Scores from Cleft Lip and Palate Speech
- Tue-SS-2-2-8 (1713) Detecting Alzheimer’s Disease Using Gated Convolutional Neural Network from Audio Data
- Tue-SS-2-2-9 (2475) Automatic Detection of Orofacial Impairment in Stroke
- Tue-SS-2-2-10 (2522) Detecting Depression with Audio/Text Sequence Modeling of Interviews
- Tue-P-2-5-1 (2129) Discourse Marker Detection for Hesitation Events on Mandarin Conversation
- Tue-P-2-5-2 (2225) Acoustic and Perceptual Characteristics of Mandarin Speech in Homosexual and Heterosexual Male Speakers
- Tue-P-2-5-3 (1755) Automatic Question Detection from Acoustic and Phonetic Features Using Feature-wise Pre-training
- Tue-P-2-5-4 (2310) Improving Response Time of Active Speaker Detection Using Visual Prosody Information Prior to Articulation
- Tue-P-2-5-5 (2215) Audio-Visual Prediction of Head-Nod and Turn-Taking Events in Dyadic Interactions
- Tue-P-2-5-6 (1425) Analyzing Effect of Physical Expression on English Proficiency for Multimodal Computer-Assisted Language Learning
- Tue-P-2-5-7 (2090) Analysis of the Effect of Speech-Laugh on Speaker Recognition System
- Tue-P-2-5-8 (2418) Vocal Biomarkers for Cognitive Performance Estimation in a Working Memory Task
- Tue-P-2-5-9 (2263) Lexical and Acoustic Deep Learning Model for Personality Recognition
- Tue-P-2-5-2 (2225) Acoustic and Perceptual Characteristics of Mandarin Speech in Homosexual and Heterosexual Male Speakers
- Tue-P-2-5-3 (1755) Automatic Question Detection from Acoustic and Phonetic Features Using Feature-wise Pre-training
- Tue-P-2-5-4 (2310) Improving Response Time of Active Speaker Detection Using Visual Prosody Information Prior to Articulation
- Tue-P-2-5-5 (2215) Audio-Visual Prediction of Head-Nod and Turn-Taking Events in Dyadic Interactions
- Tue-P-2-5-6 (1425) Analyzing Effect of Physical Expression on English Proficiency for Multimodal Computer-Assisted Language Learning
- Tue-P-2-5-7 (2090) Analysis of the Effect of Speech-Laugh on Speaker Recognition System
- Tue-P-2-5-8 (2418) Vocal Biomarkers for Cognitive Performance Estimation in a Working Memory Task
- Tue-P-2-5-9 (2263) Lexical and Acoustic Deep Learning Model for Personality Recognition
- Wed-O-1-1-1 (1485) Layer Trajectory LSTM
- Wed-O-1-1-2 (2158) Semi-tied Units for Efficient Gating in LSTM and Highway Networks
- Wed-O-1-1-3 (1823) Gaussian Process Neural Networks for Speech Recognition
- Wed-O-1-1-4 (1089) Acoustic Modeling with Densely Connected Residual Network for Multichannel Speech Recognition
- Wed-O-1-1-5 (1544) Gated Recurrent Unit Based Acoustic Modeling with Future Context
- Wed-O-1-1-6 (1403) Output-Gate Projected Gated Recurrent Unit for Speech Recognition
- Wed-O-1-1-2 (2158) Semi-tied Units for Efficient Gating in LSTM and Highway Networks
- Wed-O-1-1-3 (1823) Gaussian Process Neural Networks for Speech Recognition
- Wed-O-1-1-4 (1089) Acoustic Modeling with Densely Connected Residual Network for Multichannel Speech Recognition
- Wed-O-1-1-5 (1544) Gated Recurrent Unit Based Acoustic Modeling with Future Context
- Wed-O-1-1-6 (1403) Output-Gate Projected Gated Recurrent Unit for Speech Recognition
- Wed-O-1-2-1 (69) Performance Analysis of the 2017 NIST Language Recognition Evaluation
- Wed-O-1-2-2 (1165) Using Deep Neural Networks for Identification of Slavic Languages from Acoustic Signal
- Wed-O-1-2-3 (1342) Adding New Classes without Access to the Original Training Data with Applications to Language Identification
- Wed-O-1-2-4 (1519) Feature Representation of Short Utterances Based on Knowledge Distillation for Spoken Language Identification
- Wed-O-1-2-5 (1805) Sub-band Envelope Features Using Frequency Domain Linear Prediction for Short Duration Language Identification
- Wed-O-1-2-6 (2458) Effectiveness of Single-Channel BLSTM Enhancement for Language Identification
- Wed-O-1-2-2 (1165) Using Deep Neural Networks for Identification of Slavic Languages from Acoustic Signal
- Wed-O-1-2-3 (1342) Adding New Classes without Access to the Original Training Data with Applications to Language Identification
- Wed-O-1-2-4 (1519) Feature Representation of Short Utterances Based on Knowledge Distillation for Spoken Language Identification
- Wed-O-1-2-5 (1805) Sub-band Envelope Features Using Frequency Domain Linear Prediction for Short Duration Language Identification
- Wed-O-1-2-6 (2458) Effectiveness of Single-Channel BLSTM Enhancement for Language Identification
- Wed-O-1-3-1 (1384) Articulation Rate as a Speaker Discriminant in British English
- Wed-O-1-3-2 (2513) Truncation and Compression in Southern German and Australian English
- Wed-O-1-3-3 (1873) Prominence-based Evaluation of L2 Prosody
- Wed-O-1-3-4 (1060) Length Contrast and Covarying Features: Whistled Speech as a Case Study
- Wed-O-1-3-5 (1529) Information Structure, Affect, and Prenuclear Prominence in American English
- Wed-O-1-3-6 (63) Effects of User Controlled Speech Rate on Intelligibility in Noisy Environments
- Wed-O-1-3-2 (2513) Truncation and Compression in Southern German and Australian English
- Wed-O-1-3-3 (1873) Prominence-based Evaluation of L2 Prosody
- Wed-O-1-3-4 (1060) Length Contrast and Covarying Features: Whistled Speech as a Case Study
- Wed-O-1-3-5 (1529) Information Structure, Affect, and Prenuclear Prominence in American English
- Wed-O-1-3-6 (63) Effects of User Controlled Speech Rate on Intelligibility in Noisy Environments
- Wed-O-1-4-1 (27) Binaural Speech Intelligibility Estimation Using Deep Neural Networks
- Wed-O-1-4-2 (1291) Multi-resolution Gammachirp Envelope Distortion Index for Intelligibility Prediction of Noisy Speech
- Wed-O-1-4-3 (2119) Speech Intelligibility Enhancement Based on a Non-causal Wavenet-like Model
- Wed-O-1-4-4 (1802) Quality-Net: an End-to-End Non-intrusive Speech Quality Assessment Model Based on BLSTM
- Wed-O-1-4-5 (1884) Global Snr Estimation of Speech Signals Using Entropy and Uncertainty Estimates from Dropout Networks
- Wed-O-1-4-6 (1098) Detecting Packet-Loss Concealment Using Formant Features and Decision Tree Learning
- Wed-O-1-4-2 (1291) Multi-resolution Gammachirp Envelope Distortion Index for Intelligibility Prediction of Noisy Speech
- Wed-O-1-4-3 (2119) Speech Intelligibility Enhancement Based on a Non-causal Wavenet-like Model
- Wed-O-1-4-4 (1802) Quality-Net: an End-to-End Non-intrusive Speech Quality Assessment Model Based on BLSTM
- Wed-O-1-4-5 (1884) Global Snr Estimation of Speech Signals Using Entropy and Uncertainty Estimates from Dropout Networks
- Wed-O-1-4-6 (1098) Detecting Packet-Loss Concealment Using Formant Features and Decision Tree Learning
- Wed-SS-1-1-1 (1736) UltraSuite: a Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions
- Wed-SS-1-1-2 (1764) Detecting Signs of Dementia Using Word Vector Representations
- Wed-SS-1-1-3 (2029) Classification of Huntington Disease Using Acoustic and Lexical Features
- Wed-SS-1-1-4 (2355) The PRIORI Emotion Dataset: Linking Mood to Emotion Detected In-the-Wild
- Wed-SS-1-1-5 (1518) Language Features for Automated Evaluation of Cognitive Behavior Psychotherapy Sessions
- Wed-SS-1-1-6 (2496) Automatic Early Detection of Amyotrophic Lateral Sclerosis from Intelligible Speech Using Convolutional Neural Networks
- Wed-SS-1-1-2 (1764) Detecting Signs of Dementia Using Word Vector Representations
- Wed-SS-1-1-3 (2029) Classification of Huntington Disease Using Acoustic and Lexical Features
- Wed-SS-1-1-4 (2355) The PRIORI Emotion Dataset: Linking Mood to Emotion Detected In-the-Wild
- Wed-SS-1-1-5 (1518) Language Features for Automated Evaluation of Cognitive Behavior Psychotherapy Sessions
- Wed-SS-1-1-6 (2496) Automatic Early Detection of Amyotrophic Lateral Sclerosis from Intelligible Speech Using Convolutional Neural Networks
- Wed-SS-1-2-1 (1600) A Study of Lexical and Prosodic Cues to Segmentation in a Hindi-English Code-switched Discourse
- Wed-SS-1-2-2 (1966) Building a Unified Code-Switching ASR System for South African Languages
- Wed-SS-1-2-3 (1974) Study of Semi-supervised Approaches to Improving English-Mandarin Code-Switching Speech Recognition
- Wed-SS-1-2-4 (52) Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
- Wed-SS-1-2-5 (1099) The Role of Cognate Words, POS Tags, and Entrainment in Code-Switching
- Wed-SS-1-2-6 (1171) Homophone Identification and Merging for Code-switched Speech Recognition
- Wed-SS-1-2-7 (1178) Code-switching in Indic Speech Synthesisers
- Wed-SS-1-2-8 (1259) A Novel Approach for Effective Recognition of the Code-Switched Data on Monolingual Language Model
- Wed-SS-1-2-2 (1966) Building a Unified Code-Switching ASR System for South African Languages
- Wed-SS-1-2-3 (1974) Study of Semi-supervised Approaches to Improving English-Mandarin Code-Switching Speech Recognition
- Wed-SS-1-2-4 (52) Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
- Wed-SS-1-2-5 (1099) The Role of Cognate Words, POS Tags, and Entrainment in Code-Switching
- Wed-SS-1-2-6 (1171) Homophone Identification and Merging for Code-switched Speech Recognition
- Wed-SS-1-2-7 (1178) Code-switching in Indic Speech Synthesisers
- Wed-SS-1-2-8 (1259) A Novel Approach for Effective Recognition of the Code-Switched Data on Monolingual Language Model
- Wed-S&T-1-1-1 (3030) Hierarchical Accent Determination and Application in a Large Scale ASR System
- Wed-S&T-1-1-2 (3032) Toward Scalable Dialog Technology for Conversational Language Learning: Case Study of the TOEFL MOOC
- Wed-S&T-1-1-3 (3033) Machine Learning powered Data Platform for High-Quality Speech and NLP workflows
- Wed-S&T-1-1-4 (3034) Fully automatic speaker separation system, with automatic enrolling of recurrent speakers
- Wed-S&T-1-1-5 (3035) Online speech translation system for Tamil
- Wed-S&T-1-1-2 (3032) Toward Scalable Dialog Technology for Conversational Language Learning: Case Study of the TOEFL MOOC
- Wed-S&T-1-1-3 (3033) Machine Learning powered Data Platform for High-Quality Speech and NLP workflows
- Wed-S&T-1-1-4 (3034) Fully automatic speaker separation system, with automatic enrolling of recurrent speakers
- Wed-S&T-1-1-5 (3035) Online speech translation system for Tamil
- Wed-P-1-1-1 (1712) Unsupervised Vocal Tract Length Warped Posterior Features for Non-Parallel Voice Conversion
- Wed-P-1-1-2 (1121) Voice Conversion with Conditional SampleRNN
- Wed-P-1-1-3 (1131) A Voice Conversion Framework with Tandem Feature Sparse Representation and Speaker-Adapted WaveNet Vocoder
- Wed-P-1-1-4 (1190) WaveNet Vocoder with Limited Training Data for Voice Conversion
- Wed-P-1-1-5 (1210) Collapsed Speech Segment Detection and Suppression for WaveNet Vocoder
- Wed-P-1-1-6 (1528) High-quality Voice Conversion Using Spectrogram-Based WaveNet Vocoder
- Wed-P-1-1-7 (2417) Spanish Statistical Parametric Speech Synthesis Using a Neural Vocoder
- Wed-P-1-1-8 (2400) Experiments with Training Corpora for Statistical Text-to-speech Systems.
- Wed-P-1-1-9 (1506) Multi-task WaveNet: a Multi-task Generative Model for Statistical Parametric Speech Synthesis without Fundamental Frequency Conditions
- Wed-P-1-1-10 (1635) Speaker-independent Raw Waveform Model for Glottal Excitation
- Wed-P-1-1-11 (1757) A New Glottal Neural Vocoder for Speech Synthesis
- Wed-P-1-1-12 (1857) Exemplar-based Speech Waveform Generation
- Wed-P-1-1-13 (43) Frequency Domain Variants of Velvet Noise and Their Application to Speech Processing and Synthesis
- Wed-P-1-1-2 (1121) Voice Conversion with Conditional SampleRNN
- Wed-P-1-1-3 (1131) A Voice Conversion Framework with Tandem Feature Sparse Representation and Speaker-Adapted WaveNet Vocoder
- Wed-P-1-1-4 (1190) WaveNet Vocoder with Limited Training Data for Voice Conversion
- Wed-P-1-1-5 (1210) Collapsed Speech Segment Detection and Suppression for WaveNet Vocoder
- Wed-P-1-1-6 (1528) High-quality Voice Conversion Using Spectrogram-Based WaveNet Vocoder
- Wed-P-1-1-7 (2417) Spanish Statistical Parametric Speech Synthesis Using a Neural Vocoder
- Wed-P-1-1-8 (2400) Experiments with Training Corpora for Statistical Text-to-speech Systems.
- Wed-P-1-1-9 (1506) Multi-task WaveNet: a Multi-task Generative Model for Statistical Parametric Speech Synthesis without Fundamental Frequency Conditions
- Wed-P-1-1-10 (1635) Speaker-independent Raw Waveform Model for Glottal Excitation
- Wed-P-1-1-11 (1757) A New Glottal Neural Vocoder for Speech Synthesis
- Wed-P-1-1-12 (1857) Exemplar-based Speech Waveform Generation
- Wed-P-1-1-13 (43) Frequency Domain Variants of Velvet Noise and Their Application to Speech Processing and Synthesis
- Wed-P-1-2-1 (1346) Joint Learning of Interactive Spoken Content Retrieval and Trainable User Simulator
- Wed-P-1-2-2 (1777) Attention-based End-to-End Models for Small-Footprint Keyword Spotting
- Wed-P-1-2-3 (991) Prediction of Aesthetic Elements in Karnatic Music: a Machine Learning Approach
- Wed-P-1-2-4 (1283) Topic and Keyword Identification for Low-resourced Speech Using Cross-Language Transfer Learning
- Wed-P-1-2-5 (1836) Automatic Speech Recognition and Topic Identification from Speech for Almost-Zero-Resource Languages
- Wed-P-1-2-6 (1100) Play Duration Based User-Entity Affinity Modeling in Spoken Dialog System
- Wed-P-1-2-7 (1776) Empirical Analysis of Score Fusion Application to Combined Neural Networks for Open Vocabulary Spoken Term Detection
- Wed-P-1-2-8 (1973) Phonological Posterior Hashing for Query by Example Spoken Term Detection
- Wed-P-1-2-9 (2017) Term Extraction via Neural Sequence Labeling a Comparative Evaluation of Strategies Using Recurrent Neural Networks
- Wed-P-1-2-10 (1318) Semi-supervised Learning for Information Extraction from Dialogue
- Wed-P-1-2-11 (1808) Slot Filling with Delexicalized Sentence Generation
- Wed-P-1-2-12 (2045) Music Genre Recognition Using Deep Neural Networks and Transfer Learning
- Wed-P-1-2-13 (2204) Efficient Voice Trigger Detection for Low Resource Hardware
- Wed-P-1-2-2 (1777) Attention-based End-to-End Models for Small-Footprint Keyword Spotting
- Wed-P-1-2-3 (991) Prediction of Aesthetic Elements in Karnatic Music: a Machine Learning Approach
- Wed-P-1-2-4 (1283) Topic and Keyword Identification for Low-resourced Speech Using Cross-Language Transfer Learning
- Wed-P-1-2-5 (1836) Automatic Speech Recognition and Topic Identification from Speech for Almost-Zero-Resource Languages
- Wed-P-1-2-6 (1100) Play Duration Based User-Entity Affinity Modeling in Spoken Dialog System
- Wed-P-1-2-7 (1776) Empirical Analysis of Score Fusion Application to Combined Neural Networks for Open Vocabulary Spoken Term Detection
- Wed-P-1-2-8 (1973) Phonological Posterior Hashing for Query by Example Spoken Term Detection
- Wed-P-1-2-9 (2017) Term Extraction via Neural Sequence Labeling a Comparative Evaluation of Strategies Using Recurrent Neural Networks
- Wed-P-1-2-10 (1318) Semi-supervised Learning for Information Extraction from Dialogue
- Wed-P-1-2-11 (1808) Slot Filling with Delexicalized Sentence Generation
- Wed-P-1-2-12 (2045) Music Genre Recognition Using Deep Neural Networks and Transfer Learning
- Wed-P-1-2-13 (2204) Efficient Voice Trigger Detection for Low Resource Hardware
- Wed-P-1-3-1 (45) A Novel Normalization Method for Autocorrelation Function for Pitch Detection and for Speech Activity Detection
- Wed-P-1-3-2 (1105) Estimation of the Vocal Tract Length of Vowel Sounds Based on the Frequency of the Significant Spectral Valley
- Wed-P-1-3-3 (1143) Deep Learning Techniques for Koala Activity Detection
- Wed-P-1-3-4 (1147) Glottal Closure Instant Detection from Speech Signal Using Voting Classifier and Recursive Feature Elimination
- Wed-P-1-3-5 (1463) Assessing Speaker Engagement in 2-Person Debates: Overlap Detection in United States Presidential Debates
- Wed-P-1-3-6 (1522) All-Conv Net for Bird Activity Detection: Significance of Learned Pooling
- Wed-P-1-3-7 (1705) Deep Convex Representations: Feature Representations for Bioacoustics Classification
- Wed-P-1-3-8 (2014) Detection of Glottal Excitation Epochs in Speech Signal Using Hilbert Envelope
- Wed-P-1-3-9 (2115) Analyzing Thai Tone Distribution through Functional Data Analysis
- Wed-P-1-3-10 (2275) Articulatory Feature Classification Using Convolutional Neural Networks
- Wed-P-1-3-11 (2590) A New Frequency Coverage Metric and a New Subband Encoding Model, with an Application in Pitch Estimation
- Wed-P-1-3-12 (1173) Improved Epoch Extraction from Telephonic Speech Using Chebfun and Zero Frequency Filtering
- Wed-P-1-3-2 (1105) Estimation of the Vocal Tract Length of Vowel Sounds Based on the Frequency of the Significant Spectral Valley
- Wed-P-1-3-3 (1143) Deep Learning Techniques for Koala Activity Detection
- Wed-P-1-3-4 (1147) Glottal Closure Instant Detection from Speech Signal Using Voting Classifier and Recursive Feature Elimination
- Wed-P-1-3-5 (1463) Assessing Speaker Engagement in 2-Person Debates: Overlap Detection in United States Presidential Debates
- Wed-P-1-3-6 (1522) All-Conv Net for Bird Activity Detection: Significance of Learned Pooling
- Wed-P-1-3-7 (1705) Deep Convex Representations: Feature Representations for Bioacoustics Classification
- Wed-P-1-3-8 (2014) Detection of Glottal Excitation Epochs in Speech Signal Using Hilbert Envelope
- Wed-P-1-3-9 (2115) Analyzing Thai Tone Distribution through Functional Data Analysis
- Wed-P-1-3-10 (2275) Articulatory Feature Classification Using Convolutional Neural Networks
- Wed-P-1-3-11 (2590) A New Frequency Coverage Metric and a New Subband Encoding Model, with an Application in Pitch Estimation
- Wed-P-1-3-12 (1173) Improved Epoch Extraction from Telephonic Speech Using Chebfun and Zero Frequency Filtering
- Wed-P-1-4-1 (2530) An Empirical Analysis of the Correlation of Syntax and Prosody
- Wed-P-1-4-2 (2533) Analysing the Focus of a Hierarchical Attention Network: the Importance of Enjambments When Classifying Post-modern Poetry
- Wed-P-1-4-3 (1962) Language-Dependent Melody Embeddings
- Wed-P-1-4-4 (1602) Stress Distribution of Given Information in Chinese Reading Texts
- Wed-P-1-4-5 (2366) Acoustic-prosodic Entrainment in Structural Metadata Events
- Wed-P-1-4-6 (1126) Formant Measures of Vowels Adjacent to Alveolar and Retroflex Consonants in Arrernte: Stressed and Unstressed Position
- Wed-P-1-4-7 (1386) Automatic Assessment of L2 English Word Prosody Using Weighted Distances of F0 and Intensity Contours
- Wed-P-1-4-8 (1476) Homogeneity vs Heterogeneity in Indian English: Investigating Influences of L1 on f0 Range
- Wed-P-1-4-9 (91) Emotional Prosody Perception in Mandarin-speaking Congenital Amusics
- Wed-P-1-4-10 (1795) Cultural Differences in Pattern Matching: Multisensory Recognition of Socio-affective Prosody
- Wed-P-1-4-2 (2533) Analysing the Focus of a Hierarchical Attention Network: the Importance of Enjambments When Classifying Post-modern Poetry
- Wed-P-1-4-3 (1962) Language-Dependent Melody Embeddings
- Wed-P-1-4-4 (1602) Stress Distribution of Given Information in Chinese Reading Texts
- Wed-P-1-4-5 (2366) Acoustic-prosodic Entrainment in Structural Metadata Events
- Wed-P-1-4-6 (1126) Formant Measures of Vowels Adjacent to Alveolar and Retroflex Consonants in Arrernte: Stressed and Unstressed Position
- Wed-P-1-4-7 (1386) Automatic Assessment of L2 English Word Prosody Using Weighted Distances of F0 and Intensity Contours
- Wed-P-1-4-8 (1476) Homogeneity vs Heterogeneity in Indian English: Investigating Influences of L1 on f0 Range
- Wed-P-1-4-9 (91) Emotional Prosody Perception in Mandarin-speaking Congenital Amusics
- Wed-P-1-4-10 (1795) Cultural Differences in Pattern Matching: Multisensory Recognition of Socio-affective Prosody
- Wed-O-2-1-1 (1456) ESPnet: End-to-End Speech Processing Toolkit
- Wed-O-2-1-2 (1339) A GPU-based WFST Decoder with Exact Lattice Generation
- Wed-O-2-1-3 (1085) Automatic Speech Recognition System Development in the "Wild"
- Wed-O-2-1-4 (2453) Semantic Lattice Processing in Contextual Automatic Speech Recognition for Google Assistant
- Wed-O-2-1-5 (2416) Contextual Speech Recognition in End-to-end Neural Network Systems Using Beam Search
- Wed-O-2-1-6 (1160) Forward-Backward Attention Decoder
- Wed-O-2-1-2 (1339) A GPU-based WFST Decoder with Exact Lattice Generation
- Wed-O-2-1-3 (1085) Automatic Speech Recognition System Development in the "Wild"
- Wed-O-2-1-4 (2453) Semantic Lattice Processing in Contextual Automatic Speech Recognition for Google Assistant
- Wed-O-2-1-5 (2416) Contextual Speech Recognition in End-to-end Neural Network Systems Using Beam Search
- Wed-O-2-1-6 (1160) Forward-Backward Attention Decoder
- Wed-O-2-2-1 (1015) Learning Discriminative Features for Speaker Identification and Verification
- Wed-O-2-2-2 (1209) Triplet Loss Based Cosine Similarity Metric Learning for Text-independent Speaker Recognition
- Wed-O-2-2-3 (1226) Speaker Embedding Extraction with Phonetic Information
- Wed-O-2-2-4 (993) Attentive Statistics Pooling for Deep Speaker Embedding
- Wed-O-2-2-5 (1685) Robust and Discriminative Speaker Embedding via Intra-Class Distance Variance Regularization
- Wed-O-2-2-6 (1769) Deep Discriminative Embeddings for Duration Robust Speaker Verification
- Wed-O-2-2-2 (1209) Triplet Loss Based Cosine Similarity Metric Learning for Text-independent Speaker Recognition
- Wed-O-2-2-3 (1226) Speaker Embedding Extraction with Phonetic Information
- Wed-O-2-2-4 (993) Attentive Statistics Pooling for Deep Speaker Embedding
- Wed-O-2-2-5 (1685) Robust and Discriminative Speaker Embedding via Intra-Class Distance Variance Regularization
- Wed-O-2-2-6 (1769) Deep Discriminative Embeddings for Duration Robust Speaker Verification
- Wed-O-2-3-1 (1358) Impact of Different Speech Types on Listening Effort
- Wed-O-2-3-2 (2053) Who Are You Listening to? towards a Dynamic Measure of Auditory Attention to Speech-on-speech.
- Wed-O-2-3-3 (1812) Investigating the Role of Familiar Face and Voice Cues in Speech Processing in Noise
- Wed-O-2-3-4 (1088) The Conversation Continues: the Effect of Lyrics and Music Complexity of Background Music on Spoken-Word Recognition
- Wed-O-2-3-5 (2089) Loud and Shouted Speech Perception at Variable Distances in a Forest
- Wed-O-2-3-6 (1271) Phoneme Resistance and Phoneme Confusion in Noise: Impact of Dyslexia
- Wed-O-2-3-2 (2053) Who Are You Listening to? towards a Dynamic Measure of Auditory Attention to Speech-on-speech.
- Wed-O-2-3-3 (1812) Investigating the Role of Familiar Face and Voice Cues in Speech Processing in Noise
- Wed-O-2-3-4 (1088) The Conversation Continues: the Effect of Lyrics and Music Complexity of Background Music on Spoken-Word Recognition
- Wed-O-2-3-5 (2089) Loud and Shouted Speech Perception at Variable Distances in a Forest
- Wed-O-2-3-6 (1271) Phoneme Resistance and Phoneme Confusion in Noise: Impact of Dyslexia
- Wed-O-2-4-1 (38) Conditional End-to-End Audio Transforms
- Wed-O-2-4-2 (1018) Detection of Glottal Closure Instants in Degraded Speech Using Single Frequency Filtering Analysis
- Wed-O-2-4-3 (2293) Tone Recognition Using Lifters and CTC
- Wed-O-2-4-4 (1613) Epoch Extraction from Pathological Children Speech Using Single Pole Filtering Approach
- Wed-O-2-4-5 (1756) Automated Classification of Vowel-Gesture Parameters Using External Broadband Excitation
- Wed-O-2-4-6 (2495) Estimation of Fundamental Frequency from Singing Voice Using Harmonics of Impulse-like Excitation Source
- Wed-O-2-4-2 (1018) Detection of Glottal Closure Instants in Degraded Speech Using Single Frequency Filtering Analysis
- Wed-O-2-4-3 (2293) Tone Recognition Using Lifters and CTC
- Wed-O-2-4-4 (1613) Epoch Extraction from Pathological Children Speech Using Single Pole Filtering Approach
- Wed-O-2-4-5 (1756) Automated Classification of Vowel-Gesture Parameters Using External Broadband Excitation
- Wed-O-2-4-6 (2495) Estimation of Fundamental Frequency from Singing Voice Using Harmonics of Impulse-like Excitation Source
- Wed-O-2-5-1 (57) Investigating the Effect of Audio Duration on Dementia Detection Using Acoustic Features
- Wed-O-2-5-2 (1288) An Interlocutor-Modulated Attentional LSTM for Differentiating between Subgroups of Autism Spectrum Disorder
- Wed-O-2-5-3 (1772) Recognition of Echolalic Autistic Child Vocalisations Utilising Convolutional Recurrent Neural Networks
- Wed-O-2-5-4 (1562) Modeling Interpersonal Influence of Verbal Behavior in Couples Therapy Dyadic Interactions
- Wed-O-2-5-5 (1583) Computational Modeling of Conversational Humor in Psychotherapy
- Wed-O-2-5-6 (2295) Multimodal I-vectors to Detect and Evaluate Parkinson's Disease
- Wed-O-2-5-2 (1288) An Interlocutor-Modulated Attentional LSTM for Differentiating between Subgroups of Autism Spectrum Disorder
- Wed-O-2-5-3 (1772) Recognition of Echolalic Autistic Child Vocalisations Utilising Convolutional Recurrent Neural Networks
- Wed-O-2-5-4 (1562) Modeling Interpersonal Influence of Verbal Behavior in Couples Therapy Dyadic Interactions
- Wed-O-2-5-5 (1583) Computational Modeling of Conversational Humor in Psychotherapy
- Wed-O-2-5-6 (2295) Multimodal I-vectors to Detect and Evaluate Parkinson's Disease
- Wed-SS-2-1-1 (97) Overview of the 2018 Spoken CALL Shared Task
- Wed-SS-2-1-2 (1000) The CSU-K Rule-Based System for the 2Nd Edition Spoken CALL Shared Task
- Wed-SS-2-1-3 (1309) Liulishuo's System for the Spoken CALL Shared Task 2018
- Wed-SS-2-1-4 (1328) An Optimization Based Approach for Solving Spoken CALL Shared Task
- Wed-SS-2-1-5 (1372) The University of Birmingham 2018 Spoken CALL Shared Task Systems
- Wed-SS-2-1-6 (2362) Improvements to an Automated Content Scoring System for Spoken CALL Responses: the ETS Submission to the Second Spoken CALL Shared Task
- Wed-SS-2-1-7 (-) Closing Remarks and General Discussion
- Wed-SS-2-1-2 (1000) The CSU-K Rule-Based System for the 2Nd Edition Spoken CALL Shared Task
- Wed-SS-2-1-3 (1309) Liulishuo's System for the Spoken CALL Shared Task 2018
- Wed-SS-2-1-4 (1328) An Optimization Based Approach for Solving Spoken CALL Shared Task
- Wed-SS-2-1-5 (1372) The University of Birmingham 2018 Spoken CALL Shared Task Systems
- Wed-SS-2-1-6 (2362) Improvements to an Automated Content Scoring System for Spoken CALL Responses: the ETS Submission to the Second Spoken CALL Shared Task
- Wed-SS-2-1-7 (-) Closing Remarks and General Discussion
- Wed-S&T-2-1-1 (3036) Extracting speaker’s gender, accent, age and emotional state from speech
- Wed-S&T-2-1-2 (3042) Determining Speaker Location from Speech in a Practical Environment
- Wed-S&T-2-1-3 (3043) An Automatic Speech Transcription System for Manipuri Language
- Wed-S&T-2-1-4 (3009) SPIRE-SST: An automatic web-based self-learning tool for syllable stress tutoring (SST) to the second language learners
- Wed-S&T-2-1-5 (3046) Glotto Vibrato Graph: A Device and Method for Recording, Analysis and Visualization of Glottal Activity
- Wed-S&T-2-1-2 (3042) Determining Speaker Location from Speech in a Practical Environment
- Wed-S&T-2-1-3 (3043) An Automatic Speech Transcription System for Manipuri Language
- Wed-S&T-2-1-4 (3009) SPIRE-SST: An automatic web-based self-learning tool for syllable stress tutoring (SST) to the second language learners
- Wed-S&T-2-1-5 (3046) Glotto Vibrato Graph: A Device and Method for Recording, Analysis and Visualization of Glottal Activity
- Wed-P-2-1-1 (2456) Multi-Modal Data Augmentation for End-to-end ASR
- Wed-P-2-1-2 (1866) Multi-task Learning with Augmentation Strategy for Acoustic-to-word Attention-based Encoder-decoder Speech Recognition
- Wed-P-2-1-3 (1247) Training Augmentation with Adversarial Examples for Robust Speech Recognition
- Wed-P-2-1-4 (1211) Data Augmentation Improves Recognition of Foreign Accented Speech
- Wed-P-2-1-5 (2209) Speaker Adaptive Training and Mixup Regularization for Neural Network Acoustic Models in Automatic Speech Recognition
- Wed-P-2-1-6 (1241) Neural Language Codes for Multilingual Acoustic Models
- Wed-P-2-1-7 (1424) Encoder Transfer for Attention-based Acoustic-to-word Speech Recognition
- Wed-P-2-1-8 (1897) Empirical Evaluation of Speaker Adaptation on DNN Based Acoustic Model
- Wed-P-2-1-9 (1450) Improving DNNs Trained with Non-Native Transcriptions Using Knowledge Distillation and Target Interpolation
- Wed-P-2-1-10 (1182) Improving Cross-Lingual Knowledge Transferability Using Multilingual TDNN-BLSTM with Language-Dependent Pre-Final Layer
- Wed-P-2-1-11 (1438) Auxiliary Feature Based Adaptation of End-to-end ASR Systems
- Wed-P-2-1-12 (1378) Leveraging Native Language Information for Improved Accented Speech Recognition
- Wed-P-2-1-13 (1864) Improved Accented Speech Recognition Using Accent Embeddings and Multi-task Learning
- Wed-P-2-1-14 (1990) Fast Language Adaptation Using Phonological Information
- Wed-P-2-1-2 (1866) Multi-task Learning with Augmentation Strategy for Acoustic-to-word Attention-based Encoder-decoder Speech Recognition
- Wed-P-2-1-3 (1247) Training Augmentation with Adversarial Examples for Robust Speech Recognition
- Wed-P-2-1-4 (1211) Data Augmentation Improves Recognition of Foreign Accented Speech
- Wed-P-2-1-5 (2209) Speaker Adaptive Training and Mixup Regularization for Neural Network Acoustic Models in Automatic Speech Recognition
- Wed-P-2-1-6 (1241) Neural Language Codes for Multilingual Acoustic Models
- Wed-P-2-1-7 (1424) Encoder Transfer for Attention-based Acoustic-to-word Speech Recognition
- Wed-P-2-1-8 (1897) Empirical Evaluation of Speaker Adaptation on DNN Based Acoustic Model
- Wed-P-2-1-9 (1450) Improving DNNs Trained with Non-Native Transcriptions Using Knowledge Distillation and Target Interpolation
- Wed-P-2-1-10 (1182) Improving Cross-Lingual Knowledge Transferability Using Multilingual TDNN-BLSTM with Language-Dependent Pre-Final Layer
- Wed-P-2-1-11 (1438) Auxiliary Feature Based Adaptation of End-to-end ASR Systems
- Wed-P-2-1-12 (1378) Leveraging Native Language Information for Improved Accented Speech Recognition
- Wed-P-2-1-13 (1864) Improved Accented Speech Recognition Using Accent Embeddings and Multi-task Learning
- Wed-P-2-1-14 (1990) Fast Language Adaptation Using Phonological Information
- Wed-P-2-2-1 (1239) Naturalness Improvement Algorithm for Reconstructed Glossectomy Patient's Speech Using Spectral Differential Modification in Voice Conversion
- Wed-P-2-2-2 (2286) Audio-visual Voice Conversion Using Deep Canonical Correlation Analysis for Deep Bottleneck Features
- Wed-P-2-2-3 (1869) An Investigation of Convolution Attention Based Models for Multilingual Speech Synthesis of Indian Languages
- Wed-P-2-2-4 (2066) The Effect of Real-Time Constraints on Automatic Speech Animation
- Wed-P-2-2-5 (2587) Joint Learning of Facial Expression and Head Pose from Speech
- Wed-P-2-2-6 (1306) Acoustic-dependent Phonemic Transcription for Text-to-speech Synthesis
- Wed-P-2-2-7 (1791) Multimodal Speech Synthesis Architecture for Unsupervised Speaker Adaptation
- Wed-P-2-2-8 (999) Articulatory-to-speech Conversion Using Bi-directional Long Short-term Memory
- Wed-P-2-2-9 (1080) Implementation of Respiration in Articulatory Synthesis Using a Pressure-Volume Lung Model
- Wed-P-2-2-10 (1198) Learning and Modeling Unit Embeddings for Improving HMM-based Unit Selection Speech Synthesis
- Wed-P-2-2-11 (1305) Deep Metric Learning for the Target Cost in Unit-Selection Speech Synthesizer
- Wed-P-2-2-12 (1460) DNN-based Speech Synthesis for Small Data Sets Considering Bidirectional Speech-Text Conversion
- Wed-P-2-2-13 (1286) A Weighted Superposition of Functional Contours Model for Modelling Contextual Prominence of Elementary Prosodic Contours
- Wed-P-2-2-14 (1753) LSTBM: a Novel Sequence Representation of Speech Spectra Using Restricted Boltzmann Machine with Long Short-Term Memory
- Wed-P-2-2-2 (2286) Audio-visual Voice Conversion Using Deep Canonical Correlation Analysis for Deep Bottleneck Features
- Wed-P-2-2-3 (1869) An Investigation of Convolution Attention Based Models for Multilingual Speech Synthesis of Indian Languages
- Wed-P-2-2-4 (2066) The Effect of Real-Time Constraints on Automatic Speech Animation
- Wed-P-2-2-5 (2587) Joint Learning of Facial Expression and Head Pose from Speech
- Wed-P-2-2-6 (1306) Acoustic-dependent Phonemic Transcription for Text-to-speech Synthesis
- Wed-P-2-2-7 (1791) Multimodal Speech Synthesis Architecture for Unsupervised Speaker Adaptation
- Wed-P-2-2-8 (999) Articulatory-to-speech Conversion Using Bi-directional Long Short-term Memory
- Wed-P-2-2-9 (1080) Implementation of Respiration in Articulatory Synthesis Using a Pressure-Volume Lung Model
- Wed-P-2-2-10 (1198) Learning and Modeling Unit Embeddings for Improving HMM-based Unit Selection Speech Synthesis
- Wed-P-2-2-11 (1305) Deep Metric Learning for the Target Cost in Unit-Selection Speech Synthesizer
- Wed-P-2-2-12 (1460) DNN-based Speech Synthesis for Small Data Sets Considering Bidirectional Speech-Text Conversion
- Wed-P-2-2-13 (1286) A Weighted Superposition of Functional Contours Model for Modelling Contextual Prominence of Elementary Prosodic Contours
- Wed-P-2-2-14 (1753) LSTBM: a Novel Sequence Representation of Speech Spectra Using Restricted Boltzmann Machine with Long Short-Term Memory
- Wed-P-2-3-1 (1284) Should Code-switching Models Be Asymmetric?
- Wed-P-2-3-2 (48) Cross-language Perception of Mandarin Lexical Tones by Mongolian-speaking Bilinguals in the Inner Mongolia Autonomous Region, China
- Wed-P-2-3-3 (1336) Automatically Measuring L2 Speech Fluency without the Need of ASR: a Proof-of-concept Study with Japanese Learners of French
- Wed-P-2-3-4 (1983) Analysis of L2 Learners’ Progress of Distinguishing Mandarin Tone 2 and Tone 3
- Wed-P-2-3-5 (2027) Unsupervised Discovery of Non-native Phonetic Patterns in L2 English Speech for Mispronunciation Detection and Diagnosis
- Wed-P-2-3-6 (2224) Wuxi Speakers’ Production and Perception of Coda Nasals in Mandarin
- Wed-P-2-3-7 (2373) The Diphthongs of Formal Nigerian English: a Preliminary Acoustic Analysis
- Wed-P-2-3-8 (1798) Characterizing Rhythm Differences between Strong and Weak Accented L2 Speech
- Wed-P-2-3-9 (2422) Analysis of phone errors attributable to phonological effects associated with language acquisition through bottleneck feature visualisations
- Wed-P-2-3-10 (1938) Category Similarity in Multilingual Pronunciation Training
- Wed-P-2-3-11 (2078) Talker Diarization in the Wild: the Case of Child-centered Daylong Audio-recordings
- Wed-P-2-3-12 (2523) Automated Classification of Children’S Linguistic versus Non-Linguistic Vocalisations
- Wed-P-2-3-13 (1556) Pitch Characteristics of L2 English Speech by Chinese Speakers: a Large-scale Study
- Wed-P-2-3-2 (48) Cross-language Perception of Mandarin Lexical Tones by Mongolian-speaking Bilinguals in the Inner Mongolia Autonomous Region, China
- Wed-P-2-3-3 (1336) Automatically Measuring L2 Speech Fluency without the Need of ASR: a Proof-of-concept Study with Japanese Learners of French
- Wed-P-2-3-4 (1983) Analysis of L2 Learners’ Progress of Distinguishing Mandarin Tone 2 and Tone 3
- Wed-P-2-3-5 (2027) Unsupervised Discovery of Non-native Phonetic Patterns in L2 English Speech for Mispronunciation Detection and Diagnosis
- Wed-P-2-3-6 (2224) Wuxi Speakers’ Production and Perception of Coda Nasals in Mandarin
- Wed-P-2-3-7 (2373) The Diphthongs of Formal Nigerian English: a Preliminary Acoustic Analysis
- Wed-P-2-3-8 (1798) Characterizing Rhythm Differences between Strong and Weak Accented L2 Speech
- Wed-P-2-3-9 (2422) Analysis of phone errors attributable to phonological effects associated with language acquisition through bottleneck feature visualisations
- Wed-P-2-3-10 (1938) Category Similarity in Multilingual Pronunciation Training
- Wed-P-2-3-11 (2078) Talker Diarization in the Wild: the Case of Child-centered Daylong Audio-recordings
- Wed-P-2-3-12 (2523) Automated Classification of Children’S Linguistic versus Non-Linguistic Vocalisations
- Wed-P-2-3-13 (1556) Pitch Characteristics of L2 English Speech by Chinese Speakers: a Large-scale Study
- Wed-P-2-4-1 (1343) Dual Language Models for Code Switched Speech Recognition
- Wed-P-2-4-2 (1711) Multilingual Neural Network Acoustic Modelling for ASR of Under-Resourced English-isiZulu Code-Switched Speech
- Wed-P-2-4-3 (1580) Fast ASR-free and Almost Zero-resource Keyword Spotting Using DTW and CNNs for Humanitarian Monitoring
- Wed-P-2-4-4 (1668) Text-Dependent Speech Enhancement for Small-Footprint Robust Keyword Detection
- Wed-P-2-4-5 (1124) Improved ASR for Under-resourced Languages through Multi-task Learning with Acoustic Landmarks
- Wed-P-2-4-6 (2454) Cross-language Phoneme Mapping for Low-resource Languages: an Exploration of Benefits and Trade-offs
- Wed-P-2-4-7 (1352) User-centric Evaluation of Automatic Punctuation in ASR Closed Captioning
- Wed-P-2-4-8 (1096) Punctuation Prediction Model for Conversational Speech
- Wed-P-2-4-9 (2457) BUT OpenSAT 2017 Speech Recognition System
- Wed-P-2-4-10 (2434) Visual Recognition of Continuous Cued Speech Using a Tandem CNN-HMM Approach
- Wed-P-2-4-11 (2112) Building Large-vocabulary Speaker-independent Lipreading Systems
- Wed-P-2-4-12 (2079) CRIM's System for the MGB-3 English Multi-Genre Broadcast Media Transcription
- Wed-P-2-4-13 (2384) Sampling Strategies in Siamese Networks for Unsupervised Speech Representation Learning
- Wed-P-2-4-14 (1204) Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting
- Wed-P-2-4-2 (1711) Multilingual Neural Network Acoustic Modelling for ASR of Under-Resourced English-isiZulu Code-Switched Speech
- Wed-P-2-4-3 (1580) Fast ASR-free and Almost Zero-resource Keyword Spotting Using DTW and CNNs for Humanitarian Monitoring
- Wed-P-2-4-4 (1668) Text-Dependent Speech Enhancement for Small-Footprint Robust Keyword Detection
- Wed-P-2-4-5 (1124) Improved ASR for Under-resourced Languages through Multi-task Learning with Acoustic Landmarks
- Wed-P-2-4-6 (2454) Cross-language Phoneme Mapping for Low-resource Languages: an Exploration of Benefits and Trade-offs
- Wed-P-2-4-7 (1352) User-centric Evaluation of Automatic Punctuation in ASR Closed Captioning
- Wed-P-2-4-8 (1096) Punctuation Prediction Model for Conversational Speech
- Wed-P-2-4-9 (2457) BUT OpenSAT 2017 Speech Recognition System
- Wed-P-2-4-10 (2434) Visual Recognition of Continuous Cued Speech Using a Tandem CNN-HMM Approach
- Wed-P-2-4-11 (2112) Building Large-vocabulary Speaker-independent Lipreading Systems
- Wed-P-2-4-12 (2079) CRIM's System for the MGB-3 English Multi-Genre Broadcast Media Transcription
- Wed-P-2-4-13 (2384) Sampling Strategies in Siamese Networks for Unsupervised Speech Representation Learning
- Wed-P-2-4-14 (1204) Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting
- Wed-O-3-1-1 (2334) Multilingual Bottleneck Features for Subword Modeling in Zero-resource Languages
- Wed-O-3-1-2 (1081) Exploiting Speaker and Phonetic Diversity of Mismatched Language Resources for Unsupervised Subword Modeling
- Wed-O-3-1-3 (1308) Unsupervised Word Segmentation from Speech with Attention
- Wed-O-3-1-4 (2364) Learning Word Embeddings: Unsupervised Methods for Fixed-size Representations of Variable-length Speech Segments
- Wed-O-3-1-5 (2148) Full Bayesian Hidden Markov Model Variational Autoencoder for Acoustic Unit Discovery
- Wed-O-3-1-6 (2194) Unspeech: Unsupervised Speech Context Embeddings
- Wed-O-3-1-2 (1081) Exploiting Speaker and Phonetic Diversity of Mismatched Language Resources for Unsupervised Subword Modeling
- Wed-O-3-1-3 (1308) Unsupervised Word Segmentation from Speech with Attention
- Wed-O-3-1-4 (2364) Learning Word Embeddings: Unsupervised Methods for Fixed-size Representations of Variable-length Speech Segments
- Wed-O-3-1-5 (2148) Full Bayesian Hidden Markov Model Variational Autoencoder for Acoustic Unit Discovery
- Wed-O-3-1-6 (2194) Unspeech: Unsupervised Speech Context Embeddings
- Wed-O-3-2-1 (1371) Impact of Aliasing on Deep CNN-Based End-to-End Acoustic Models
- Wed-O-3-2-2 (1526) Keyword Based Speaker Localization: Localizing a Target Speaker in a Multi-speaker Environment
- Wed-O-3-2-3 (1629) End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction
- Wed-O-3-2-4 (1773) PhaseNet: Discretized Phase Modeling with Deep Neural Networks for Audio Source Separation
- Wed-O-3-2-5 (1940) Integrating Spectral and Spatial Features for Multi-Channel Speaker Separation
- Wed-O-3-2-6 (2516) DNN Driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation
- Wed-O-3-2-2 (1526) Keyword Based Speaker Localization: Localizing a Target Speaker in a Multi-speaker Environment
- Wed-O-3-2-3 (1629) End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction
- Wed-O-3-2-4 (1773) PhaseNet: Discretized Phase Modeling with Deep Neural Networks for Audio Source Separation
- Wed-O-3-2-5 (1940) Integrating Spectral and Spatial Features for Multi-Channel Speaker Separation
- Wed-O-3-2-6 (2516) DNN Driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation
- Wed-O-3-3-1 (1256) Exploring Temporal Reduction in Dialectal Spanish: a Large-scale Study of Lenition of Voiced Stops and Coda-s
- Wed-O-3-3-2 (1130) Dialect-geographical Acoustic-Tonetics: Five Disyllabic Tone Sandhi Patterns in Cognate Words from the Wu Dialects of ZhèJiāNg Province
- Wed-O-3-3-3 (1065) Regional Variation of /r/ in Swiss German Dialects
- Wed-O-3-3-4 (1944) Variation in the FACE Vowel across West Yorkshire: Implications for Forensic Speaker Comparisons
- Wed-O-3-3-5 (65) The ‘West Yorkshire Regional English Database’: Investigations into the Generalizability of Reference Populations for Forensic Speaker Comparison Casework
- Wed-O-3-3-6 (2381) Studying Vowel Variation in French-Algerian Arabic Code-switched Speech
- Wed-O-3-3-2 (1130) Dialect-geographical Acoustic-Tonetics: Five Disyllabic Tone Sandhi Patterns in Cognate Words from the Wu Dialects of ZhèJiāNg Province
- Wed-O-3-3-3 (1065) Regional Variation of /r/ in Swiss German Dialects
- Wed-O-3-3-4 (1944) Variation in the FACE Vowel across West Yorkshire: Implications for Forensic Speaker Comparisons
- Wed-O-3-3-5 (65) The ‘West Yorkshire Regional English Database’: Investigations into the Generalizability of Reference Populations for Forensic Speaker Comparison Casework
- Wed-O-3-3-6 (2381) Studying Vowel Variation in French-Algerian Arabic Code-switched Speech
- Wed-O-3-4-1 (1942) Fearless Steps: Apollo-11 Corpus Advancements for Speech Technologies from Earth to the Moon
- Wed-O-3-4-2 (1516) A Knowledge Driven Structural Segmentation Approach for Play-Talk Classification During Autism Assessment
- Wed-O-3-4-3 (1349) An Open Source Emotional Speech Corpus for Human Robot Interaction Applications
- Wed-O-3-4-4 (2330) Speech Database and Protocol Validation Using Waveform Entropy
- Wed-O-3-4-5 (2212) A French-Spanish Multimodal Speech Communication Corpus Incorporating Acoustic Data, Facial, Hands and Arms Gestures Information
- Wed-O-3-4-6 (1110) L2-ARCTIC: a Non-native English Speech Corpus
- Wed-O-3-4-2 (1516) A Knowledge Driven Structural Segmentation Approach for Play-Talk Classification During Autism Assessment
- Wed-O-3-4-3 (1349) An Open Source Emotional Speech Corpus for Human Robot Interaction Applications
- Wed-O-3-4-4 (2330) Speech Database and Protocol Validation Using Waveform Entropy
- Wed-O-3-4-5 (2212) A French-Spanish Multimodal Speech Communication Corpus Incorporating Acoustic Data, Facial, Hands and Arms Gestures Information
- Wed-O-3-4-6 (1110) L2-ARCTIC: a Non-native English Speech Corpus
- Wed-SS-3-1-1 (1252) ZCU-NTIS Speaker Diarization System for the DIHARD 2018 Challenge
- Wed-SS-3-1-2 (1742) Speaker Diarization with Enhancing Speech for the First DIHARD Challenge
- Wed-SS-3-1-3 (1749) BUT System for DIHARD Speech Diarization Challenge 2018
- Wed-SS-3-1-4 (1841) Estimation of the Number of Speakers with Variational Bayesian PLDA in the DIHARD Diarization Challenge.
- Wed-SS-3-1-5 (1893) Diarization Is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge
- Wed-SS-3-1-6 (2172) The EURECOM Submission to the First DIHARD Challenge
- Wed-SS-3-1-7 (2304) Joint Discriminative Embedding Learning, Speech Activity and Overlap Detection for the DIHARD Speaker Diarization Challenge
- Wed-SS-3-1-2 (1742) Speaker Diarization with Enhancing Speech for the First DIHARD Challenge
- Wed-SS-3-1-3 (1749) BUT System for DIHARD Speech Diarization Challenge 2018
- Wed-SS-3-1-4 (1841) Estimation of the Number of Speakers with Variational Bayesian PLDA in the DIHARD Diarization Challenge.
- Wed-SS-3-1-5 (1893) Diarization Is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge
- Wed-SS-3-1-6 (2172) The EURECOM Submission to the First DIHARD Challenge
- Wed-SS-3-1-7 (2304) Joint Discriminative Embedding Learning, Speech Activity and Overlap Detection for the DIHARD Speaker Diarization Challenge
- Wed-P-3-1-1 (1626) Multilingual Grapheme-to-Phoneme Conversion with Global Character Vectors
- Wed-P-3-1-2 (1694) A Hybrid Approach to Grapheme to Phoneme Conversion in Assamese
- Wed-P-3-1-3 (2525) Investigation of Using Disentangled and Interpretable Representations for One-shot Cross-lingual Voice Conversion
- Wed-P-3-1-4 (1174) Using Pupillometry to Measure the Cognitive Load of Synthetic Speech
- Wed-P-3-1-5 (1199) Measuring the Cognitive Load of Synthetic Speech Using a Dual Task Paradigm
- Wed-P-3-1-6 (42) Attentive Sequence-to-Sequence Learning for Diacritic Restoration of YorùBá Language Text
- Wed-P-3-1-7 (70) Gated Convolutional Neural Network for Sentence Matching
- Wed-P-3-1-8 (1920) On Training and Evaluation of Grapheme-to-Phoneme Mappings with Limited Data
- Wed-P-3-1-9 (1093) The Perception and Analysis of the Likeability and Human Likeness of Synthesized Speech
- Wed-P-3-1-10 (1159) Word Emphasis Prediction for Expressive Text to Speech
- Wed-P-3-1-11 (1313) A Comparison of Speaker-based and Utterance-based Data Selection for Text-to-Speech Synthesis
- Wed-P-3-1-12 (1316) Data Requirements, Selection and Augmentation for DNN-based Speech Synthesis from Crowdsourced Data
- Wed-P-3-1-2 (1694) A Hybrid Approach to Grapheme to Phoneme Conversion in Assamese
- Wed-P-3-1-3 (2525) Investigation of Using Disentangled and Interpretable Representations for One-shot Cross-lingual Voice Conversion
- Wed-P-3-1-4 (1174) Using Pupillometry to Measure the Cognitive Load of Synthetic Speech
- Wed-P-3-1-5 (1199) Measuring the Cognitive Load of Synthetic Speech Using a Dual Task Paradigm
- Wed-P-3-1-6 (42) Attentive Sequence-to-Sequence Learning for Diacritic Restoration of YorùBá Language Text
- Wed-P-3-1-7 (70) Gated Convolutional Neural Network for Sentence Matching
- Wed-P-3-1-8 (1920) On Training and Evaluation of Grapheme-to-Phoneme Mappings with Limited Data
- Wed-P-3-1-9 (1093) The Perception and Analysis of the Likeability and Human Likeness of Synthesized Speech
- Wed-P-3-1-10 (1159) Word Emphasis Prediction for Expressive Text to Speech
- Wed-P-3-1-11 (1313) A Comparison of Speaker-based and Utterance-based Data Selection for Text-to-Speech Synthesis
- Wed-P-3-1-12 (1316) Data Requirements, Selection and Augmentation for DNN-based Speech Synthesis from Crowdsourced Data
- Wed-P-3-2-1 (2361) Lightly Supervised vs. Semi-supervised Training of Acoustic Model on Luxembourgish for Low-resource Automatic Speech Recognition
- Wed-P-3-2-2 (1597) Investigation on the Combination of Batch Normalization and Dropout in BLSTM-based Acoustic Modeling for ASR
- Wed-P-3-2-3 (1563) Inference-Invariant Transformation of Batch Normalization for Domain Adaptation of Acoustic Models
- Wed-P-3-2-4 (1162) Active Learning for LF-MMI Trained Neural Networks in ASR
- Wed-P-3-2-5 (2191) An Investigation of Mixup Training Strategies for Acoustic Models in ASR
- Wed-P-3-2-6 (1972) Comparison of Unsupervised Modulation Filter Learning Methods for ASR
- Wed-P-3-2-7 (2517) Improved Training for Online End-to-end Speech Recognition Systems
- Wed-P-3-2-8 (2335) Combining Natural Gradient with Hessian Free Methods for Sequence Training
- Wed-P-3-2-9 (79) Lattice-free State-level Minimum Bayes Risk Training of Acoustic Models
- Wed-P-3-2-10 (2030) A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition
- Wed-P-3-2-11 (1891) Multilingual Deep Neural Network Training Using Cyclical Learning Rate
- Wed-P-3-2-2 (1597) Investigation on the Combination of Batch Normalization and Dropout in BLSTM-based Acoustic Modeling for ASR
- Wed-P-3-2-3 (1563) Inference-Invariant Transformation of Batch Normalization for Domain Adaptation of Acoustic Models
- Wed-P-3-2-4 (1162) Active Learning for LF-MMI Trained Neural Networks in ASR
- Wed-P-3-2-5 (2191) An Investigation of Mixup Training Strategies for Acoustic Models in ASR
- Wed-P-3-2-6 (1972) Comparison of Unsupervised Modulation Filter Learning Methods for ASR
- Wed-P-3-2-7 (2517) Improved Training for Online End-to-end Speech Recognition Systems
- Wed-P-3-2-8 (2335) Combining Natural Gradient with Hessian Free Methods for Sequence Training
- Wed-P-3-2-9 (79) Lattice-free State-level Minimum Bayes Risk Training of Acoustic Models
- Wed-P-3-2-10 (2030) A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition
- Wed-P-3-2-11 (1891) Multilingual Deep Neural Network Training Using Cyclical Learning Rate
- Wed-P-3-3-1 (1541) Development of the CUHK Dysarthric Speech Recognition System for the UA Speech Corpus
- Wed-P-3-3-2 (1266) Automatic Evaluation of Speech Intelligibility Based on I-vectors in the Context of Head and Neck Cancers
- Wed-P-3-3-3 (2250) Dysarthric Speech Recognition Using Convolutional LSTM Neural Network
- Wed-P-3-3-4 (1264) Perceptual and Automatic Evaluations of the Intelligibility of Speech Degraded by Noise Induced Hearing Loss Simulation
- Wed-P-3-3-5 (67) Articulatory Features for ASR of Pathological Speech
- Wed-P-3-3-6 (1806) Mining Multimodal Repositories for Speech Affecting Diseases
- Wed-P-3-3-7 (1428) Long Distance Voice Channel Diagnosis Using Deep Neural Networks
- Wed-P-3-3-8 (40) Speech Recognition for Medical Conversations
- Wed-P-3-3-2 (1266) Automatic Evaluation of Speech Intelligibility Based on I-vectors in the Context of Head and Neck Cancers
- Wed-P-3-3-3 (2250) Dysarthric Speech Recognition Using Convolutional LSTM Neural Network
- Wed-P-3-3-4 (1264) Perceptual and Automatic Evaluations of the Intelligibility of Speech Degraded by Noise Induced Hearing Loss Simulation
- Wed-P-3-3-5 (67) Articulatory Features for ASR of Pathological Speech
- Wed-P-3-3-6 (1806) Mining Multimodal Repositories for Speech Affecting Diseases
- Wed-P-3-3-7 (1428) Long Distance Voice Channel Diagnosis Using Deep Neural Networks
- Wed-P-3-3-8 (40) Speech Recognition for Medical Conversations
- Wed-P-3-4-1 (1320) Prosodic Focus Acquisition in French Early Cochlear Implanted Children
- Wed-P-3-4-2 (1725) The Role of Temporal Variation in Narrative Organization
- Wed-P-3-4-3 (1827) Interaction Mechanisms between Glottal Source and Vocal Tract in Pitch Glides
- Wed-P-3-4-4 (1862) Relating Articulatory Motions in Different Speaking Rates
- Wed-P-3-4-5 (2371) Estimation of the Asymmetry Parameter of the Glottal Flow Waveform Using the Electroglottographic Signal
- Wed-P-3-4-6 (1967) Classification of Disorders in Vocal Folds Using Electroglottographic Signal
- Wed-P-3-4-7 (2572) Automatic Glottis Localization and Segmentation in Stroboscopic Videos Using Deep Neural Network
- Wed-P-3-4-8 (1948) Respiratory and Respiratory Muscular Control in JL1’S and JL2’S Text Reading Utilizing 4-RSTs and a Soft Respiratory Mask with a Two-Way Bulb
- Wed-P-3-4-9 (1849) A Preliminary Study on Tonal Coarticulation in Continuous Speech
- Wed-P-3-4-2 (1725) The Role of Temporal Variation in Narrative Organization
- Wed-P-3-4-3 (1827) Interaction Mechanisms between Glottal Source and Vocal Tract in Pitch Glides
- Wed-P-3-4-4 (1862) Relating Articulatory Motions in Different Speaking Rates
- Wed-P-3-4-5 (2371) Estimation of the Asymmetry Parameter of the Glottal Flow Waveform Using the Electroglottographic Signal
- Wed-P-3-4-6 (1967) Classification of Disorders in Vocal Folds Using Electroglottographic Signal
- Wed-P-3-4-7 (2572) Automatic Glottis Localization and Segmentation in Stroboscopic Videos Using Deep Neural Network
- Wed-P-3-4-8 (1948) Respiratory and Respiratory Muscular Control in JL1’S and JL2’S Text Reading Utilizing 4-RSTs and a Soft Respiratory Mask with a Two-Way Bulb
- Wed-P-3-4-9 (1849) A Preliminary Study on Tonal Coarticulation in Continuous Speech
- Thu-O-1-1-1 (2003) Far-Field Speech Recognition Using Multivariate Autoregressive Models
- Thu-O-1-1-2 (2566) Efficient Implementation of the Room Simulator for Training Deep Neural Network Acoustic Models
- Thu-O-1-1-3 (1037) Stream Attention for Distributed Multi-Microphone Speech Recognition
- Thu-O-1-1-4 (2284) Recognizing Overlapped Speech in Meetings: a Multichannel Separation Approach Using Neural Networks
- Thu-O-1-1-5 (2196) Integrating Neural Network Based Beamforming and Weighted Prediction Error Dereverberation
- Thu-O-1-1-6 (2427) A Probability Weighted Beamformer for Noise Robust ASR
- Thu-O-1-1-2 (2566) Efficient Implementation of the Room Simulator for Training Deep Neural Network Acoustic Models
- Thu-O-1-1-3 (1037) Stream Attention for Distributed Multi-Microphone Speech Recognition
- Thu-O-1-1-4 (2284) Recognizing Overlapped Speech in Meetings: a Multichannel Separation Approach Using Neural Networks
- Thu-O-1-1-5 (2196) Integrating Neural Network Based Beamforming and Weighted Prediction Error Dereverberation
- Thu-O-1-1-6 (2427) A Probability Weighted Beamformer for Noise Robust ASR
- Thu-O-1-2-1 (2042) Effects of Dimensional Input on Paralinguistic Information Perceived from Synthesized Dialogue Speech with Neural Network
- Thu-O-1-2-2 (2174) Neural MultiVoice Models for Expressing Novel Personalities in Dialog
- Thu-O-1-2-3 (2467) Expressive Speech Synthesis Using Sentiment Embeddings
- Thu-O-1-2-4 (1113) Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder
- Thu-O-1-2-5 (1991) Rapid Style Adaptation Using Residual Error Embedding for Expressive Speech Synthesis
- Thu-O-1-2-6 (1511) EMPHASIS: an Emotional Phoneme-based Acoustic Model for Speech Synthesis System
- Thu-O-1-2-2 (2174) Neural MultiVoice Models for Expressing Novel Personalities in Dialog
- Thu-O-1-2-3 (2467) Expressive Speech Synthesis Using Sentiment Embeddings
- Thu-O-1-2-4 (1113) Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder
- Thu-O-1-2-5 (1991) Rapid Style Adaptation Using Residual Error Embedding for Expressive Speech Synthesis
- Thu-O-1-2-6 (1511) EMPHASIS: an Emotional Phoneme-based Acoustic Model for Speech Synthesis System
- Thu-O-1-3-1 (996) Bags in Bag: Generating Context-Aware Bags for Tracking Emotions from Speech
- Thu-O-1-3-2 (1242) An Attention Pooling Based Representation Learning Method for Speech Emotion Recognition
- Thu-O-1-3-3 (2397) Predicting Arousal and Valence from Waveforms and Spectrograms Using Deep Neural Networks
- Thu-O-1-3-4 (1353) Emotion Identification from Raw Speech Signals Using DNNs
- Thu-O-1-3-5 (1455) Encoding Individual Acoustic Features Using Dyad-Augmented Deep Variational Representations for Dialog-level Emotion Recognition
- Thu-O-1-3-6 (1568) Variational Autoencoders for Learning Latent Representations of Speech Emotion: a Preliminary Study
- Thu-O-1-3-2 (1242) An Attention Pooling Based Representation Learning Method for Speech Emotion Recognition
- Thu-O-1-3-3 (2397) Predicting Arousal and Valence from Waveforms and Spectrograms Using Deep Neural Networks
- Thu-O-1-3-4 (1353) Emotion Identification from Raw Speech Signals Using DNNs
- Thu-O-1-3-5 (1455) Encoding Individual Acoustic Features Using Dyad-Augmented Deep Variational Representations for Dialog-level Emotion Recognition
- Thu-O-1-3-6 (1568) Variational Autoencoders for Learning Latent Representations of Speech Emotion: a Preliminary Study
- Thu-O-1-4-1 (1202) Phoneme-to-Articulatory Mapping Using Bidirectional Gated RNN
- Thu-O-1-4-2 (1108) Tongue Segmentation with Geometrically Constrained Snake Model
- Thu-O-1-4-3 (1843) Low Resource Acoustic-to-articulatory Inversion Using Bi-directional Long Short Term Memory
- Thu-O-1-4-4 (1570) Automatic Visual Augmentation for Concatenation Based Synthesized Articulatory Videos from Real-time MRI Data for Spoken Language Training
- Thu-O-1-4-5 (1939) Air-Tissue Boundary Segmentation in Real-Time Magnetic Resonance Imaging Video Using Semantic Segmentation with Fully Convolutional Networks
- Thu-O-1-4-6 (1509) Noise Robust Acoustic to Articulatory Speech Inversion
- Thu-O-1-4-2 (1108) Tongue Segmentation with Geometrically Constrained Snake Model
- Thu-O-1-4-3 (1843) Low Resource Acoustic-to-articulatory Inversion Using Bi-directional Long Short Term Memory
- Thu-O-1-4-4 (1570) Automatic Visual Augmentation for Concatenation Based Synthesized Articulatory Videos from Real-time MRI Data for Spoken Language Training
- Thu-O-1-4-5 (1939) Air-Tissue Boundary Segmentation in Real-Time Magnetic Resonance Imaging Video Using Semantic Segmentation with Fully Convolutional Networks
- Thu-O-1-4-6 (1509) Noise Robust Acoustic to Articulatory Speech Inversion
- Thu-SS-1-1-1 (-) Welcome and Introduction
- Thu-SS-1-1-2 (1043) Designing a Pneumatic Bionic Voice Prosthesis - A Statistical Approach for Source Excitation Generation
- Thu-SS-1-1-3 (1904) A Neural Model to Predict Parameters for a Generalized Command Response Model of Intonation
- Thu-SS-1-1-4 (2484) Articulation-to-Speech Synthesis Using Articulatory Flesh Point Sensors’ Orientation Information
- Thu-SS-1-1-5 (1565) Effectiveness of Generative Adversarial Network for Non-Audible Murmur-to-Whisper Speech Conversion
- Thu-SS-1-1-6 (2080) Investigating Objective Intelligibility in Real-Time EMG-to-Speech Conversion
- Thu-SS-1-1-7 (2318) Domain-Adversarial Training for Session Independent EMG-based Speech Recognition
- Thu-SS-1-1-8 (1078) Multi-Task Learning of Speech Recognition and Speech Synthesis Parameters for Ultrasound-based Silent Speech Interfaces
- Thu-SS-1-1-9 (-) Discussion and Closing
- Thu-SS-1-1-2 (1043) Designing a Pneumatic Bionic Voice Prosthesis - A Statistical Approach for Source Excitation Generation
- Thu-SS-1-1-3 (1904) A Neural Model to Predict Parameters for a Generalized Command Response Model of Intonation
- Thu-SS-1-1-4 (2484) Articulation-to-Speech Synthesis Using Articulatory Flesh Point Sensors’ Orientation Information
- Thu-SS-1-1-5 (1565) Effectiveness of Generative Adversarial Network for Non-Audible Murmur-to-Whisper Speech Conversion
- Thu-SS-1-1-6 (2080) Investigating Objective Intelligibility in Real-Time EMG-to-Speech Conversion
- Thu-SS-1-1-7 (2318) Domain-Adversarial Training for Session Independent EMG-based Speech Recognition
- Thu-SS-1-1-8 (1078) Multi-Task Learning of Speech Recognition and Speech Synthesis Parameters for Ultrasound-based Silent Speech Interfaces
- Thu-SS-1-1-9 (-) Discussion and Closing
- Thu-SS-1-2-1 (-) Introduction
- Thu-SS-1-2-2 (1188) Transcription Correction for Indian Languages Using Acoustic Signatures
- Thu-SS-1-2-3 (1302) BUT System for Low Resource Indian Language ASR
- Thu-SS-1-2-4 (1553) DA-IICT/IIITV System for Low Resource Speech Recognition Challenge 2018
- Thu-SS-1-2-5 (1584) An Exploration towards Joint Acoustic Modeling for Indian Languages: IIIT-H Submission for Low Resource Speech Recognition Challenge for Indian Languages, INTERSPEECH 2018
- Thu-SS-1-2-6 (2117) TDNN-based Multilingual Speech Recognition System for Low Resource Indian Languages
- Thu-SS-1-2-7 (2226) Articulatory and Stacked Bottleneck Features for Low Resource Speech Recognition
- Thu-SS-1-2-8 (2473) ISI ASR System for the Low Resource Speech Recognition Challenge for Indian Languages
- Thu-SS-1-2-2 (1188) Transcription Correction for Indian Languages Using Acoustic Signatures
- Thu-SS-1-2-3 (1302) BUT System for Low Resource Indian Language ASR
- Thu-SS-1-2-4 (1553) DA-IICT/IIITV System for Low Resource Speech Recognition Challenge 2018
- Thu-SS-1-2-5 (1584) An Exploration towards Joint Acoustic Modeling for Indian Languages: IIIT-H Submission for Low Resource Speech Recognition Challenge for Indian Languages, INTERSPEECH 2018
- Thu-SS-1-2-6 (2117) TDNN-based Multilingual Speech Recognition System for Low Resource Indian Languages
- Thu-SS-1-2-7 (2226) Articulatory and Stacked Bottleneck Features for Low Resource Speech Recognition
- Thu-SS-1-2-8 (2473) ISI ASR System for the Low Resource Speech Recognition Challenge for Indian Languages
- Thu-S&T-1-1-1 (3047) An automated assistant for medical scribes
- Thu-S&T-1-1-2 (3048) AGROASSAM: A Web Based Assamese Speech Recognition Application for Retrieving Agricultural Commodity Price and Weather Information
- Thu-S&T-1-1-3 (3049) Voice-powered solutions with Cloud AI
- Thu-S&T-1-1-4 (3050) Speech synthesis in the wild
- Thu-S&T-1-1-2 (3048) AGROASSAM: A Web Based Assamese Speech Recognition Application for Retrieving Agricultural Commodity Price and Weather Information
- Thu-S&T-1-1-3 (3049) Voice-powered solutions with Cloud AI
- Thu-S&T-1-1-4 (3050) Speech synthesis in the wild
- Thu-P-1-1-1 (1020) Deep Noise Tracking Network: a Hybrid Signal Processing/Deep Learning Approach to Speech Enhancement
- Thu-P-1-1-2 (1114) A Deep Neural Network Based Harmonic Noise Model for Speech Enhancement
- Thu-P-1-1-3 (1405) A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement
- Thu-P-1-1-4 (1664) All-Neural Multi-Channel Speech Enhancement
- Thu-P-1-1-5 (1484) Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
- Thu-P-1-1-6 (1400) The Conversation: Deep Audio-Visual Speech Enhancement
- Thu-P-1-1-7 (2440) Student-Teacher Learning for BLSTM Mask-based Speech Enhancement
- Thu-P-1-1-8 (1730) Speech Enhancement Using Deep Mixture of Experts Based on Hard Expectation Maximization
- Thu-P-1-1-9 (2461) Adversarial Feature-Mapping for Speech Enhancement
- Thu-P-1-1-10 (1237) Biophysically-inspired Features Improve the Generalizability of Neural Network-based Speech Enhancement Systems
- Thu-P-1-1-11 (1439) Error Modeling via Asymmetric Laplace Distribution for Deep Neural Network Based Single-Channel Speech Enhancement
- Thu-P-1-1-12 (2423) A Priori SNR Estimation Based on a Recurrent Neural Network for Robust Speech Enhancement
- Thu-P-1-1-2 (1114) A Deep Neural Network Based Harmonic Noise Model for Speech Enhancement
- Thu-P-1-1-3 (1405) A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement
- Thu-P-1-1-4 (1664) All-Neural Multi-Channel Speech Enhancement
- Thu-P-1-1-5 (1484) Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
- Thu-P-1-1-6 (1400) The Conversation: Deep Audio-Visual Speech Enhancement
- Thu-P-1-1-7 (2440) Student-Teacher Learning for BLSTM Mask-based Speech Enhancement
- Thu-P-1-1-8 (1730) Speech Enhancement Using Deep Mixture of Experts Based on Hard Expectation Maximization
- Thu-P-1-1-9 (2461) Adversarial Feature-Mapping for Speech Enhancement
- Thu-P-1-1-10 (1237) Biophysically-inspired Features Improve the Generalizability of Neural Network-based Speech Enhancement Systems
- Thu-P-1-1-11 (1439) Error Modeling via Asymmetric Laplace Distribution for Deep Neural Network Based Single-Channel Speech Enhancement
- Thu-P-1-1-12 (2423) A Priori SNR Estimation Based on a Recurrent Neural Network for Robust Speech Enhancement
- Thu-P-1-2-1 (1120) Multiple Instance Deep Learning for Weakly Supervised Small-Footprint Audio Event Detection
- Thu-P-1-2-2 (1243) Unsupervised Temporal Feature Learning Based on Sparse Coding Embedded BoAW for Acoustic Event Recognition
- Thu-P-1-2-3 (1250) Data Independent Sequence Augmentation Method for Acoustic Scene Classification
- Thu-P-1-2-4 (1299) A Compact and Discriminative Feature Based on Auditory Summary Statistics for Acoustic Scene Classification
- Thu-P-1-2-5 (1481) ASe: Acoustic Scene Embedding Using Deep Archetypal Analysis and GMM
- Thu-P-1-2-6 (1524) Deep Convolutional Neural Network with Scalogram for Audio Scene Modeling
- Thu-P-1-2-7 (1637) Time Aggregation Operators for Multi-label Audio Event Detection
- Thu-P-1-2-8 (1821) Early Detection of Continuous and Partial Audio Events Using CNN
- Thu-P-1-2-9 (1905) Robust Acoustic Event Classification Using Bag-of-Visual-Words
- Thu-P-1-2-10 (2083) Wavelet Transform Based Mel-scaled Features for Acoustic Scene Classification
- Thu-P-1-2-11 (1138) Multi-modal Attention Mechanisms in LSTM and Its Application to Acoustic Scene Classification
- Thu-P-1-2-2 (1243) Unsupervised Temporal Feature Learning Based on Sparse Coding Embedded BoAW for Acoustic Event Recognition
- Thu-P-1-2-3 (1250) Data Independent Sequence Augmentation Method for Acoustic Scene Classification
- Thu-P-1-2-4 (1299) A Compact and Discriminative Feature Based on Auditory Summary Statistics for Acoustic Scene Classification
- Thu-P-1-2-5 (1481) ASe: Acoustic Scene Embedding Using Deep Archetypal Analysis and GMM
- Thu-P-1-2-6 (1524) Deep Convolutional Neural Network with Scalogram for Audio Scene Modeling
- Thu-P-1-2-7 (1637) Time Aggregation Operators for Multi-label Audio Event Detection
- Thu-P-1-2-8 (1821) Early Detection of Continuous and Partial Audio Events Using CNN
- Thu-P-1-2-9 (1905) Robust Acoustic Event Classification Using Bag-of-Visual-Words
- Thu-P-1-2-10 (2083) Wavelet Transform Based Mel-scaled Features for Acoustic Scene Classification
- Thu-P-1-2-11 (1138) Multi-modal Attention Mechanisms in LSTM and Its Application to Acoustic Scene Classification
- Thu-P-1-3-1 (1122) Contextual Language Model Adaptation for Conversational Agents
- Thu-P-1-3-2 (78) Active Memory Networks for Language Modeling
- Thu-P-1-3-3 (1021) Unsupervised and Efficient Vocabulary Expansion for Recurrent Neural Network Language Models in ASR
- Thu-P-1-3-4 (1111) Improving Language Modeling with an Adversarial Critic for Automatic Speech Recognition
- Thu-P-1-3-5 (1369) Training Recurrent Neural Network through Moment Matching for NLP Applications
- Thu-P-1-3-6 (2476) Investigation on LSTM Recurrent N-gram Language Models for Speech Recognition
- Thu-P-1-3-7 (2259) Online Incremental Learning for Speaker-Adaptive Language Models
- Thu-P-1-3-8 (1345) Efficient Language Model Adaptation with Noise Contrastive Estimation and Kullback-Leibler Regularization
- Thu-P-1-3-9 (1413) Recurrent Neural Network Language Model Adaptation for Conversational Speech Recognition
- Thu-P-1-3-10 (84) What to Expect from Expected Kneser-Ney Smoothing
- Thu-P-1-3-11 (1070) i-Vectors in Language Modeling: an Efficient Way of Domain Adaptation for Feed-Forward Models
- Thu-P-1-3-2 (78) Active Memory Networks for Language Modeling
- Thu-P-1-3-3 (1021) Unsupervised and Efficient Vocabulary Expansion for Recurrent Neural Network Language Models in ASR
- Thu-P-1-3-4 (1111) Improving Language Modeling with an Adversarial Critic for Automatic Speech Recognition
- Thu-P-1-3-5 (1369) Training Recurrent Neural Network through Moment Matching for NLP Applications
- Thu-P-1-3-6 (2476) Investigation on LSTM Recurrent N-gram Language Models for Speech Recognition
- Thu-P-1-3-7 (2259) Online Incremental Learning for Speaker-Adaptive Language Models
- Thu-P-1-3-8 (1345) Efficient Language Model Adaptation with Noise Contrastive Estimation and Kullback-Leibler Regularization
- Thu-P-1-3-9 (1413) Recurrent Neural Network Language Model Adaptation for Conversational Speech Recognition
- Thu-P-1-3-10 (84) What to Expect from Expected Kneser-Ney Smoothing
- Thu-P-1-3-11 (1070) i-Vectors in Language Modeling: an Efficient Way of Domain Adaptation for Feed-Forward Models
- Thu-P-1-4-1 (2040) How Did You like 2017? Detection of Language Markers of Depression and Narcissism in Personal Narratives
- Thu-P-1-4-2 (1743) Depression Detection from Short Utterances via Diverse Smartphones in Natural Environmental Conditions
- Thu-P-1-4-3 (2169) Multi-Lingual Depression-Level Assessment from Conversational Speech Using Acoustic and Text Features
- Thu-P-1-4-4 (1059) Dysarthric Speech Classification Using Glottal Features Computed from Non-words, Words and Sentences
- Thu-P-1-4-5 (1079) Identifying Schizophrenia Based on Temporal Parameters in Spontaneous Speech
- Thu-P-1-4-6 (2551) Using Prosodic and Lexical Information for Learning Utterance-level Behaviors in Psychotherapy
- Thu-P-1-4-7 (1630) Automatic Speech Assessment for People with Aphasia Using TDNN-BLSTM with Multi-Task Learning
- Thu-P-1-4-8 (1395) Towards an Unsupervised Entrainment Distance in Conversational Speech Using Deep Neural Networks
- Thu-P-1-4-9 (2186) Patient Privacy in Paralinguistic Tasks
- Thu-P-1-4-10 (2155) A Lightly Supervised Approach to Detect Stuttering in Children's Speech
- Thu-P-1-4-11 (1298) Learning Conditional Acoustic Latent Representation with Gender and Age Attributes for Automatic Pain Level Recognition
- Thu-P-1-4-2 (1743) Depression Detection from Short Utterances via Diverse Smartphones in Natural Environmental Conditions
- Thu-P-1-4-3 (2169) Multi-Lingual Depression-Level Assessment from Conversational Speech Using Acoustic and Text Features
- Thu-P-1-4-4 (1059) Dysarthric Speech Classification Using Glottal Features Computed from Non-words, Words and Sentences
- Thu-P-1-4-5 (1079) Identifying Schizophrenia Based on Temporal Parameters in Spontaneous Speech
- Thu-P-1-4-6 (2551) Using Prosodic and Lexical Information for Learning Utterance-level Behaviors in Psychotherapy
- Thu-P-1-4-7 (1630) Automatic Speech Assessment for People with Aphasia Using TDNN-BLSTM with Multi-Task Learning
- Thu-P-1-4-8 (1395) Towards an Unsupervised Entrainment Distance in Conversational Speech Using Deep Neural Networks
- Thu-P-1-4-9 (2186) Patient Privacy in Paralinguistic Tasks
- Thu-P-1-4-10 (2155) A Lightly Supervised Approach to Detect Stuttering in Children's Speech
- Thu-P-1-4-11 (1298) Learning Conditional Acoustic Latent Representation with Gender and Age Attributes for Automatic Pain Level Recognition
- Thu-O-2-1-1 (1379) A Deep Reinforcement Learning Based Multimodal Coaching Model (DCM) for Slot Filling in Spoken Language Understanding(SLU)
- Thu-O-2-1-2 (2256) Is ATIS Too Shallow to Go Deeper for Benchmarking Spoken Language Understanding Models?
- Thu-O-2-1-3 (2358) Robust Spoken Language Understanding via Paraphrasing
- Thu-O-2-1-4 (1714) Spoken SQuAD: a Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension
- Thu-O-2-1-5 (1149) User Information Augmented Semantic Frame Parsing Using Progressive Neural Networks
- Thu-O-2-1-6 (2403) An Efficient Approach to Encoding Context for Spoken Language Understanding
- Thu-O-2-1-2 (2256) Is ATIS Too Shallow to Go Deeper for Benchmarking Spoken Language Understanding Models?
- Thu-O-2-1-3 (2358) Robust Spoken Language Understanding via Paraphrasing
- Thu-O-2-1-4 (1714) Spoken SQuAD: a Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension
- Thu-O-2-1-5 (1149) User Information Augmented Semantic Frame Parsing Using Progressive Neural Networks
- Thu-O-2-1-6 (2403) An Efficient Approach to Encoding Context for Spoken Language Understanding
- Thu-O-2-2-1 (83) Deep Speech Denoising with Vector Space Projections
- Thu-O-2-2-2 (1150) A Shifted Delta Coefficient Objective for Monaural Speech Separation Using Multi-task Learning
- Thu-O-2-2-3 (1406) A Two-Stage Approach to Noisy Cochannel Speech Separation with Gated Residual Networks
- Thu-O-2-2-4 (1140) Monoaural Audio Source Separation Using Variational Autoencoders
- Thu-O-2-2-5 (2065) Towards Automated Single Channel Source Separation Using Neural Networks
- Thu-O-2-2-6 (2441) Investigations on Data Augmentation and Loss Functions for Deep Learning Based Speech-Background Separation
- Thu-O-2-2-2 (1150) A Shifted Delta Coefficient Objective for Monaural Speech Separation Using Multi-task Learning
- Thu-O-2-2-3 (1406) A Two-Stage Approach to Noisy Cochannel Speech Separation with Gated Residual Networks
- Thu-O-2-2-4 (1140) Monoaural Audio Source Separation Using Variational Autoencoders
- Thu-O-2-2-5 (2065) Towards Automated Single Channel Source Separation Using Neural Networks
- Thu-O-2-2-6 (2441) Investigations on Data Augmentation and Loss Functions for Deep Learning Based Speech-Background Separation
- Thu-O-2-3-1 (1019) Annotator Trustability-based Cooperative Learning Solutions for Intelligent Audio Analysis
- Thu-O-2-3-2 (1063) Semi-supervised Cross-domain Visual Feature Learning for Audio-Visual Broadcast Speech Transcription
- Thu-O-2-3-3 (1943) Deep Lip Reading: a Comparison of Models and an Online Application
- Thu-O-2-3-4 (1447) Iterative Learning of Speech Recognition Models for Air Traffic Control
- Thu-O-2-3-5 (2359) Speaker Adaptive Audio-Visual Fusion for the Open-Vocabulary Section of AVICAR
- Thu-O-2-3-6 (1748) Multimodal Name Recognition in Live TV Subtitling
- Thu-O-2-3-2 (1063) Semi-supervised Cross-domain Visual Feature Learning for Audio-Visual Broadcast Speech Transcription
- Thu-O-2-3-3 (1943) Deep Lip Reading: a Comparison of Models and an Online Application
- Thu-O-2-3-4 (1447) Iterative Learning of Speech Recognition Models for Air Traffic Control
- Thu-O-2-3-5 (2359) Speaker Adaptive Audio-Visual Fusion for the Open-Vocabulary Section of AVICAR
- Thu-O-2-3-6 (1748) Multimodal Name Recognition in Live TV Subtitling
- Thu-O-2-4-1 (46) Dithered Quantization for Frequency-Domain Speech and Audio Coding
- Thu-O-2-4-2 (1026) Postfiltering with Complex Spectral Correlations for Speech and Audio Coding
- Thu-O-2-4-3 (1027) Postfiltering Using Log-Magnitude Spectrum for Speech and Audio Coding
- Thu-O-2-4-4 (2096) Temporal Noise Shaping with Companding
- Thu-O-2-4-5 (2577) Multi-frame Quantization of LSF Parameters Using a Deep Autoencoder and Pyramid Vector Quantizer
- Thu-O-2-4-6 (2578) Multi-frame Coding of LSF Parameters Using Block-Constrained Trellis Coded Vector Quantization
- Thu-O-2-4-2 (1026) Postfiltering with Complex Spectral Correlations for Speech and Audio Coding
- Thu-O-2-4-3 (1027) Postfiltering Using Log-Magnitude Spectrum for Speech and Audio Coding
- Thu-O-2-4-4 (2096) Temporal Noise Shaping with Companding
- Thu-O-2-4-5 (2577) Multi-frame Quantization of LSF Parameters Using a Deep Autoencoder and Pyramid Vector Quantizer
- Thu-O-2-4-6 (2578) Multi-frame Coding of LSF Parameters Using Block-Constrained Trellis Coded Vector Quantization
- Thu-P-2-1-1 (1044) Training Utterance-level Embedding Networks for Speaker Identification and Verification
- Thu-P-2-1-2 (1102) Analysis of Complementary Information Sources in the Speaker Embeddings Framework
- Thu-P-2-1-3 (1158) Self-Attentive Speaker Embeddings for Text-Independent Speaker Verification
- Thu-P-2-1-4 (1515) An Improved Deep Embedding Learning Method for Short Duration Speaker Verification
- Thu-P-2-1-5 (1608) Avoiding Speaker Overfitting in End-to-End DNNs Using Raw Waveform for Text-Independent Speaker Verification
- Thu-P-2-1-6 (1688) Deeply Fused Speaker Embeddings for Text-Independent Speaker Verification
- Thu-P-2-1-7 (1804) Employing Phonetic Information in DNN Speaker Embeddings to Improve Speaker Recognition Performance
- Thu-P-2-1-8 (2300) End-to-end Text-dependent Speaker Verification Using Novel Distance Measures
- Thu-P-2-1-9 (50) Robust Speaker Clustering using Mixtures of von Mises-Fisher Distributions for Naturalistic Audio Streams
- Thu-P-2-1-10 (2305) Triplet Network with Attention for Speaker Diarization
- Thu-P-2-1-11 (1680) I-vector Transformation Using Conditional Generative Adversarial Networks for Short Utterance Speaker Verification
- Thu-P-2-1-12 (92) Analysis of Length Normalization in End-to-End Speaker Verification System
- Thu-P-2-1-13 (1545) Angular Softmax for Short-Duration Text-independent Speaker Verification
- Thu-P-2-1-14 (1058) An End-to-End Text-Independent Speaker Identification System on Short Utterances
- Thu-P-2-1-15 (1023) MTGAN: Speaker Verification through Multitasking Triplet Generative Adversarial Networks
- Thu-P-2-1-2 (1102) Analysis of Complementary Information Sources in the Speaker Embeddings Framework
- Thu-P-2-1-3 (1158) Self-Attentive Speaker Embeddings for Text-Independent Speaker Verification
- Thu-P-2-1-4 (1515) An Improved Deep Embedding Learning Method for Short Duration Speaker Verification
- Thu-P-2-1-5 (1608) Avoiding Speaker Overfitting in End-to-End DNNs Using Raw Waveform for Text-Independent Speaker Verification
- Thu-P-2-1-6 (1688) Deeply Fused Speaker Embeddings for Text-Independent Speaker Verification
- Thu-P-2-1-7 (1804) Employing Phonetic Information in DNN Speaker Embeddings to Improve Speaker Recognition Performance
- Thu-P-2-1-8 (2300) End-to-end Text-dependent Speaker Verification Using Novel Distance Measures
- Thu-P-2-1-9 (50) Robust Speaker Clustering using Mixtures of von Mises-Fisher Distributions for Naturalistic Audio Streams
- Thu-P-2-1-10 (2305) Triplet Network with Attention for Speaker Diarization
- Thu-P-2-1-11 (1680) I-vector Transformation Using Conditional Generative Adversarial Networks for Short Utterance Speaker Verification
- Thu-P-2-1-12 (92) Analysis of Length Normalization in End-to-End Speaker Verification System
- Thu-P-2-1-13 (1545) Angular Softmax for Short-Duration Text-independent Speaker Verification
- Thu-P-2-1-14 (1058) An End-to-End Text-Independent Speaker Identification System on Short Utterances
- Thu-P-2-1-15 (1023) MTGAN: Speaker Verification through Multitasking Triplet Generative Adversarial Networks
- Thu-P-2-2-1 (47) Categorical vs Dimensional Perception of Italian Emotional Speech
- Thu-P-2-2-2 (1820) A Three-Layer Emotion Perception Model for Valence and Arousal-Based Detection from Multilingual Speech
- Thu-P-2-2-3 (1778) Cross-lingual Speech Emotion Recognition through Factor Analysis
- Thu-P-2-2-4 (2222) Modeling Self-Reported and Observed Affect from Speech
- Thu-P-2-2-5 (1327) Stochastic Shake-Shake Regularization for Affective Learning from Speech
- Thu-P-2-2-6 (2350) Investigating Speech Enhancement and Perceptual Quality for Speech Emotion Recognition
- Thu-P-2-2-7 (1933) Demonstrating and Modelling Systematic Time-varying Annotator Disagreement in Continuous Emotion Annotation
- Thu-P-2-2-8 (1432) Speech Emotion Recognition from Variable-Length Inputs with Triplet Loss Function
- Thu-P-2-2-9 (1744) Imbalance Learning-based Framework for Fear Recognition in the MediaEval Emotional Impact of Movies Task
- Thu-P-2-2-10 (2228) Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms
- Thu-P-2-2-11 (1811) Speech Emotion Recognition Using Spectrogram & Phoneme Embedding
- Thu-P-2-2-12 (1883) On Enhancing Speech Emotion Recognition Using Generative Adversarial Networks
- Thu-P-2-2-13 (1391) Ladder Networks for Emotion Recognition: Using Unsupervised Auxiliary Tasks to Improve Predictions of Emotional Attributes
- Thu-P-2-2-2 (1820) A Three-Layer Emotion Perception Model for Valence and Arousal-Based Detection from Multilingual Speech
- Thu-P-2-2-3 (1778) Cross-lingual Speech Emotion Recognition through Factor Analysis
- Thu-P-2-2-4 (2222) Modeling Self-Reported and Observed Affect from Speech
- Thu-P-2-2-5 (1327) Stochastic Shake-Shake Regularization for Affective Learning from Speech
- Thu-P-2-2-6 (2350) Investigating Speech Enhancement and Perceptual Quality for Speech Emotion Recognition
- Thu-P-2-2-7 (1933) Demonstrating and Modelling Systematic Time-varying Annotator Disagreement in Continuous Emotion Annotation
- Thu-P-2-2-8 (1432) Speech Emotion Recognition from Variable-Length Inputs with Triplet Loss Function
- Thu-P-2-2-9 (1744) Imbalance Learning-based Framework for Fear Recognition in the MediaEval Emotional Impact of Movies Task
- Thu-P-2-2-10 (2228) Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms
- Thu-P-2-2-11 (1811) Speech Emotion Recognition Using Spectrogram & Phoneme Embedding
- Thu-P-2-2-12 (1883) On Enhancing Speech Emotion Recognition Using Generative Adversarial Networks
- Thu-P-2-2-13 (1391) Ladder Networks for Emotion Recognition: Using Unsupervised Auxiliary Tasks to Improve Predictions of Emotional Attributes
- Thu-P-2-3-1 (1589) Knowledge Distillation for Sequence Model
- Thu-P-2-3-2 (1475) Improving CTC-based Acoustic Model with Very Deep Residual Time-delay Neural Networks
- Thu-P-2-3-3 (1370) Filter Sampling and Combination CNN (FSC-CNN): a Compact CNN Model for Small-footprint ASR Acoustic Modeling Using Raw Waveforms
- Thu-P-2-3-4 (1407) Twin Regularization for Online Speech Recognition
- Thu-P-2-3-5 (1910) Self-Attentional Acoustic Models
- Thu-P-2-3-6 (1797) Hierarchical Recurrent Neural Networks for Acoustic Modeling
- Thu-P-2-3-7 (2061) Dictionary Augmented Sequence-to-Sequence Neural Network for Grapheme to Phoneme Prediction
- Thu-P-2-3-8 (1156) Leveraging Second-Order Log-Linear Model for Improved Deep Learning Based ASR Performance
- Thu-P-2-3-9 (1417) Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks
- Thu-P-2-3-10 (1800) Completely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings
- Thu-P-2-3-11 (1376) Phone Recognition Using a Non-Linear Manifold with Broad Phone Class Dependent DNNs
- Thu-P-2-3-12 (1535) A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation
- Thu-P-2-3-2 (1475) Improving CTC-based Acoustic Model with Very Deep Residual Time-delay Neural Networks
- Thu-P-2-3-3 (1370) Filter Sampling and Combination CNN (FSC-CNN): a Compact CNN Model for Small-footprint ASR Acoustic Modeling Using Raw Waveforms
- Thu-P-2-3-4 (1407) Twin Regularization for Online Speech Recognition
- Thu-P-2-3-5 (1910) Self-Attentional Acoustic Models
- Thu-P-2-3-6 (1797) Hierarchical Recurrent Neural Networks for Acoustic Modeling
- Thu-P-2-3-7 (2061) Dictionary Augmented Sequence-to-Sequence Neural Network for Grapheme to Phoneme Prediction
- Thu-P-2-3-8 (1156) Leveraging Second-Order Log-Linear Model for Improved Deep Learning Based ASR Performance
- Thu-P-2-3-9 (1417) Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks
- Thu-P-2-3-10 (1800) Completely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings
- Thu-P-2-3-11 (1376) Phone Recognition Using a Non-Linear Manifold with Broad Phone Class Dependent DNNs
- Thu-P-2-3-12 (1535) A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation
- Thu-P-2-4-1 (2025) Interactions between Vowels and Nasal Codas in Mandarin Speakers’ Perception of Nasal Finals
- Thu-P-2-4-2 (1245) Weighting Pitch Contour and Loudness Contour in Mandarin Tone Perception in Cochlear Implant Listeners
- Thu-P-2-4-3 (2081) Implementing DIANA to Model Isolated Auditory Word Recognition in English
- Thu-P-2-4-4 (2114) Effects of Homophone Density on Spoken Word Recognition in Mandarin Chinese
- Thu-P-2-4-5 (1285) Visual Timing Information in Audiovisual Speech Perception: Evidence from Lexical Tone Contour
- Thu-P-2-4-6 (73) COSMO SylPhon: A Bayesian perceptuo-motor model to assess phonological learning
- Thu-P-2-4-7 (2104) Experience-dependent Influence of Music and Language on Lexical Pitch Learning Is Not Additive
- Thu-P-2-4-8 (2331) Influences of Fundamental Oscillation on Speaker Identification in Vocalic Utterances by Humans and Computers
- Thu-P-2-4-2 (1245) Weighting Pitch Contour and Loudness Contour in Mandarin Tone Perception in Cochlear Implant Listeners
- Thu-P-2-4-3 (2081) Implementing DIANA to Model Isolated Auditory Word Recognition in English
- Thu-P-2-4-4 (2114) Effects of Homophone Density on Spoken Word Recognition in Mandarin Chinese
- Thu-P-2-4-5 (1285) Visual Timing Information in Audiovisual Speech Perception: Evidence from Lexical Tone Contour
- Thu-P-2-4-6 (73) COSMO SylPhon: A Bayesian perceptuo-motor model to assess phonological learning
- Thu-P-2-4-7 (2104) Experience-dependent Influence of Music and Language on Lexical Pitch Learning Is Not Additive
- Thu-P-2-4-8 (2331) Influences of Fundamental Oscillation on Speaker Identification in Vocalic Utterances by Humans and Computers
Detailed technical program (updated on Aug 15, 2018)
| DATE (dd.mm.yy) | TIME | ROOM | SESSION NAME | PRESEN-TATION TYPE | PAPER CODE | PAPER ID | PAPER TITLE | PAPER AUTHORS |
|---|---|---|---|---|---|---|---|---|
| 03.09.18 | 11:00 | Hall 3 | ISCA Medal Talk | Oral | Mon-Medal-1 | 4001 | From Vocoders to Code-Excited Linear Prediction: Learning How We Hear What We Hear | Bishnu S. Atal |
| 03.09.18 | 14:00 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-1 | 1746 | Semi-Supervised End-to-End Speech Recognition | Shigeki Karita, Shinji Watanabe, Tomoharu Iwata, Atsunori Ogawa and Marc Delcroix |
| 03.09.18 | 14:20 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-2 | 1616 | Improved Training of End-to-end Attention Models for Speech Recognition | Albert Zeyer, Kazuki Irie, Ralf Schlüter and Hermann Ney |
| 03.09.18 | 14:40 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-3 | 1423 | End-to-end Speech Recognition Using Lattice-free MMI | Hossein Hadian, Hossein Sameti, Daniel Povey and Sanjeev Khudanpur |
| 03.09.18 | 15:00 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-4 | 1301 | Multi-channel Attention for End-to-End Speech Recognition | Stefan Braun, Daniel Neil, Jithendar Anumula, Enea Ceolini and Shih-Chii Liu |
| 03.09.18 | 15:20 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-5 | 1898 | Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition | Titouan Parcollet, Ying Zhang, Mohamed Morchid, Chiheb Trabelsi, Georges Linares, Renato de Mori and Yoshua Bengio |
| 03.09.18 | 15:40 | Hall 3 | End-to-End Speech Recognition | Oral | Mon-O-1-1-6 | 1025 | Compression of End-to-End Models | Ruoming Pang, Tara Sainath, Rohit Prabhavalkar, Suyog Gupta, Yonghui Wu, Shuyuan Zhang and Chung-Cheng Chiu |
| 03.09.18 | 14:00 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-1 | 2075 | Learning Interpretable Control Dimensions for Speech Synthesis by Using External Data | Zack Hodari, Oliver Watts, Srikanth Ronanki and Simon King |
| 03.09.18 | 14:20 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-2 | 1227 | Investigating Accuracy of Pitch-accent Annotations in Neural Network-based Speech Synthesis and Denoising Effects | Hieu-Thi Luong, Xin Wang, Junichi Yamagishi and Nobuyuki Nishizawa |
| 03.09.18 | 14:40 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-3 | 1214 | An Exploration of Local Speaking Rate Variations in Mandarin Read Speech | Guan-Ting Liou, Chen-Yu Chiang, Yih-Ru Wang and Sin-Horng Chen |
| 03.09.18 | 15:00 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-4 | 1472 | BLSTM-CRF Based End-to-End Prosodic Boundary Prediction with Context Sensitive Embeddings in a Text-to-Speech Front-End | Yibin Zheng, Jianhua Tao, Zhengqi Wen and Ya Li |
| 03.09.18 | 15:20 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-5 | 1499 | Wavelet Analysis of Speaker Dependent and Independent Prosody for Voice Conversion | Berrak Sisman and Haizhou Li |
| 03.09.18 | 15:40 | Hall 1 | Prosody Modeling and Generation | Oral | Mon-O-1-2-6 | 1706 | Improving Mongolian Phrase Break Prediction by Using Syllable and Morphological Embeddings with BiLSTM Model | Rui Liu, Feilong Bao, Guanglai Gao, Hui Zhang and Yonghe Wang |
| 03.09.18 | 14:00 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-1 | 41 | Improved Supervised Locality Preserving Projection for I-vector Based Speaker Verification | Lanhua You, Wu Guo, Yan Song and Sheng Zhang |
| 03.09.18 | 14:20 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-2 | 1103 | Double Joint Bayesian Modeling of DNN Local I-Vector for Text Dependent Speaker Verification with Random Digit Strings | Ziqiang Shi, Huibin Lin, Liu Liu and Rujie Liu |
| 03.09.18 | 14:40 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-3 | 2128 | Fast Variational Bayes for Heavy-tailed PLDA Applied to I-vectors and X-vectors | Anna Silnova, Niko Brümmer, Daniel Garcia-Romero, David Snyder and Lukáš Burget |
| 03.09.18 | 15:00 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-4 | 2289 | Integrated Presentation Attack Detection and Automatic Speaker Verification: Common Features and Gaussian Back-end Fusion | Massimiliano Todisco, Héctor Delgado, Kong Aik Lee, Md Sahidullah, Nicholas Evans, Tomi Kinnunen and Junichi Yamagishi |
| 03.09.18 | 15:20 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-5 | 1280 | A Generalization of PLDA for Joint Modeling of Speaker Identity and Multiple Nuisance Conditions | Luciana Ferrer and Mitchell McLaren |
| 03.09.18 | 15:40 | Hall 2 | Speaker Verification I | Oral | Mon-O-1-3-6 | 2474 | An Investigation of Non-linear I-vectors for Speaker Verification | Nanxin Chen, Jesús Villalba and Najim Dehak |
| 03.09.18 | 14:00 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-1 | 1722 | CNN Based Query by Example Spoken Term Detection | Dhananjay Ram, Lesly Miculicich and Hervé Bourlard |
| 03.09.18 | 14:20 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-2 | 1010 | Learning Acoustic Word Embeddings with Temporal Context for Query-by-Example Speech Search | Yougen Yuan, Cheung-Chi Leung, Lei Xie, Hongjie Chen, Bin Ma and Haizhou Li |
| 03.09.18 | 14:40 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-3 | 1788 | Siamese Recurrent Auto-encoder Representation for Query-by-Example Spoken Term Detection | Ziwei Zhu, Zhiyong Wu, Runnan Li, Helen Meng and Lianhong Cai |
| 03.09.18 | 15:00 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-4 | 1459 | Fast Derivation of Cross-lingual Document Vectors from Self-attentive Neural Machine Translation Model | Wei Li and Brian Mak |
| 03.09.18 | 15:20 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-5 | 1016 | LSTM Based Attentive Fusion of Spectral and Prosodic Information for Keyword Spotting in Hindi Language | Laxmi Pandey and Karan Nathwani |
| 03.09.18 | 15:40 | MR G.01-G.02 | Spoken Term Detection | Oral | Mon-O-1-4-6 | 1436 | Spoken Keyword Detection Using Joint DTW-CNN | Ravi Shankar, Vikram C M and S R Mahadeva Prasanna |
| 03.09.18 | 14:00 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-1 | 51 | The INTERSPEECH 2018 Computational Paralinguistics Challenge: Atypical & Self-Assessed Affect, Crying & Heart Beats | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 14:10 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-2 | - | Heart Beat Sub-Challenge | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 14:20 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-3 | 2413 | An Ensemble of Transfer, Semi-supervised and Supervised Learning Methods for Pathological Heart Sound Classification | Ahmed Imtiaz Humayun, Md. Tauhiduzzaman Khan, Shabnam Ghaffarzadegan, Zhe Feng and Taufiq Hasan |
| 03.09.18 | 14:30 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-4 | - | Crying Sub-Challenge | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 14:40 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-5 | 2187 | Monitoring Infant’S Emotional Cry in Domestic Environments Using the Capsule Network Architecture | Mehmet Ali Tugtekin Turan and Engin Erzin |
| 03.09.18 | 14:50 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-6 | 1959 | Neural Network Architecture That Combines Temporal and Summative Features for Infant Cry Classification in the Interspeech 2018 Computational Paralinguistics Challenge | Mark Huckvale |
| 03.09.18 | 15:00 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-7 | 1914 | Evolving Learning for Analysing Mood-Related Infant Vocalisation | Zixing Zhang, Jing Han, Kun Qian and Björn Schuller |
| 03.09.18 | 15:10 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-8 | - | Atypical Affect Sub-Challenge | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 15:20 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-9 | 1238 | Deep Learning in Paralinguistic Recognition Tasks: Are Hand-crafted Features Still Relevant? | Johannes Wagner, Dominik Schiller, Andreas Seiderer and Elisabeth André |
| 03.09.18 | 15:30 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-10 | 1832 | Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition | Danqing Luo, Yuexian Zou and Dongyan Huang |
| 03.09.18 | 15:40 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-11 | 1401 | Using Voice Quality Supervectors for Affect Identification | Soo Jin Park, Amber Afshan, Zhi Ming Chua and Abeer Alwan |
| 03.09.18 | 15:50 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 1 | Oral | Mon-SS-1-1-12 | 2581 | An End-to-End Deep Learning Framework for Speech Emotion Recognition of Atypical Individuals | Dengke Tang, Junlin Zeng and Ming Li |
| 03.09.18 | 14:00 | MR G.05-G.06 | Show and Tell 1 | S&T | Mon-S&T-1-1-1 | 3002 | DialogOS: Simple and extensible dialogue modeling | Alexander Koller, Timo Baumann and Arne Köhn |
| 03.09.18 | 14:00 | MR G.05-G.06 | Show and Tell 1 | S&T | Mon-S&T-1-1-2 | 3003 | A Framework for Speech Recognition Benchmarking | Franck Dernoncourt, Trung Bui and Walter Chang |
| 03.09.18 | 14:00 | MR G.05-G.06 | Show and Tell 1 | S&T | Mon-S&T-1-1-3 | 3004 | Flexible tongue housed in a static model of the vocal tract with jaws, lips and teeth | Takayuki Arai |
| 03.09.18 | 14:00 | MR G.05-G.06 | Show and Tell 1 | S&T | Mon-S&T-1-1-4 | 3005 | Voice Analysis Using Acoustic and Throat Microphones for Speech Therapy | Lani Mathew and Gopakumar K. |
| 03.09.18 | 14:00 | MR G.05-G.06 | Show and Tell 1 | S&T | Mon-S&T-1-1-5 | 3006 | A Robust Context-Dependent Speech-to-Speech Phraselator Toolkit for Alexa | Manny Rayner, Nikos Tsourakis and Jan Stanek |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-1 | 1032 | Discriminating Nasals and Approximants in English Language Using Zero Time Windowing | RaviShankar Prasad, Sudarsana Reddy Kadiri, Suryakanth V Gangashetty and Bayya Yegnanarayana |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-2 | 1404 | Gestural Lenition of Rhotics Captures Variation in Brazilian Portuguese | Phil Howson and Alexei Kochetov |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-3 | 1958 | Identification and Classification of Fricatives in Speech Using Zero Time Windowing Method | RaviShankar Prasad and Bayya Yegnanarayana |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-4 | 1185 | GlobalTIMIT: Acoustic-Phonetic Datasets for the World’S Languages | Nattanun Chanchaochai, Christopher Cieri, Japhet Debrah, Hongwei Ding, Yue Jiang, Sishi Liao, Mark Liberman, Jonathan Wright, Jiahong Yuan, Juhong Zhan and Yuqing Zhan |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-5 | 1074 | Structural Effects on Properties of Consonantal Gestures in Tashlhiyt | Anne Hermes, Doris Mücke, Bastian Auris and Rachid Ridouane |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-6 | 1457 | The Retroflex-dental Contrast in Punjabi Stops and Nasals: a Principal Component Analysis of Ultrasound Images | Alexei Kochetov, Matthew Faytak and Kiranpreet Nara |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-7 | 1225 | Vowels and Diphthongs in Hangzhou Wu Chinese Dialect | Yang Yue and Fang Hu |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-8 | 1176 | Resyllabification in Indian Languages and Its Implications in Text-to-speech Systems | Mahesh M, Jeena JPrakash and Hema Murthy |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-9 | 2352 | Voice Source Contribution to Prominence Perception: Rd Implementation | Andy Murphy, Irena Yanushevskaya, Ailbhe Ní Chasaide and Christer Gobl |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-10 | 2532 | On the Relationship between Glottal Pulse Shape and Its Spectrum: Correlations of Open Quotient, Pulse Skew and Peak Flow with Source Harmonic Amplitudes | Christer Gobl, Andy Murphy, Irena Yanushevskaya and Ailbhe Ní Chasaide |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-11 | 1649 | The Individual and the System: Assessing the Stability of the Output of a Semi-automatic Forensic Voice Comparison System | Vincent Hughes, Philip Harrison, Paul Foulkes, Peter French, Colleen Kavanagh and Eugenia San Segundo Fernández |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-12 | 2498 | Breathy to Tense Voice Discrimination using Zero-Time Windowing Cepstral Coefficients (ZTWCCs) | Sudarsana Reddy Kadiri and Bayya Yegnanarayana |
| 03.09.18 | 14:00 | Hall 4-6: Poster1 | Speech Segments and Voice Quality | Poster | Mon-P-1-1-13 | 1899 | Analysis of Breathiness in Contextual Vowel of Voiceless Nasals in Mizo | Pamir Gogoi, Sishir Kalita, Parismita Gogoi, Ratree Wayland, Priyankoo Sarmah, S R Mahadeva Prasanna |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-1 | 2429 | Infant Emotional Outbursts Detection in Infant-parent Spoken Interactions | Yijia Xu, Mark Hasegawa-Johnson and Nancy McElwain |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-2 | 2466 | Deep Neural Networks for Emotion Recognition Combining Audio and Transcripts | Jaejin Cho, Raghavendra Pappagari, Purva Kulkarni, Jesús Villalba, Yishay Carmiel and Najim Dehak |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-3 | 2478 | Preference Learning with Qualitative Agreement for Sentence Level Emotional Annotations | Srinivas Parthasarathy and Carlos Busso |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-4 | 1625 | Transfer Learning for Improving Speech Emotion Classification Accuracy | Siddique Latif, Rajib Rana, Shahzad Younis, Junaid Qadir and Julien Epps |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-5 | 1851 | What Do Classifiers Actually Learn? a Case Study on Emotion Recognition Datasets | Patrick Meyer, Eric Buschermöhle and Tim Fingscheidt |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-6 | 2043 | State of Mind: Classification through Self-reported Affect and Word Use in Speech. | Eva-Maria Rathner, Yannik Terhorst, Nicholas Cummins, Björn Schuller and Harald Baumeister |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-7 | 1477 | Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition | Ziping Zhao, Yu Zheng, Zixing Zhang, Haishuai Wang, Yiqin Zhao and Chao Li |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-8 | 2015 | End-to-end Deep Neural Network Age Estimation | Pegah Ghahremani, Phani Sankar Nidadavolu, Nanxin Chen, Jesús Villalba, Daniel Povey, Sanjeev Khudanpur and Najim Dehak |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-9 | 1462 | Improving Gender Identification in Movie Audio Using Cross-Domain Data | Rajat Hebbar, Krishna Somandepalli and Shrikanth Narayanan |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-10 | 1240 | On Learning to Identify Genders from Raw Speech Signal Using CNNs | Selen Hande Kabil, Hannah Muckenhirn and Mathew Magimai.-Doss |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-11 | 2321 | Denoising and Raw-waveform Networks for Weakly-Supervised Gender Identification on Noisy Speech | Jilt Sebastian, Manoj Kumar, Pavan Kumar D. S., Mathew Magimai.-Doss, Hema Murthy and Shrikanth Narayanan |
| 03.09.18 | 14:00 | Hall 4-6: Poster2 | Speaker State and Trait | Poster | Mon-P-1-2-12 | 2372 | The Effect of Exposure to High Altitude and Heat on Speech Articulatory Coordination | James Williamson, Thomas Quatieri, Adam Lammert, Katherine Mitchell, Katherine Finkelstein, Nicole Ekon, Caitlin Dillon, Robert Kenefick and Kristin Heaton |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-1 | 1603 | Permutation Invariant Training of Generative Adversarial Network for Monaural Speech Separation | Lianwu Chen, Meng Yu, Yanmin Qian, Dan Su and Dong Yu |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-2 | 1205 | Deep Extractor Network for Target Speaker Recovery from Single Channel Speech Mixtures | Jun Wang, Jie Chen, Dan Su, Lianwu Chen, Meng Yu, Yanmin Qian and Dong Yu |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-3 | 1269 | Joint Localization and Classification of Multiple Sound Sources Using a Multi-task Neural Network | Weipeng He, Petr Motlicek and Jean-Marc Odobez |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-4 | 1281 | Detection of Glottal Closure Instants from Speech Signals: a Convolutional Neural Network Based Method | Shuai Yang, Zhiyong Wu, Binbin Shen and Helen Meng |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-5 | 1652 | Robust TDOA Estimation Based on Time-Frequency Masking and Deep Neural Networks | Zhong-Qiu Wang, Xueliang Zhang and DeLiang Wang |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-6 | 1671 | Waveform to Single Sinusoid Regression to Estimate the F0 Contour from Noisy Speech Using Recurrent Deep Neural Networks | Akihiro Kato and Tomi Kinnunen |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-7 | 1845 | Reducing Interference with Phase Recovery in DNN-based Monaural Singing Voice Separation | Paul Magron, Konstantinos Drossos, Stylianos Ioannis Mimilakis and Tuomas Virtanen |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-8 | 1258 | Nebula: F0 Estimation and Voicing Detection by Modeling the Statistical Properties of Feature Extractors | Kanru Hua |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-9 | 2290 | Real-time Single-channel Dereverberation and Separation with Time-domain Audio Separation Network | Yi Luo and Nima Mesgarani |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-10 | 2326 | Music Source Activity Detection and Separation Using Deep Attractor Network | Rajath Kumar, Yi Luo and Nima Mesgarani |
| 03.09.18 | 14:00 | Hall 4-6: Poster3 | Deep Learning for Source Separation and Pitch Tracking | Poster | Mon-P-1-3-11 | 2561 | Improving Mandarin Tone Recognition Using Convolutional Bidirectional Long Short-Term Memory with Attention | Longfei Yang, Yanlu Xie and Jinsong Zhang |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-1 | 68 | Vowel Space as a Tool to Evaluate Articulation Problems | Rob van Son, Catherine Middag and Kris Demuynck |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-2 | 1054 | Towards a Better Characterization of Parkinsonian Speech: a Multidimensional Acoustic Study | Veronique Delvaux, Kathy Huet, Myriam Piccaluga, Sophie van Malderen and Bernard Harmegnies |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-3 | 1125 | Self-similarity Matrix Based Intelligibility Assessment of Cleft Lip and Palate Speech | Sishir Kalita, S R Mahadeva Prasanna and Samarendra Dandapat |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-4 | 1251 | Pitch-Adaptive Front-end Feature for Hypernasality Detection | Akhilesh Kumar Dubey, S R Mahadeva Prasanna and S Dandapat |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-5 | 2389 | Detection of Amyotrophic Lateral Sclerosis (ALS) via Acoustic Analysis | Raquel Norel, Mary Pietrowicz, Carla Agurto, Shay Rishoni and Guillermo Cecchi |
| 03.09.18 | 14:00 | Hall 4-6: Poster4 | Acoustic Analysis-Synthesis of Speech Disorders | Poster | Mon-P-1-4-6 | 1665 | Detection of Glottal Activity Errors in Production of Stop Consonants in Children with Cleft Lip and Palate | Vikram C M, S R Mahadeva Prasanna, Ajish K Abraham, Pushpavathi M and Girish K S |
| 03.09.18 | 16:30 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-1 | 1392 | Cold Fusion: Training Seq2Seq Models Together with Language Models | Anuroop Sriram, Heewoo Jun, Sanjeev Satheesh and Adam Coates |
| 03.09.18 | 16:50 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-2 | 1766 | Investigation on Estimation of Sentence Probability by Combining Forward, Backward and Bi-directional LSTM-RNNs | Kazuki Irie, Zhihong Lei, Liuhui Deng, Ralf Schlüter and Hermann Ney |
| 03.09.18 | 17:10 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-3 | 2057 | Subword and Crossword Units for CTC Acoustic Models | Thomas Zenkel, Ramon Sanabria, Florian Metze and Alex Waibel |
| 03.09.18 | 17:30 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-4 | 1430 | Neural Error Corrective Language Models for Automatic Speech Recognition | Tomohiro Tanaka, Ryo Masumura, Hirokazu Masataki and Yushi Aono |
| 03.09.18 | 17:50 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-5 | 62 | Entity-Aware Language Model as an Unsupervised Reranker | Mohammad Sadegh Rasooli and Sarangarajan Parthasarathy |
| 03.09.18 | 18:10 | Hall 1 | ASR Systems and Technologies | Oral | Mon-O-2-1-6 | 1727 | Character-level Language Modeling with Gated Hierarchical Recurrent Neural Networks | Iksoo Choi, Jinhwan Park and Wonyong Sung |
| 03.09.18 | 16:30 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-1 | 2443 | Acoustic-Prosodic Indicators of Deception and Trust in Interview Dialogues | Sarah Ita Levitan, Angel Maredia and Julia Hirschberg |
| 03.09.18 | 16:50 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-2 | 2269 | Deep Personality Recognition for Deception Detection | Guozhen An, Sarah Ita Levitan, Julia Hirschberg and Rivka Levitan |
| 03.09.18 | 17:10 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-3 | 1373 | Cross-cultural (A)symmetries in Audio-visual Attitude Perception | Hansjörg Mixdorff, Albert Rilliard, Tan Lee, Matthew K. H. Ma and Angelika Hönemann |
| 03.09.18 | 17:30 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-4 | 1222 | An Active Feature Transformation Method for Attitude Recognition of Video Bloggers | Fasih Haider, Fahim A. Salim, Owen Conlan and Saturnino Luz |
| 03.09.18 | 17:50 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-5 | 1523 | Automatic Assessment of Individual Culture Attribute of Power Distance Using a Social Context-Enhanced Prosodic Network Representation | Fu-Sheng Tsai, Hao-Chun Yang, Wei-Wen Chang and Chi-Chun Lee |
| 03.09.18 | 18:10 | Hall 2 | Deception, Personality, and Culture Attribute | Oral | Mon-O-2-2-6 | 2502 | Analysis and Detection of Phonation Modes in Singing Voice using Excitation Source Features and Single Frequency Filtering Cepstral Coefficients (SFFCC) | Sudarsana Reddy Kadiri and Bayya Yegnanarayana |
| 03.09.18 | 16:30 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-1 | 1351 | A Deep Learning Method for Pathological Voice Detection Using Convolutional Deep Belief Networks | Huiyi Wu, John Soraghan, Anja Lowit and Gaetano Di-Caterina |
| 03.09.18 | 16:50 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-2 | 1754 | Dysarthric Speech Recognition Using Time-delay Neural Network Based Denoising Autoencoder | Chitralekha Bhat, Biswajit Das, Bhavik Vachhani and Sunil Kumar Kopparapu |
| 03.09.18 | 17:10 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-3 | 1988 | A Multitask Learning Approach to Assess the Dysarthria Severity in Patients with Parkinson's Disease | Juan Camilo Vásquez Correa, Tomas Arias, Juan Rafael Orozco-Arroyave and Elmar Noeth |
| 03.09.18 | 17:30 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-4 | 2398 | The Use of Machine Learning and Phonetic Endophenotypes to Discover Genetic Variants Associated with Speech Sound Disorder | Jason Lilley, Erin Crowgey and H Timothy Bunnell |
| 03.09.18 | 17:50 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-5 | 2391 | Whistle-blowing ASRs: Evaluating the Need for More Inclusive Speech Recognition Systems | Meredith Moore, Hemanth Venkateswara and Sethuraman Panchanathan |
| 03.09.18 | 18:10 | MR G.01-G.02 | Automatic Detection and Recognition of Voice and Speech Disorders | Oral | Mon-O-2-3-6 | 1751 | Data Augmentation Using Healthy Speech for Dysarthric Speech Recognition | Bhavik Vachhani, Chitralekha Bhat and Sunil Kumar Kopparapu |
| 03.09.18 | 16:30 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-1 | 1272 | Improving Sparse Representations in Exemplar-Based Voice Conversion with a Phoneme-Selective Objective Function | Shaojin Ding, Guanlong Zhao, Christopher Liberatore and Ricardo Gutierrez-Osuna |
| 03.09.18 | 16:50 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-2 | 1295 | Learning Structured Dictionaries for Exemplar-based Voice Conversion | Shaojin Ding, Christopher Liberatore and Ricardo Gutierrez-Osuna |
| 03.09.18 | 17:10 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-3 | 1662 | Exemplar-Based Spectral Detail Compensation for Voice Conversion | Yu-Huai Peng, Hsin-Te Hwang, Yichiao Wu, Yu Tsao and Hsin-Min Wang |
| 03.09.18 | 17:30 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-4 | 1487 | Whispered Speech to Neutral Speech Conversion Using Bidirectional LSTMs | G. Nisha Meenakshi and Prasanta Kumar Ghosh |
| 03.09.18 | 17:50 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-5 | 1504 | Voice Conversion across Arbitrary Speakers Based on a Single Target-Speaker Utterance | Songxiang Liu, Jinghua Zhong, Lifa Sun, Xixin Wu, Xunying Liu and Helen Meng |
| 03.09.18 | 18:10 | MR G.03-G.04 | Voice Conversion | Oral | Mon-O-2-4-6 | 1830 | Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations | Ju-chieh Chou, Cheng-chieh Yeh, Hung-yi Lee and Lin-shan Lee |
| 03.09.18 | 16:30 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-1 | - | Self-assessed Affect Sub-Challenge | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 16:42 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-2 | 1610 | Attention-based Sequence Classification for Affect Detection | Cristina Gorrostieta, Richard Brutti, Kye Taylor, Avi Shapiro, Joseph Moran, Ali Azarbayejani and John Kane |
| 03.09.18 | 16:54 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-3 | 2019 | Computational Paralinguistics: Automatic Assessment of Emotions, Mood and Behavioural State from Acoustics of Speech | Zafi Sherhan Syed, Julien Schroeter, Kirill Sidorov and David Marshall |
| 03.09.18 | 17:06 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-4 | 2149 | Investigating Utterance Level Representations for Detecting Intent from Acoustics | SaiKrishna Rallabandi, Bhavya Karki, Carla Viegas, Eric Nyberg and Alan W Black |
| 03.09.18 | 17:18 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-5 | 2298 | LSTM Based Cross-corpus and Cross-task Acoustic Emotion Recognition | Heysem Kaya, Dmitrii Fedotov, Ali Yeşilkanat, Oxana Verkholyak, Yang Zhang and Alexey Karpov |
| 03.09.18 | 17:30 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-6 | 2360 | Implementing Fusion Techniques for the Classification of Paralinguistic Information | Bogdan Vlasenko, Jilt Sebastian, Pavan Kumar D S and Mathew Magimai.-Doss |
| 03.09.18 | 17:42 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-7 | 1076 | General Utterance-Level Feature Extraction for Classifying Crying Sounds, Atypical & Self-Assessed Affect and Heart Beats | Gábor Gosztolya, Tamás Grósz and László Tóth |
| 03.09.18 | 17:54 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-8 | 2261 | Self-Assessed Affect Recognition Using Fusion of Attentional BLSTM and Static Acoustic Features | Bo-Hao Su, Sung-Lin Yeh, Ming-Ya Ko, Huan-Yu Chen, Shun-Chang Zhong, Jeng-Lin Li and Chi-Chun Lee |
| 03.09.18 | 18:06 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-9 | 1331 | Vocalic, Lexical and Prosodic Cues for the INTERSPEECH 2018 Self-Assessed Affect Challenge | Claude Montacié and Marie-José Caraty |
| 03.09.18 | 18:18 | MR 1.01-1.02 | The INTERSPEECH 2018 Computational Paralinguistics ChallengE (ComParE): Atypical & Self-Assessed Affect, Crying & Heart Beats 2 | Oral | Mon-SS-2-1-10 | - | The INTERSPEECH 2018 Computational Paralinguistics Challenge: Summary of result | Björn W. Schuller, Stefan Steidl, Anton Batliner, Peter B. Marschik, Harald Baumeister, Fengquan Dong, Simone Hantke, Florian B. Pokorny, Eva-Maria Rathner, Katrin D. Bartl-Pokorny, Christa Einspieler, Dajie Zhang, Alice Baird, Shahin Amiriparian, Kun Qian, Zhao Ren, Maximilian Schmitt, Panagiotis Tzirakis and Stefanos Zafeiriou |
| 03.09.18 | 16:30 | MR G.05-G.06 | Show and Tell 2 | S&T | Mon-S&T-2-1-1 | 3008 | Intonation tutor by SPIRE (In-SPIRE): An online tool for an automatic feedback to the second language learners in learning intonation | Anand P A, Chiranjeevi Yarra, Kausthubha N K and Prasanta Kumar Ghosh |
| 03.09.18 | 16:30 | MR G.05-G.06 | Show and Tell 2 | S&T | Mon-S&T-2-1-2 | 3045 | Game-based spoken dialog language learning applications for young students | Keelan Evanini, Veronika Timpe-Laughlin, Eugene Tsuprun, Ian Blood, Jeremy Lee, James Bruno, Vikram Ramanarayanan, Patrick Lange and David Suendermann-Oeft |
| 03.09.18 | 16:30 | MR G.05-G.06 | Show and Tell 2 | S&T | Mon-S&T-2-1-3 | 3011 | The IBM Virtual Voice Creator | Alexander Sorin, Slava Shechtman, Zvi Kons, Ron Hoory, Shay Ben-David, Joe Pavitt, Shai Rozenberg, Carmel Rabinovitz and Tal Drory |
| 03.09.18 | 16:30 | MR G.05-G.06 | Show and Tell 2 | S&T | Mon-S&T-2-1-4 | 3012 | Mobile Application for Learning Languages for the Unlettered | Gayathri G, Mohana N, Radhika Pal and Hema Murthy |
| 03.09.18 | 16:30 | MR G.05-G.06 | Show and Tell 2 | S&T | Mon-S&T-2-1-5 | 3014 | Mandarin-English Code-switching Speech Recognition | Haihua Xu, Van Tung Pham, Zin Tun Kyaw, Zhi Hao Lim, Eng Siong Chng and Haizhou Li |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-1 | 1581 | Joint Learning of Domain Classification and Out-of-Domain Detection with Dynamic Class Weighting for Satisficing False Acceptance Rates | Joo-Kyung Kim and Young-Bum Kim |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-2 | 2084 | Analyzing Vocal Tract Movements During Speech Accommodation | Sankar Mukherjee, Thierry Legou, Leonardo Lancia, Pauline Hilt, Alice Tomassini, Luciano Fadiga, Alessandro D'Ausilio, Leonardo Badino and Noël Nguyen |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-3 | 1039 | Cross-Lingual Multi-Task Neural Architecture for Spoken Language Understanding | Yujiang Li, Xuemin Zhao, Weiqun Xu and Yonghong Yan |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-4 | 1333 | Statistical Model Compression for Small-Footprint Natural Language Understanding | Grant P. Strimel, Kanthashree Mysore Sathyendra and Stanislav Peshterliev |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-5 | 1679 | Comparison of an End-to-end Trainable Dialogue System with a Modular Statistical Dialogue System | Norbert Braunschweiler and Alexandros Papangelis |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-6 | 1419 | A Discriminative Acoustic-Prosodic Approach for Measuring Local Entrainment | Megan Willi, Stephanie A. Borrie, Tyson S. Barrett, Ming Tu and Visar Berisha |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-7 | 2124 | Investigating Speech Features for Continuous Turn-Taking Prediction Using LSTMs | Matthew Roddy, Gabriel Skantze and Naomi Harte |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-8 | 1348 | Classification of Correction Turns in Multilingual Dialogue Corpus | Ivan Kraljevski and Diane Hirschfeld |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-9 | 1035 | Contextual Slot Carryover for Disparate Schemas | Chetan Naik, Arpit Gupta, Hancheng Ge, Mathias Lambert and Ruhi Sarikaya |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-10 | 1013 | Capsule Networks for Low Resource Spoken Language Understanding | Vincent Renkens and Hugo van Hamme |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-11 | 2436 | Intent Discovery through Unsupervised Semantic Text Clustering | Padmasundari and Srinivas Bangalore |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-12 | 2011 | Multimodal Polynomial Fusion for Detecting Driver Distraction | Yulun Du, Alan W Black, Louis-Philippe Morency and Maxine Eskenazi |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-13 | 2067 | Engagement Recognition in Spoken Dialogue via Neural Network by Aggregating Different Annotators' Models | Koji Inoue, Divesh Lala, Katsuya Takanashi and Tatsuya Kawahara |
| 03.09.18 | 16:30 | Hall 4-6: Poster1 | Spoken Dialogue Systems and Conversational Analysis | Poster | Mon-P-2-1-14 | 1254 | A First Investigation of the Timing of Turn-taking in Ruuli | Tuarik Buanzur, Margaret Zellers, Saudah Namyalo and Alena Witzlack-Makarevich |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-1 | 1042 | Spoofing Detection Using Adaptive Weighting Framework and Clustering Analysis | Yuanjun Zhao, Roberto Togneri and Victor Sreeram |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-2 | 1297 | Exploration of Compressed ILPR Features for Replay Attack Detection | Sarfaraz Jelil, Sishir Kalita, S R Mahadeva Prasanna and Rohit Sinha |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-3 | 1473 | Detection of Replay-Spoofing Attacks Using Frequency Modulation Features | Tharshini Gunendradasan, Buddhi Wickramasinghe, Ngoc Phu Le, Eliathamby Ambikairajah and Julien Epps |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-4 | 1675 | Effectiveness of Speech Demodulation-Based Features for Replay Detection | Madhu Kamble, Hemlata Tak and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-5 | 1687 | Novel Variable Length Energy Separation Algorithm Using Instantaneous Amplitude Features for Replay Detection | Madhu Kamble and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-6 | 1693 | Feature with Complementarity of Statistics and Principal Information for Spoofing Detection | Jichen Yang, Changhuai You and Qianhua He |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-7 | 2001 | Multiple Phase Information Combination for Replay Attacks Detection | Dongbo LI, Longbiao Wang, Jianwu Dang, Meng Liu, Zeyan Oo, Seiichi Nakagawa, Haotian Guan and Xiangang Li |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-8 | 1574 | Frequency Domain Linear Prediction Features for Replay Spoofing Attack Detection | Buddhi Wickramasinghe, Saad Irtza, Eliathamby Ambikairajah and Julien Epps |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-9 | 1651 | Auditory Filterbank Learning for Temporal Modulation Features in Replay Spoof Speech Detection | Hardik Sailor, Madhu Kamble and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-10 | 1819 | Deep Siamese Architecture Based Replay Detection for Secure Voice Biometric | Kaavya Sriskandaraja, Vidhyasaharan Sethu and Eliathamby Ambikairajah |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-11 | 1909 | A Deep Identity Representation for Noise Robust Spoofing Detection | Alejandro Gómez Alanís, Antonio M. Peinado, Jose A. Gonzalez and Angel Gomez |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-12 | 2279 | End-To-End Audio Replay Attack Detection Using Deep Convolutional Networks with Attention | Francis Tom, Mohit Jain and Prasenjit Dey |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-13 | 1494 | Decision-level Feature Switching as a Paradigm for Replay Attack Detection | Saranya M S and Hema Murthy |
| 03.09.18 | 16:30 | Hall 4-6: Poster2 | Spoofing Detection | Poster | Mon-P-2-2-14 | 1846 | Modulation Dynamic Features for the Detection of Replay Attacks | Gajan Suthokumar, Vidhyasaharan Sethu, Chamith Wijenayake and Eliathamby Ambikairajah |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-1 | 1062 | On the Usefulness of the Speech Phase Spectrum for Pitch Extraction | Erfan Loweimi, Jon Barker and Thomas Hain |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-2 | 1230 | Time-regularized Linear Prediction for Noise-robust Extraction of the Spectral Envelope of Speech | Manu Airaksinen, Lauri Juvela, Okko Räsänen and Paavo Alku |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-3 | 1536 | Auditory Filterbank Learning Using ConvRBM for Infant Cry Classification | Hardik B. Sailor and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-4 | 1538 | Effectiveness of Dynamic Features in INCA and Temporal Context-INCA | Nirmesh Shah and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-5 | 1224 | Singing Voice Phoneme Segmentation by Hierarchically Inferring Syllable and Phoneme Onset Positions | Rong Gong and Xavier Serra |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-6 | 1661 | Novel Empirical Mode Decomposition Cepstral Features for Replay Spoof Detection | Prasad Tapkir and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-7 | 1702 | Novel Linear Frequency Residual Cepstral Features for Replay Attack Detection | Hemlata Tak and Hemant Patil |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-8 | 1921 | Analysis of Sparse Representation Based Feature on Speech Mode Classification | Kumud Tripathi and K. Sreenivasa Rao |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-9 | 1937 | Multicomponent 2-D AM-FM Modeling of Speech Spectrograms | Jitendra Kumar Dhiman, Neeraj Sharma and Chandra Sekhar Seelamantula |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-10 | 1987 | An Optimization Framework for Recovery of Speech from Phase-Encoded Spectrograms | Abhilash Sainathan, Sunil Rudresh and Chandra Sekhar Seelamantula |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-11 | 2430 | Speaker Recognition with Nonlinear Distortion: Clipping Analysis and Impact | Wei Xia and John H.L. Hansen |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-12 | 1128 | Linear Prediction Residual Based Short-term Cepstral Features for Replay Attacks Detection | Madhusudan Singh and Debadatta Pati |
| 03.09.18 | 16:30 | Hall 4-6: Poster3 | Speech Analysis and Representation | Poster | Mon-P-2-3-13 | 1947 | Analysis of Variational Mode Functions for Robust Detection of Vowels | Surbhi Sakshi, Avinash Kumar and Gayadhar Pradhan |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-1 | 1030 | Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition | Chao Weng, Jia Cui, Guangsen Wang, Jun Wang, Chengzhu Yu, Dan Su and Dong Yu |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-2 | 1212 | Segmental Encoder-Decoder Models for Large Vocabulary Automatic Speech Recognition | Eugen Beck, Mirko Hannemann, Patrick Dötsch, Ralf Schlüter and Hermann Ney |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-3 | 1049 | Acoustic Modeling with DFSMN-CTC and Joint CTC-CE Learning | ShiLiang Zhang and Ming Lei |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-4 | 1888 | End-to-End Speech Command Recognition with Capsule Network | Jaesung Bae and Dae-Shik Kim |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-5 | 2414 | End-to-End Speech Recognition from the Raw Waveform | Neil Zeghidour, Nicolas Usunier, Gabriel Synnaeve, Ronan Collobert and Emmanuel Dupoux |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-6 | 1452 | A Multistage Training Framework for Acoustic-to-Word Model | Chengzhu Yu, Chunlei Zhang, Chao Weng, Jia Cui and Dong Yu |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-7 | 1107 | Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese | Shiyu Zhou, Linhao Dong, Shuang Xu and Bo Xu |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-8 | 1486 | Densely Connected Networks for Conversational Speech Recognition | Kyu Han, Akshay Chandrashekaran, Jungsuk Kim and Ian Lane |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-9 | 1655 | Multi-Head Decoder for End-to-End Speech Recognition | Tomoki Hayashi, Shinji Watanabe, Tomoki Toda and Kazuya Takeda |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-10 | 1543 | Compressing End-to-end ASR Networks by Tensor-Train Decomposition | Takuma Mori, Andros Tjandra, Sakriani Sakti and Satoshi Nakamura | 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-11 | 2341 | Speech2Vec: a Sequence-to-Sequence Framework for Learning Word Embeddings from Speech | Yu-An Chung and James Glass |
| 03.09.18 | 16:30 | Hall 4-6: Poster4 | Sequence Models for ASR | Poster | Mon-P-2-4-12 | 1086 | Extending Recurrent Neural Aligner for Streaming End-to-End Speech Recognition in Mandarin | Linhao Dong, Shiyu Zhou, Wei Chen and Bo Xu |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-1 | 1135 | Joint Noise and Reverberation Adaptive Learning for Robust Speaker DOA Estimation with an Acoustic Vector Sensor | Disong Wang and Yuexian Zou |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-2 | 1248 | Multiple Concurrent Sound Source Tracking Based on Observation-Guided Adaptive Particle Filter | Hong Liu, Haipeng Lan, Bing Yang and Cheng Pang |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-3 | 1310 | Harmonic-Percussive Source Separation of Polyphonic Music by Suppressing Impulsive Noise Events | Gurunath Reddy M, K Sreenivasa Rao and Partha Pratim Das |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-4 | 1606 | Speaker Activity Detection and Minimum Variance Beamforming for Source Separation | Enea Ceolini, Jithendar Anumula, Adrian Huber, Ilya Kiselev and Shih-Chii Liu |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-5 | 1615 | Sparsity-Constrained Weight Mapping for Head-Related Transfer Functions Individualization from Anthropometric Features | Xiaoke Qi and Jianhua Tao |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-6 | 1732 | Speech Source Separation Using ICA in Constant Q Transform Domain | Dheeraj Sai D.V.L.N, Kishor K.S and Sri Rama Murty Kodukula |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-7 | 1739 | Multi-talker Speech Separation Based on Permutation Invariant Training and Beamforming | Lu Yin, Ziteng Wang, Risheng Xia, Junfeng Li and Yonghong Yan |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-8 | 1840 | Expectation-Maximization Algorithms for Itakura-Saito Nonnegative Matrix Factorization | Paul Magron and Tuomas Virtanen |
| 03.09.18 | 16:30 | Hall 4-6: Poster5 | Source Separation and Spatial Analysis | Poster | Mon-P-2-5-9 | 2173 | Subband Weighting for Binaural Speech Source Localization | Karthik Girija Ramesan, Parth Suresh and Prasanta Kumar Ghosh |
| 04.09.18 | 08:30 | Hall 3 | Plenary Talk-1 | Oral | Tue-Plenary-1 | 4002 | Universal Tendencies for Cross-Linguistic Prosodic Tendencies: A Review and Some New Proposals | Jacqueline Vaissière |
| 04.09.18 | 10:00 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-1 | 1244 | Learning to Adapt: a Meta-learning Approach for Speaker Adaptation | Ondrej Klejch, Joachim Fainberg and Peter Bell |
| 04.09.18 | 10:20 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-2 | 2432 | Speaker Adaptation and Adaptive Training for Jointly Optimised Tandem Systems | Yu Wang, Chao Zhang, Mark Gales and Phil Woodland |
| 04.09.18 | 10:40 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-3 | 2022 | Comparison of BLSTM-Layer-Specific Affine Transformations for Speaker Adaptation | Markus Kitza, Ralf Schlüter and Hermann Ney |
| 04.09.18 | 11:00 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-4 | 1612 | Correlational Networks for Speaker Normalization in Automatic Speech Recognition | Rini A Sharon, Sandeep Reddy Kothinti and Umesh Srinivasan |
| 04.09.18 | 11:20 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-5 | 1558 | Machine Speech Chain with One-shot Speaker Adaptation | Andros Tjandra, Sakriani Sakti and Satoshi Nakamura |
| 04.09.18 | 11:40 | Hall 3 | Acoustic Model Adaptation | Oral | Tue-O-1-1-6 | 2246 | Domain Adaptation Using Factorized Hidden Layer for Robust Automatic Speech Recognition | Khe Chai Sim, Arun Narayanan, Ananya Misra, Anshuman Tripathi, Golan Pundak, Tara Sainath, Parisa Haghani, Bo Li and Michiel Bacchiani |
| 04.09.18 | 10:00 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-1 | 1154 | Waveform-Based Speaker Representations for Speech Synthesis | Moquan Wan, Gilles Degottex and Mark J.F. Gales |
| 04.09.18 | 10:20 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-2 | 1561 | Incremental TTS for Japanese Language | Tomoya Yanagita, Sakriani Sakti and Satoshi Nakamura |
| 04.09.18 | 10:40 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-3 | 1265 | Transfer Learning Based Progressive Neural Networks for Acoustic Modeling in Statistical Parametric Speech Synthesis | Ruibo Fu, Jianhua Tao, Yibin Zheng and Zhengqi Wen |
| 04.09.18 | 11:00 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-4 | 1590 | A Unified Framework for the Generation of Glottal Signals in Deep Learning-based Parametric Speech Synthesis Systems | Min-Jae Hwang, Eunwoo Song, Jin-Seob Kim and Hong-Goo Kang |
| 04.09.18 | 11:20 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-5 | 1598 | Acoustic Modeling Using Adversarially Trained Variational Recurrent Neural Network for Speech Synthesis | Joun Yeop Lee, Sung Jun Cheon, Byoung Jin Choi, Nam Soo Kim and Eunwoo Song |
| 04.09.18 | 11:40 | Hall 1 | Statistical Parametric Speech Synthesis | Oral | Tue-O-1-2-6 | 1970 | On the Application and Compression of Deep Time Delay Neural Network for Embedded Statistical Parametric Speech Synthesis | Yibin Zheng, Jianhua Tao, Zhengqi Wen and Ruibo Fu |
| 04.09.18 | 10:00 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-1 | 1377 | Integrating Recurrence Dynamics for Speech Emotion Recognition | Efthymios Tzinis, Georgios Paraskevopoulos, Christos Baziotis and Alexandros Potamianos |
| 04.09.18 | 10:20 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-2 | 1858 | Towards Temporal Modelling of Categorical Speech Emotion Recognition | Wenjing Han, Huabin Ruan, Xiaomin Chen, Zhixiang Wang, Haifeng Li and Björn Schuller |
| 04.09.18 | 10:40 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-3 | 1132 | Emotion Recognition from Human Speech Using Temporal Information and Deep Learning | John Kim and Rif A. Saurous |
| 04.09.18 | 11:00 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-4 | 2508 | Role of Regularization in the Prediction of Valence from Speech | Kusha Sridhar, Srinivas Parthasarathy and Carlos Busso |
| 04.09.18 | 11:20 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-5 | 1872 | Learning Spontaneity to Improve Emotion Recognition in Speech | Karttikeya Mangalam and Tanaya Guha |
| 04.09.18 | 11:40 | Hall 2 | Emotion Modeling | Oral | Tue-O-1-3-6 | 2464 | Predicting Categorical Emotions by Jointly Learning Primary and Secondary Emotions through Multitask Learning | Reza Lotfian and Carlos Busso |
| 04.09.18 | 10:00 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-1 | 1760 | Picture Naming or Word Reading: Does the Modality Affect Speech Motor Adaptation and Its Transfer? | Tiphaine Caudrelier, Pascal Perrier, Jean-Luc Schwartz and Amélie Rochet-Capellan |
| 04.09.18 | 10:20 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-2 | 1825 | Measuring the Band Importance Function for Mandarin Chinese with an Bayesian Adaptive Procedure | Yufan Du, Yi Shen, Hongying Yang, Xihong Wu and Jing Chen |
| 04.09.18 | 10:40 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-3 | 2420 | Wide Learning for Auditory Comprehension | Elnaz Shafaei-Bajestan and R. Harald Baayen |
| 04.09.18 | 11:00 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-4 | 1728 | Analyzing Reaction Time Sequences from Human Participants in Auditory Experiments | Louis ten Bosch, Mirjam Ernestus and Lou Boves |
| 04.09.18 | 11:20 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-5 | 1374 | Prediction of Perceived Speech Quality Using Deep Machine Listening | Jasper Ooster, Rainer Huber and Bernd T. Meyer |
| 04.09.18 | 11:40 | MR G.01-G.02 | Models of Speech Perception | Oral | Tue-O-1-4-6 | 1375 | Prediction of Subjective Listening Effort from Acoustic Data with Non-Intrusive Deep Models | Paul Kranzusch, Rainer Huber, Melanie Krüger, Birger Kollmeier and Bernd T. Meyer |
| 04.09.18 | 10:00 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-1 | 1293 | A Case Study on the Importance of Belief State Representation for Dialogue Policy Management | Margarita Kotti, Vassilios Diakoloukas, Alexandros Papangelis, Michail Lagoudakis and Yannis Stylianou |
| 04.09.18 | 10:20 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-2 | 1442 | Prediction of Turn-taking Using Multitask Learning with Prediction of Backchannels and Fillers | Kohei Hara, Koji Inoue, Katsuya Takanashi and Tatsuya Kawahara |
| 04.09.18 | 10:40 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-3 | 2527 | Conversational Analysis Using Utterance-level Attention-based Bidirectional Recurrent Neural Networks | Chandrakant Bothe, Sven Magg, Cornelius Weber and Stefan Wermter |
| 04.09.18 | 11:00 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-4 | 2005 | A Comparative Study of Statistical Conversion of Face to Voice Based on Their Subjective Impressions | Yasuhito Ohsugi, Daisuke Saito and Nobuaki Minematsu |
| 04.09.18 | 11:20 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-5 | 1007 | Follow-up Question Generation Using Pattern-based Seq2Seq with a Small Corpus for Interview Coaching | Ming-Hsiang Su, Chung-Hsien Wu, Kun-Yi Huang, Qian-Bei Hong and Huai-Hung Huang |
| 04.09.18 | 11:40 | MR G.03-G.04 | Multimodal Dialogue Systems | Oral | Tue-O-1-5-6 | 2446 | Coherence Models for Dialogue | Alessandra Cervone, Evgeny Stepanov and Giuseppe Riccardi |
| 04.09.18 | 10:00 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-1 | - | Introduction | - |
| 04.09.18 | 10:10 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-2 | 2529 | Indian languages ASR: A multilingual phone recognition framework with IPA based common phone-set, predicted articulatory features and feature fusion | Manjunath K E, K. Sreenivasa Rao, Dinesh Babu Jayagopi and V Ramasubramanian |
| 04.09.18 | 10:15 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-3 | 1139 | Rapid Collection of Spontaneous Speech Corpora Using Telephonic Community Forums | Agha Ali Raza, Awais Athar, Shan Randhawa, Zain Tariq, Muhammad Bilal Saleem, Haris Bin Zia, Umar Saif and Roni Rosenfeld |
| 04.09.18 | 10:20 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-4 | 1555 | Effect of TTS Generated Audio on OOV Detection and Word Error Rate in ASR for Low-resource Languages | Savitha Murthy, Dinkar Sitaram and Sunayana Sitaram |
| 04.09.18 | 10:25 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-5 | 2133 | Development of Large Vocabulary Speech Recognition System with Keyword Search for Manipuri | Tanvina Patel, Krishna DN, Noor Fathima, Nisar Shah, Mahima C, Deepak Kumar and Anuroop Iyengar |
| 04.09.18 | 10:30 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-6 | 2125 | Robust Mizo Continuous Speech Recognition | Abhishek Dey, Biswajit Dev Sarma, Wendy Lalhminghlui, Lalnunsiami Ngente, Parismita Gogoi, Priyankoo Sarmah, S R Mahadeva Prasanna, Rohit Sinha and Nirmala S.R. |
| 04.09.18 | 10:35 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-7 | 2486 | Semi-supervised and Active-learning Scenarios: Efficient Acoustic Model Refinement for a Low Resource Indian Language | Maharajan Chellapriyadharshini, Anoop Toffy, Srinivasa Raghavan K. M. and V Ramasubramanian |
| 04.09.18 | 10:40 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-8 | 2122 | Automatic Speech Recognition with Articulatory Information and a Unified Dictionary for Hindi, Marathi, Bengali, and Oriya | Debadatta Dash, Myungjong Kim, Kristin Teplansky and Jun Wang |
| 04.09.18 | 10:45 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Poster | Tue-SS-1-1-9 | - | All papers in this special session | - |
| 04.09.18 | 11:30 | MR 1.01-1.02 | Speech Recognition for Indian Languages | Oral | Tue-SS-1-1-10 | - | Discussion/Q&A | - |
| 04.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 3 | S&T | Tue-S&T-1-1-1 | 3015 | Captaina: Integrated pronunciation practice and data collection portal | Aku Rouhe, Reima Karhila, Aija Elg, Minnaleena Toivola, Peter Smit, Anna-Riikka Smolander and Mikko Kurimo |
| 04.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 3 | S&T | Tue-S&T-1-1-2 | 3016 | auMina - Enterprise Speech Analytics | Umesh Sachdev, Rajagopal Jayaraman and Zainab Millwala |
| 04.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 3 | S&T | Tue-S&T-1-1-3 | 3017 | HoloCompanion: An MR Friend for EveryOne | Annam Naresh, Rushabh Gandhi, Mallikarjuna Rao Bellamkonda and Mithun Das Gupta |
| 04.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 3 | S&T | Tue-S&T-1-1-4 | 3018 | akeira - Virtual Assistant | Umesh Sachdev, Rajagopal Jayaraman and Zainab Millwala |
| 04.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 3 | S&T | Tue-S&T-1-1-5 | 3019 | Brain-Computer Interface using Electroencephalogram signatures of Eye Blinks | Srihari Maruthachalam, Sidharth Aggarwal, Mari Ganesh Kumar, Mriganka Sur and Hema Murthy |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-1 | 61 | Voice Comparison and Rhythm: Behavioral Differences between Target and Non-target Comparisons | Moez Ajili, Jean-Francois Bonastre and Solange Rossato |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-2 | 1246 | Co-whitening of I-vectors for Short and Long Duration Speaker Verification | Longting Xu, Kong Aik Lee, Haizhou Li and Zhen Yang |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-3 | 1446 | Compensation for Domain Mismatch in Text-independent Speaker Recognition | Fahimeh Bahmaninezhad and John H.L. Hansen |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-4 | 1500 | Joint Learning of J-Vector Extractor and Joint Bayesian Model for Text Dependent Speaker Verification | Ziqiang Shi, Liu Liu, Huibin Lin and Rujie Liu |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-5 | 1422 | Latent Factor Analysis of Deep Bottleneck Features for Speaker Verification with Random Digit Strings | Ziqiang Shi, Huibin Lin, Liu Liu and Rujie Liu |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-6 | 1929 | VoxCeleb2: Deep Speaker Recognition | Joon Son Chung, Arsha Nagrani and Andrew Zisserman |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-7 | 2012 | Supervised I-vector Modeling - Theory and Applications | Shreyas Ramoji and Sriram Ganapathy |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-8 | 2412 | LOCUST - Longitudinal Corpus and Toolset for Speaker Verification | Evgeny Dmitriev, Yulia Kim, Anastasia Matveeva, Claude Montacié, Yannick Boulard, Yadviga Sinyavskaya, Yulia Zhukova, Adam Zarazinski, Egor Akhanov, Ilya Viksnin, Andrei Shlykov and Maria Usova |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-9 | 2071 | Analysis of Language Dependent Front-End for Speaker Recognition | Srikanth Madikeri, Subhadeep Dey and Petr Motlicek |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-10 | 2221 | Robust Speaker Recognition from Distant Speech under Real Reverberant Environments Using Speaker Embeddings | Mahesh Kumar Nandwana, Julien van Hout, Mitchell McLaren, Allen Stauffer, Colleen Richey, Aaron Lawson and Martin Graciarena |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-11 | 2394 | Investigation on Bandwidth Extension for Speaker Recognition | Phani Sankar Nidadavolu, Cheng-I Lai, Jesús Villalba and Najim Dehak |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-12 | 1696 | On Learning Vocal Tract System Related Speaker Discriminative Information from Raw Signal Using CNNs | Hannah Muckenhirn, Mathew Magimai.-Doss and Sebastien Marcel |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-13 | 1759 | On Convolutional LSTM Modeling for Joint Wake-Word Detection and Text Dependent Speaker Verification | Rajath Kumar, Vaishnavi Yeruva and Sriram Ganapathy |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-14 | 1593 | Cosine Metric Learning for Speaker Verification in the I-vector Space | Zhongxin Bai, Xiao-Lei Zhang and Jingdong Chen |
| 04.09.18 | 10:00 | Hall 4-6: Poster1 | Speaker Verification II | Poster | Tue-P-1-1-15 | 1363 | An Unsupervised Neural Prediction Framework for Learning Speaker Embeddings Using Recurrent Neural Networks | Arindam Jati and Panayiotis Georgiou |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-1 | 1223 | A New Framework for Supervised Speech Enhancement in the Time Domain | Ashutosh Pandey and Deliang Wang |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-2 | 1294 | Speech Enhancement Using the Minimum-probability-of-error Criterion | Jishnu Sadasivan, Subhadip Mukherjee and Chandra Sekhar Seelamantula |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-3 | 1387 | Exploring the Relationship between Conic Affinity of NMF Dictionaries and Speech Enhancement Metrics | Pavlos Papadopoulos, Colin Vaz and Shrikanth Narayanan |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-4 | 1650 | Using Shifted Real Spectrum Mask as Training Target for Supervised Speech Separation | Yun Liu, Hui Zhang and Xueliang Zhang |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-5 | 1928 | Enhancement of Noisy Speech Signal by Non-Local Means Estimation of Variational Mode Functions | Nagapuri Srinivas, Gayadhar Pradhan and Syed Shahnawazuddin |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-6 | 1950 | Phase-locked Loop Based Phase Estimation in Single Channel Speech Enhancement | Priya Pallavi and Ch V Rama Rao |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-7 | 2409 | Cycle-Consistent Speech Enhancement | Zhong Meng, Jinyu Li, Yifan Gong and Biing-Hwang (Fred) Juang |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-8 | 1955 | Visual Speech Enhancement | Aviv Gabbay, Asaph Shamir and Shmuel Peleg |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-9 | 2031 | Implementation of Digital Hearing Aid as a Smartphone Application | Saketh Sharma, Nitya Tiwari and Prem C. Pandey |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-10 | 1046 | Bone-Conduction Sensor Assisted Noise Estimation for Improved Speech Enhancement | Ching-Hua Lee, Bhaskar D. Rao and Harinath Garudadri |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-11 | 2213 | Artificial Bandwidth Extension with Memory Inclusion Using Semi-supervised Stacked Auto-encoders | Pramod Bachhav, Massimiliano Todisco and Nicholas Evans |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-12 | 2383 | Large Vocabulary Concatenative Resynthesis | Soumi Maiti, Joey Ching and Michael Mandel |
| 04.09.18 | 10:00 | Hall 4-6: Poster2 | Novel Approaches to Enhancement | Poster | Tue-P-1-2-13 | 2439 | Concatenative Resynthesis with Improved Training Signals for Speech Enhancement | Ali Raza Syed, Viet Anh Trinh and Michael Mandel |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-1 | 1047 | Comparison of Syllabification Algorithms and Training Strategies for Robust Word Count Estimation across Different Languages and Recording Conditions | Okko Räsänen, Seshadri Shreyas and Marisa Casillas |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-2 | 1115 | A Comparison of Input Types to a Deep Neural Network-based Forced Aligner | Matthew C. Kelley and Benjamin V. Tucker |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-3 | 1151 | Joint Learning Using Denoising Variational Autoencoders for Voice Activity Detection | Youngmoon Jung, Younggwan Kim, Yeunju Choi and Hoirin Kim |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-4 | 1203 | Information Bottleneck Based Percussion Instrument Diarization System for Taniavartanam Segments of Carnatic Music Concerts | Nauman Dawalatabad, Jom Kuriakose, Chandra Sekhar Chellu and Hema Murthy |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-5 | 1431 | Robust Voice Activity Detection Using Frequency Domain Long-Term Differential Entropy | Debayan Ghosh, Muralishankar R and Sanjeev Gurugopinath |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-6 | 1531 | Device-directed Utterance Detection | Sri Harish Mallidi, Roland Maas, Kyle Goehner, Ariya Rastrow, Spyros Matsoukas and Bjorn Hoffmeister |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-7 | 1692 | Acoustic-Prosodic Features of Tabla Bol Recitation and Correspondence with the Tabla Imitation | Rohit M A and Preeti Rao |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-8 | 1807 | Who Said That? a Comparative Study of Non-negative Matrix Factorization Techniques | Teun Krikke, Frank Broz and David Lane |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-9 | 2028 | AVA-Speech: a Densely Labeled Dataset of Speech Activity in Movies | Sourish Chaudhuri, Joseph Roth, Daniel P. W. Ellis, Andrew Gallagher, Liat Kaver, Radhika Marvin, Caroline Pantofaru, Nathan Reale, Loretta Guarino Reid, Kevin Wilson and Zhonghua Xi |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-10 | 2490 | Audiovisual Speech Activity Detection with Advanced Long Short-Term Memory | Fei Tao and Carlos Busso |
| 04.09.18 | 10:00 | Hall 4-6: Poster3 | Syllabification, Rhythm, and Voice Activity Detection | Poster | Tue-P-1-3-11 | 2537 | Towards Automatic Speech Identification from Vocal Tract Shape Dynamics in Real-time MRI | Pramit Saha, Praneeth Srungarapu and Sidney Fels |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-1 | 1057 | Structured Word Embedding for Low Memory Neural Network Language Model | Kaiyu Shi and Kai Yu |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-2 | 2185 | Role Play Dialogue Aware Language Models Based on Conditional Hierarchical Recurrent Encoder-Decoder | Ryo Masumura, Tomohiro Tanaka, Atsushi Ando, Hirokazu Masataki and Yushi Aono |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-3 | 1979 | Efficient Keyword Spotting Using Time Delay Neural Networks | Samuel Myer and Vikrant Singh Tomar |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-4 | 2062 | Automatic DNN Node Pruning Using Mixture Distribution-based Group Regularization | Tsukasa Yoshida, Takafumi Moriya, Kazuho Watanabe, Yusuke Shinohara, Yoshikazu Yamaguchi and Yushi Aono |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-5 | 2195 | Conditional Computation-Based Recurrent Neural Networks for Computationally Efficient Acoustic Modelling | Raffaele Tavarone and Leonardo Badino |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-6 | 2162 | Leveraging Translations for Speech Transcription in Low-resource Settings | Antonios Anastasopoulos and David Chiang |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-7 | 1381 | Sequence-to-sequence Neural Network Model with 2D Attention for Learning Japanese Pitch Accents | Antoine Bruguier, Heiga Zen and Arkady Arkhangorodsky |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-8 | 2211 | Task Specific Sentence Embeddings for ASR Error Detection | Sahar Ghannay, Yannick Estève and Nathalie Camelin |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-9 | 1055 | Low-Latency Neural Speech Translation | Jan Niehues, Ngoc-Quan Pham, Thanh-Le Ha, Matthias Sperber and Alex Waibel |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-10 | 1326 | Low-Resource Speech-to-Text Translation | Sameer Bansal, Herman Kamper, Karen Livescu, Adam Lopez and Sharon Goldwater |
| 04.09.18 | 10:00 | Hall 4-6: Poster4 | Selected Topics in Neural Speech Processing | Poster | Tue-P-1-4-11 | 2032 | VoiceGuard: Secure and Private Speech Processing | Ferdinand Brasser, Tommaso Frassetto, Korbinian Riedhammer, Ahmad-Reza Sadeghi, Thomas Schneider and Christian Weinert |
| 04.09.18 | 12:00 | Hall 3 | Perspective Talk-1 | Oral | Tue-Perspective-1 | 4005 | Deep Learning based Situated Goal-oriented Dialogue Systems | Dilek Hakkani-Tur |
| 04.09.18 | 12:30 | Hall 3 | Industry Presentation-1 | Tue-IP-1 | - | Industry Presentation by Amazon | Bjorn Hoffmeiester and Sri Garimella | |
| 04.09.18 | 12:30 | Hall 1 | Industry Presentation-2 | Tue-IP-2 | - | Industry Presentation by JD | Bowen Zhou | |
| 04.09.18 | 12:30 | Hall 2 | Industry Presentation-3 | Tue-IP-3 | - | Industry Presentation by Uniphore | Samith Ramachandran | |
| 04.09.18 | 14:30 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-1 | 1234 | Single-channel Speech Dereverberation via Generative Adversarial Training | Chenxing Li, Tieqiang Wang, Shuang Xu and Bo Xu |
| 04.09.18 | 14:50 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-2 | 1296 | Single-Channel Dereverberation Using Direct MMSE Optimization and Bidirectional LSTM Networks | Wolfgang Mack, Soumitro Chakrabarty, Fabian-Robert Stöter, Sebastian Braun, Bernd Edler and Emanuël Habets |
| 04.09.18 | 15:10 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-3 | 1660 | Single-channel Late Reverberation Power Spectral Density Estimation Using Denoising Autoencoders | Ina Kodrasi and Hervé Bourlard |
| 04.09.18 | 15:30 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-4 | 1834 | A Non-convolutive NMF Model for Speech Dereverberation | Nikhil M, Rajbabu Velmurugan and Preeti Rao |
| 04.09.18 | 15:50 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-5 | 2238 | Cross-Corpora Convolutional Deep Neural Network Dereverberation Preprocessing for Speaker Verification and Speech Enhancement | Peter Guzewich, Stephen Zahorian, Xiao Chen and Hao Zhang |
| 04.09.18 | 16:10 | Hall 3 | Dereverberation | Oral | Tue-O-2-1-6 | 2306 | Dereverberation and Beamforming in Robust Far-Field Speaker Recognition | Ladislav Mošner, Oldřich Plchot, Pavel Matějka, Ondřej Novotný and Jan Černocký |
| 04.09.18 | 14:30 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-1 | 990 | Comparing the Max and Noisy-Or Pooling Functions in Multiple Instance Learning for Weakly Supervised Sequence Learning Tasks | Yun Wang, Juncheng Li and Florian Metze |
| 04.09.18 | 14:50 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-2 | 2338 | A Simple Model for Detection of Rare Sound Events | Weiran Wang, Chieh-Chi Kao and Chao Wang |
| 04.09.18 | 15:10 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-3 | 1152 | Temporal Transformer Networks for Acoustic Scene Classification | Teng Zhang, Kailai Zhang and Ji Wu |
| 04.09.18 | 15:30 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-4 | 1552 | Temporal Attentive Pooling for Acoustic Event Detection | Xugang Lu, Peng Shen, Sheng Li, Yu Tsao and Hisashi Kawai |
| 04.09.18 | 15:50 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-5 | 2323 | R-CRNN: Region-based Convolutional Recurrent Neural Network for Audio Event Detection | Chieh-Chi Kao, Weiran Wang, Ming Sun and Chao Wang |
| 04.09.18 | 16:10 | Hall 1 | Audio Events and Acoustic Scenes | Oral | Tue-O-2-2-6 | 2559 | Detecting Media Sound Presence in Acoustic Scenes | Constantinos Papayiannis, Justice Amoh, Viktor Rozgic, Shiva Sundaram and Chao Wang |
| 04.09.18 | 14:30 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-1 | 1232 | S4D: Speaker Diarization Toolkit in Python | Pierre-Alexandre Broux, Florent Desnous, Anthony Larcher, Simon Petitrenaud, Jean Carrive and Sylvain Meignier |
| 04.09.18 | 14:50 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-2 | 1364 | Multimodal Speaker Segmentation and Diarization Using Lexical and Acoustic Cues via Sequence to Sequence Neural Networks | Tae Jin Park and Panayiotis Georgiou |
| 04.09.18 | 15:10 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-3 | 1654 | Combined Speaker Clustering and Role Recognition in Conversational Speech | Nikolaos Flemotomos, Pavlos Papadopoulos, James Gibson and Shrikanth Narayanan |
| 04.09.18 | 15:30 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-4 | 2324 | The ACLEW DiViMe: an Easy-to-use Diarization Tool | Adrien Le Franc, Eric Riebling, Julien Karadayi, Yun Wang, Camila Scaff, Florian Metze and Alejandrina Cristia |
| 04.09.18 | 15:50 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-5 | 1878 | Automatic Detection of Multi-speaker Fragments with High Time Resolution | Evdokia Kazimirova and Andrey Belyaev |
| 04.09.18 | 16:10 | Hall 2 | Speaker Diarization | Oral | Tue-O-2-3-6 | 1750 | Neural Speech Turn Segmentation and Affinity Propagation for Speaker Diarization | Ruiqing Yin, Hervé Bredin and Claude Barras |
| 04.09.18 | 14:30 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-1 | 1638 | Pitch or Phonation: on the Glottalization in Tone Productions in the Ruokeng Hui Chinese Dialect | Minghui Zhang and Fang Hu |
| 04.09.18 | 14:50 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-2 | 2288 | Speaker-specific Structure in German Voiceless Stop Voice Onset Times | Marc Antony Hullebus, Stephen Tobin and Adamantios Gafos |
| 04.09.18 | 15:10 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-3 | 2165 | Creak in the Respiratory Cycle | Kätlin Aare, Pärtel Lippus, Marcin Wlodarczak and Mattias Heldner |
| 04.09.18 | 15:30 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-4 | 2598 | Acoustic Analysis of Whispery Voice Disguise in Mandarin Chinese | Cuiling Zhang, Bin Li, Si Chen and Yike Yang |
| 04.09.18 | 15:50 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-5 | 1542 | The Zurich Corpus of Vowel and Voice Quality, Version 1.0 | Dieter Maurer, Christian d'Heureuse, Heidy Suter, Volker Dellwo, Daniel Friedrichs and Thayabaran Kathiresan |
| 04.09.18 | 16:10 | MR G.01-G.02 | Phonation | Oral | Tue-O-2-4-6 | 1677 | Weighting of Coda Voicing Cues: Glottalisation and Vowel Duration | Joshua Penney, Felicity Cox and Anita Szakay |
| 04.09.18 | 14:30 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-1 | 1908 | Revealing Spatiotemporal Brain Dynamics of Speech Production Based on EEG and Eye Movement | Bin Zhao, Jinfeng Huang, Gaoyan Zhang, Jianwu Dang, Minbo Chen, Yingjian Fu and Longbiao Wang |
| 04.09.18 | 14:50 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-2 | 2072 | Neural Response Development During Distributional Learning | Natalie Boll-Avetisyan, Jessie S. Nixon, Tomas O. Lentz, Liquan Liu, Sandrien van Ommen, Çağri Çöltekin and Jacolien van Rij |
| 04.09.18 | 15:10 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-3 | 2130 | Learning Two Tone Languages Enhances the Brainstem Encoding of Lexical Tones | Akshay Raj Maggu, Wenqing Zong, Vina Law and Patrick C. M. Wong |
| 04.09.18 | 15:30 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-4 | 2505 | Perceptual Sensitivity to Spectral Change in Australian English Close Front Vowels: an Electroencephalographic Investigation | Daniel Williams, Paola Escudero and Adamantios Gafos |
| 04.09.18 | 15:50 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-5 | 1024 | Effective Acoustic Cue Learning Is Not Just Statistical, It Is Discriminative | Jessie S. Nixon |
| 04.09.18 | 16:10 | MR G.03-G.04 | Cognition and Brain Studies | Oral | Tue-O-2-5-6 | 1676 | Analyzing EEG Signals in Auditory Speech Comprehension Using Temporal Response Functions and Generalized Additive Models | Kimberley Mulder, Louis ten Bosch and Lou Boves |
| 04.09.18 | 14:30 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-1 | 1896 | Information Encoding by Deep Neural Networks: What Can We Learn? | Louis ten Bosch and Lou Boves |
| 04.09.18 | 14:50 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-2 | 1034 | Scalable Factorized Hierarchical Variational Autoencoder Training | Wei-Ning Hsu and James Glass |
| 04.09.18 | 15:10 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-3 | 1153 | State Gradients for RNN Memory Analysis | Lyan Verwimp, Hugo van Hamme, Vincent Renkens and Patrick Wambacq |
| 04.09.18 | 15:30 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-4 | 2462 | Exploring How Phone Classification Neural Networks Learn Phonetic Information by Visualising and Interpreting Bottleneck Features | Linxue Bai, Philip Weber, Peter Jančovič and Martin Russell |
| 04.09.18 | 15:50 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-5 | 2082 | Memory Time Span in LSTMs for Multi-Speaker Source Separation | Jeroen Zegers and Hugo van Hamme |
| 04.09.18 | 16:10 | MR 1.01-1.02 | Deep Neural Networks: How Can We Interpret What They Learned? | Oral | Tue-SS-2-1-6 | 1707 | Visualizing Phoneme Category Adaptation in Deep Neural Networks | Odette Scharenborg, Sebastian Tiesmeyer, Mark Hasegawa-Johnson and Najim Dehak |
| 04.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 4 | S&T | Tue-S&T-2-1-1 | 3022 | Early vocabulary development through picture-based software solutions | Kasthuri G, Prabha Ramanathan, Hema Murthy, Namita Jacob and Anil Prabhakar |
| 04.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 4 | S&T | Tue-S&T-2-1-2 | 3026 | Automatic detection of expressiveness in oral reading | Kamini Sabu, Kanhaiya Kumar and Preeti Rao |
| 04.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 4 | S&T | Tue-S&T-2-1-3 | 3027 | PannoMulloKathan: Voice enabled Mobile App for Agricultural Commodity Price Dissemination in Bengali Language | Madhab Pal, Rajib Roy, Soma Khan, Milton S. Bepari and Joyanta Basu |
| 04.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 4 | S&T | Tue-S&T-2-1-4 | 3028 | Visualizing Punctuation Restoration in Speech Transcripts with Prosograph | Alp Öktem, Mireia Farrús and Antonio Bonafonte |
| 04.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 4 | S&T | Tue-S&T-2-1-5 | 3029 | CACTAS - Collaborative Audio Categorization and Transcription for ASR Systems | Mithul Mathivanan, Kinnera Saranu, Abhishek Pandey and Jithendra Vepa |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-1 | 2087 | FACTS: a Hierarchical Task-based Control Model of Speech Incorporating Sensory Feedback | Benjamin Parrell, Vikram Ramanarayanan, Srikantan Nagarajan and John Houde |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-2 | 2592 | Sensorimotor response to tongue displacement imagery by talkers with Parkinson’s disease | William Katz, Patrick Reidy and Divya Prabhakaran |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-3 | 1267 | Automatic Pronunciation Evaluation of Singing | Chitralekha Gupta, Haizhou Li and Ye Wang |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-4 | 2299 | Classification of Nonverbal Human Produced Audio Events: a Pilot Study | Rachel E. Bouserhal, Philippe Chabot, Milton Sarria-Paja, Patrick Cardinal and Jeremie Voix |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-5 | 995 | UltraFit: a Speaker-friendly Headset for Ultrasound Recordings in Speech Sciences | Lorenzo Spreafico, Michael Pucher and Anna Matosova |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-6 | 1038 | Articulatory Consequences of Vocal Effort Elicitation Method | Elisabet Eir Cortes, Marcin Wlodarczak and Juraj Šimko |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-7 | 1233 | Age-related Effects on Sensorimotor Control of Speech Production | Anne Hermes, Jane Mertens and Doris Mücke |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-8 | 2512 | An Ultrasound Study of Gemination in Coronal Stops in Eastern Oromo | Maida Percival, Alexei Kochetov and Yoonjung Kang |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-9 | 1646 | Processing Transition Regions of Glottal Stop Substituted /S/ for Intelligibility Enhancement of Cleft Palate Speech | Protima Nomo Sudro, Sishir Kalita and S R Mahadeva Prasanna |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-10 | 1907 | Reconstructing Neutral Speech from Tracheoesophageal Speech | Abinay Reddy N, Achuth Rao MV, G. Nisha Meenakshi and Prasanta Kumar Ghosh |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-11 | 2544 | Automatic Evaluation of Soft Articulatory Contact for Stuttering Treatment | Keiko Ochi, Koichi Mori and Naomi Sakai |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-12 | 1575 | Korean Singing Voice Synthesis Based on LSTM Recurrent Neural Network | Juntae Kim, Heejin Choi, Jinuk Park, Minsoo Hahn, Sangjin Kim and Jong-Jin Kim |
| 04.09.18 | 14:30 | Hall 4-6: Poster1 | Speech and Singing Production | Poster | Tue-P-2-1-13 | 60 | The Trajectory of Voice Onset Time with Vocal Aging | Chen Xuanda, Xiong Ziyu and Hu Jian |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-1 | 1768 | The Fifth `CHiME' Speech Separation and Recognition Challenge: Dataset, Task and Baselines | Jon Barker, Shinji Watanabe, Emmanuel Vincent and Jan Trmal |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-2 | 1454 | Voices Obscured in Complex Environmental Settings (VOiCES) Corpus | Colleen Richey and Maria A. Barrios, Zeb Armstrong, Chris Bartels, Horacio Franco, Martin Graciarena, Aaron Lawson, Mahesh Kumar Nandwana, Allen Stauffer, Julien van Hout, Paul Gamble, Jeffrey Hetherly, Cory Stephenson and Karl Ni |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-3 | 1262 | Building State-of-the-art Distant Speech Recognition Using the CHiME-4 Challenge with a Setup of Speech Enhancement Baseline | Szu-Jui Chen, Aswin Shanmugam Subramanian, Hainan Xu and Shinji Watanabe |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-4 | 1097 | Unsupervised Adaptation with Interpretable Disentangled Representations for Distant Conversational Speech Recognition | Wei-Ning Hsu, Hao Tang and James Glass |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-5 | 1780 | Investigating Generative Adversarial Networks Based Speech Dereverberation for Robust Speech Recognition | Ke Wang, Junbo Zhang, Sining Sun, Yujun Wang, Fei Xiang and Lei Xie |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-6 | 1547 | Monaural Multi-Talker Speech Recognition with Attention Mechanism and Gated Convolutional Networks | Xuankai Chang, Yanmin Qian and Dong Yu |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-7 | 1721 | Weighting Time-Frequency Representation of Speech Using Auditory Saliency for Automatic Speech Recognition | Cong-Thanh Do and Yannis Stylianou |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-8 | 1453 | Acoustic Modeling from Frequency Domain Representations of Speech | Pegah Ghahremani, Hossein Hadian, Hang Lv, Daniel Povey and Sanjeev Khudanpur |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-9 | 1828 | Non-Uniform Spectral Smoothing for Robust Children's Speech Recognition | Ishwar Chandra Yadav, Avinash Kumar, Syed Shahnawazuddin and Gayadhar Pradhan |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-10 | 1134 | Bidirectional Long-Short Term Memory Network-based Estimation of Reliable Spectral Component Locations | Aaron Nicolson and Kuldip K. Paliwal |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-11 | 2156 | Speech Emotion Recognition by Combining Amplitude and Phase Information Using Convolutional Neural Network | Lili Guo, Longbiao Wang, Jianwu Dang, Linjuan Zhang, Haotian Guan and Xiangang Li |
| 04.09.18 | 14:30 | Hall 4-6: Poster2 | Robust Speech Recognition | Poster | Tue-P-2-2-12 | 2377 | Bubble Cooperative Networks for Identifying Important Speech Cues | Viet Anh Trinh, Brian McFee and Michael I Mandel |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-1 | 34 | Real-Time Scoring of an Oral Reading Assessment on Mobile Devices | Jian Cheng |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-2 | 1087 | A Deep Learning Approach to Assessing Non-native Pronunciation of English Using Phone Distances | Konstantinos Kyriakopoulos, Kate Knill and Mark Gales |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-3 | 1270 | Paired Phone-Posteriors Approach to ESL Pronunciation Quality Assessment | Yujia Xiao, Frank Soong and Wenping Hu |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-4 | 1350 | Investigating the Role of L1 in Automatic Pronunciation Evaluation of L2 Speech | Ming Tu, Anna Grabek, Julie Liss and Visar Berisha |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-5 | 1312 | Impact of ASR Performance on Free Speaking Language Assessment | Kate Knill, Mark Gales, Konstantinos Kyriakopoulos, Andrey Malinin, Anton Ragni, Yu Wang and Andrew Caines |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-6 | 1644 | Automatic Miscue Detection Using RNN Based Models with Data Augmentation | Yoon Seok Hong, Kyung Seo Ki and Gahgene Gweon |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-7 | 1860 | A Study of Objective Measurement of Comprehensibility through Native Speakers' Shadowing of Learners' Utterances | Yusuke Inoue, Suguru Kabashima, Daisuke Saito, Nobuaki Minematsu, Kumi Kanamura and Yutaka Yamauchi |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-8 | 2138 | Factorized Deep Neural Network Adaptation for Automatic Scoring of L2 Speech in English Speaking Tests | Dean Luo, Chunxiao Zhang, Linzhong Xia and Lixin Wang |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-9 | 2297 | On the Difficulties of Automatic Speech Recognition for Kindergarten-Aged Children | Gary Yeung and Abeer Alwan |
| 04.09.18 | 14:30 | Hall 4-6: Poster3 | Applications in Education and Learning | Poster | Tue-P-2-3-10 | 2118 | Improved Acoustic Modelling for Automatic Literacy Assessment of Children | Mauro Nicolao, Michiel Sanders and Thomas Hain |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-1 | 1319 | Anomaly Detection Approach for Pronunciation Verification of Disordered Speech Using Speech Attribute Features | Mostafa Shahin, Beena Ahmed, Jim X. Ji and Kirrie Ballard |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-2 | 1399 | Effectiveness of Voice Quality Features in Detecting Depression | Amber Afshan, Jinxi Guo, Soo Jin Park, Vijay Ravi, Jonathan Flint and Abeer Alwan |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-3 | 1465 | Fusing Text-dependent Word-level i-Vector Models to Screen ‘at Risk’ Child Speech | Prasanna Kothalkar, Johanna Rudolph, Christine Dollaghan, Jennifer McGlothlin, Thomas Campbell and John H.L. Hansen |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-4 | 1471 | Testing Paradigms for Assistive Hearing Devices in Diverse Acoustic Environments | Ram Charan Chandra Shekar, Hussnain Ali and John H.L. Hansen |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-5 | 1514 | Detection of Dementia from Responses to Atypical Questions Asked by Embodied Conversational Agents | Tsuyoki Ujiro, Hiroki Tanaka, Hiroyoshi Adachi, Hiroaki Kazui, Manabu Ikeda, Takashi Kudo and Satoshi Nakamura |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-6 | 1521 | Acoustic Features Associated with Sustained Vowel and Continuous Speech Productions by Chinese Children with Functional Articulation Disorders | Wang Zhang, Xiangqian Gui, Tianqi Wang, Feng Yang, Lan Wang, Manwa Ng and Nan Yan |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-7 | 1631 | Estimation of Hypernasality Scores from Cleft Lip and Palate Speech | Vikram C M, Ayush Tripathi, Sishir Kalita and S R Mahadeva Prasanna |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-8 | 1713 | Detecting Alzheimer’s Disease Using Gated Convolutional Neural Network from Audio Data | Tifani Warnita, Nakamasa Inoue and Koichi Shinoda |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-9 | 2475 | Automatic Detection of Orofacial Impairment in Stroke | Andrea Bandini, Jordan Green, Brian Richburg and Yana Yunusova |
| 04.09.18 | 14:30 | Hall 4-6: Poster4 | Integrating Speech Science and Technology for Clinical Applications | Poster | Tue-SS-2-2-10 | 2522 | Detecting Depression with Audio/Text Sequence Modeling of Interviews | Tuka Al Hanai, Mohammad Ghassemi and James Glass |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-1 | 2129 | Discourse Marker Detection for Hesitation Events on Mandarin Conversation | Yu-Wun Wang, Hen-Hsen Huang, Kuan-Yu Chen and Hsin-Hsi Chen |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-2 | 2225 | Acoustic and Perceptual Characteristics of Mandarin Speech in Homosexual and Heterosexual Male Speakers | Puyang Geng, Wentao Gu and Hiroya Fujisaki |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-3 | 1755 | Automatic Question Detection from Acoustic and Phonetic Features Using Feature-wise Pre-training | Atsushi Ando, Reine Asakawa, Ryo Masumura, Hosana Kamiyama, Satoshi Kobashikawa and Yushi Aono |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-4 | 2310 | Improving Response Time of Active Speaker Detection Using Visual Prosody Information Prior to Articulation | Fasih Haider, Saturnino Luz, Carl Vogel and Nick Campbell |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-5 | 2215 | Audio-Visual Prediction of Head-Nod and Turn-Taking Events in Dyadic Interactions | Bekir Berker Türker, Engin Erzin, Yücel Yemez and Metin Sezgin |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-6 | 1425 | Analyzing Effect of Physical Expression on English Proficiency for Multimodal Computer-Assisted Language Learning | Haoran Wu, Yuya Chiba, Takashi Nose and Akinori Ito |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-7 | 2090 | Analysis of the Effect of Speech-Laugh on Speaker Recognition System | Sri Harsha Dumpala, Ashish Panda and Sunil Kumar Kopparapu |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-8 | 2418 | Vocal Biomarkers for Cognitive Performance Estimation in a Working Memory Task | Jennifer Sloboda, Adam Lammert, James Williamson, Christopher Smalt, Daryush D. Mehta, COL Ian Curry, Kristin Heaton, Jeffrey Palmer and Thomas Quatieri |
| 04.09.18 | 14:30 | Hall 4-6: Poster5 | Speaker Characterization and Analysis | Poster | Tue-P-2-5-9 | 2263 | Lexical and Acoustic Deep Learning Model for Personality Recognition | Guozhen An and Rivka Levitan |
| 04.09.18 | 17:00 | Hall 3 | Perspective Talk-2 | Oral | Tue-Perspective-2 | 4006 | Open Problems in Speech Recognition | Bhuvana Ramabhadran |
| 04.09.18 | 08:30 | Hall 3 | Plenary Talk-2 | Oral | Wed-Plenary-2 | 4003 | Evolution of Neural Network Architectures for Speech Recognition | Hervé Bourlard |
| 05.09.18 | 10:00 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-1 | 1485 | Layer Trajectory LSTM | Jinyu Li, Changliang Liu and Yifan Gong |
| 05.09.18 | 10:20 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-2 | 2158 | Semi-tied Units for Efficient Gating in LSTM and Highway Networks | Chao Zhang and Phil Woodland |
| 05.09.18 | 10:40 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-3 | 1823 | Gaussian Process Neural Networks for Speech Recognition | Max W. Y. Lam, Shoukang Hu, Xurong Xie, Shansong Liu, Jianwei Yu, Rongfeng Su, Xunying Liu and Helen Meng |
| 05.09.18 | 11:00 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-4 | 1089 | Acoustic Modeling with Densely Connected Residual Network for Multichannel Speech Recognition | Jian Tang, Yan Song, Lirong Dai and Ian McLoughlin |
| 05.09.18 | 11:20 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-5 | 1544 | Gated Recurrent Unit Based Acoustic Modeling with Future Context | Jie Li, Xiaorui Wang, Yuanyuan Zhao and Yan Li |
| 05.09.18 | 11:40 | Hall 3 | Novel Neural Network Architectures for Acoustic Modelling | Oral | Wed-O-1-1-6 | 1403 | Output-Gate Projected Gated Recurrent Unit for Speech Recognition | Gaofeng Cheng, Daniel Povey, Lu Huang, Ji Xu, Sanjeev Khudanpur and Yonghong Yan |
| 05.09.18 | 10:00 | Hall 1 | Language Identification | Oral | Wed-O-1-2-1 | 69 | Performance Analysis of the 2017 NIST Language Recognition Evaluation | Seyed Omid Sadjadi, Timothee Kheyrkhah, Craig Greenberg, Douglas Reynolds, Elliot Singer, Lisa Mason and Jaime Hernandez-Cordero |
| 05.09.18 | 10:20 | Hall 1 | Language Identification | Oral | Wed-O-1-2-2 | 1165 | Using Deep Neural Networks for Identification of Slavic Languages from Acoustic Signal | Lukas Mateju, Petr Cerva, Jindrich Zdansky and Radek Safarik |
| 05.09.18 | 10:40 | Hall 1 | Language Identification | Oral | Wed-O-1-2-3 | 1342 | Adding New Classes without Access to the Original Training Data with Applications to Language Identification | Hagai Taitelbaum, Ehud Ben-Reuven and Jacob Goldberger |
| 05.09.18 | 11:00 | Hall 1 | Language Identification | Oral | Wed-O-1-2-4 | 1519 | Feature Representation of Short Utterances Based on Knowledge Distillation for Spoken Language Identification | Peng Shen, Xugang Lu, Sheng Li and Hisashi Kawai |
| 05.09.18 | 11:20 | Hall 1 | Language Identification | Oral | Wed-O-1-2-5 | 1805 | Sub-band Envelope Features Using Frequency Domain Linear Prediction for Short Duration Language Identification | Sarith Fernando, Vidhyasaharan Sethu and Eliathamby Ambikairajah |
| 05.09.18 | 11:40 | Hall 1 | Language Identification | Oral | Wed-O-1-2-6 | 2458 | Effectiveness of Single-Channel BLSTM Enhancement for Language Identification | Peter Sibbern Frederiksen, Jesús Villalba, Shinji Watanabe, Zheng-Hua Tan and Najim Dehak |
| 05.09.18 | 10:00 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-1 | 1384 | Articulation Rate as a Speaker Discriminant in British English | Erica Gold |
| 05.09.18 | 10:20 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-2 | 2513 | Truncation and Compression in Southern German and Australian English | Jenny Yu and Katharina Zahner |
| 05.09.18 | 10:40 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-3 | 1873 | Prominence-based Evaluation of L2 Prosody | Heini Kallio, Antti Suni, Päivi Virkkunen and Juraj Šimko |
| 05.09.18 | 11:00 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-4 | 1060 | Length Contrast and Covarying Features: Whistled Speech as a Case Study | Rachid Ridouane, Giuseppina Turco and Julien Meyer |
| 05.09.18 | 11:20 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-5 | 1529 | Information Structure, Affect, and Prenuclear Prominence in American English | Eleanor Chodroff and Jennifer Cole |
| 05.09.18 | 11:40 | Hall 2 | Production of Prosody | Oral | Wed-O-1-3-6 | 63 | Effects of User Controlled Speech Rate on Intelligibility in Noisy Environments | John S. Novak and Robert V. Kenyon |
| 05.09.18 | 10:00 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-1 | 27 | Binaural Speech Intelligibility Estimation Using Deep Neural Networks | Kazuhiro Kondo, Kazuya Taira and Yosuke Kobayashi |
| 05.09.18 | 10:20 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-2 | 1291 | Multi-resolution Gammachirp Envelope Distortion Index for Intelligibility Prediction of Noisy Speech | Katsuhiko Yamamoto, Toshio Irino, Narumi Ohashi, Shoko Araki, Keisuke Kinoshita and Tomohiro Nakatani |
| 05.09.18 | 10:40 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-3 | 2119 | Speech Intelligibility Enhancement Based on a Non-causal Wavenet-like Model | Muhammed Shifas PV, Vassilis Tsiaras and Yannis Stylianou |
| 05.09.18 | 11:00 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-4 | 1802 | Quality-Net: an End-to-End Non-intrusive Speech Quality Assessment Model Based on BLSTM | Szu-wei Fu, Yu Tsao, Hsin-Te Hwang and Hsin-Min Wang |
| 05.09.18 | 11:20 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-5 | 1884 | Global Snr Estimation of Speech Signals Using Entropy and Uncertainty Estimates from Dropout Networks | Rohith Aralikatti, Dilip Kumar Margam, Tanay Sharma, Abhinav Thanda and Shankar Venkatesan |
| 05.09.18 | 11:40 | MR G.01-G.02 | Speech Intelligibility and Quality | Oral | Wed-O-1-4-6 | 1098 | Detecting Packet-Loss Concealment Using Formant Features and Decision Tree Learning | Gabriel Mittag and Sebastian Möller |
| 05.09.18 | 10:00 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-1 | 1736 | UltraSuite: a Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions | Aciel Eshky, Manuel Sam Ribeiro, Joanne Cleland, Korin Richmond, Zoe Roxburgh, James M Scobbie and Alan Wrench |
| 05.09.18 | 10:20 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-2 | 1764 | Detecting Signs of Dementia Using Word Vector Representations | Bahman Mirheidari, Daniel Blackburn, Traci Walker, Annalena Venneri, Markus Reuber and Heidi Christensen |
| 05.09.18 | 10:40 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-3 | 2029 | Classification of Huntington Disease Using Acoustic and Lexical Features | Matthew Perez, Wenyu Jin, Duc Le, Noelle Carlozzi, Praveen Dayalu, Angela Roberts and Emily Mower Provost |
| 05.09.18 | 11:00 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-4 | 2355 | The PRIORI Emotion Dataset: Linking Mood to Emotion Detected In-the-Wild | Soheil Khorram, Mimansa Jaiswal, John Gideon, Melvin McInnis and Emily Mower Provost |
| 05.09.18 | 11:20 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-5 | 1518 | Language Features for Automated Evaluation of Cognitive Behavior Psychotherapy Sessions | Nikolaos Flemotomos, Victor Martinez, James Gibson, David Atkins, Torrey Creed and Shrikanth Narayanan |
| 05.09.18 | 11:40 | MR G.03-G.04 | Integrating Speech Science and Technology for Clinical Applications | Oral | Wed-SS-1-1-6 | 2496 | Automatic Early Detection of Amyotrophic Lateral Sclerosis from Intelligible Speech Using Convolutional Neural Networks | Kwanghoon An, Myungjong Kim, Kristin Teplansky, Jordan Green, Thomas Campbell, Yana Yunusova, Daragh Heitzman and Jun Wang |
| 05.09.18 | 10:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Oral | Wed-SS-1-2-1 | 1600 | A Study of Lexical and Prosodic Cues to Segmentation in a Hindi-English Code-switched Discourse | Preeti Rao, Mugdha Pandya, Kamini Sabu, Kanhaiya Kumar and Nandini Bondale |
| 05.09.18 | 10:20 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Oral | Wed-SS-1-2-2 | 1966 | Building a Unified Code-Switching ASR System for South African Languages | Emre Yilmaz, Astik Biswas, Ewald van der Westhuizen, Febe de Wet and Thomas Niesler |
| 05.09.18 | 10:40 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Oral | Wed-SS-1-2-3 | 1974 | Study of Semi-supervised Approaches to Improving English-Mandarin Code-Switching Speech Recognition | Pengcheng Guo, Haihua Xu, Lei Xie and Eng Siong Chng |
| 05.09.18 | 11:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Poster | Wed-SS-1-2-4 | 52 | Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech | Emre Yilmaz, Henk van den Heuvel and David van Leeuwen |
| 05.09.18 | 11:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Poster | Wed-SS-1-2-5 | 1099 | The Role of Cognate Words, POS Tags, and Entrainment in Code-Switching | Victor Soto, Nishmar Cestero and Julia Hirschberg |
| 05.09.18 | 11:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Poster | Wed-SS-1-2-6 | 1171 | Homophone Identification and Merging for Code-switched Speech Recognition | Brij Mohan Lal Srivastava and Sunayana Sitaram |
| 05.09.18 | 11:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Poster | Wed-SS-1-2-7 | 1178 | Code-switching in Indic Speech Synthesisers | Anju Leela Thomas, Anusha Prakash, Arun Baby and Hema Murthy |
| 05.09.18 | 11:00 | MR 1.01-1.02 | Speech Technologies for Code-Switching in Multilingual Communities | Poster | Wed-SS-1-2-8 | 1259 | A Novel Approach for Effective Recognition of the Code-Switched Data on Monolingual Language Model | Sreeram Ganji and Rohit Sinha |
| 05.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 5 | S&T | Wed-S&T-1-1-1 | 3030 | Hierarchical Accent Determination and Application in a Large Scale ASR System | Ramya Viswanathan, periyasamy Paramasivam and Jithendra Vepa |
| 05.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 5 | S&T | Wed-S&T-1-1-2 | 3032 | Toward Scalable Dialog Technology for Conversational Language Learning: Case Study of the TOEFL MOOC | Vikram Ramanarayanan, David Pautler, Patrick Lange, Eugene Tsuprun, Rutuja Ubale, Keelan Evanini and David Suendermann-Oeft |
| 05.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 5 | S&T | Wed-S&T-1-1-3 | 3033 | Machine Learning powered Data Platform for High-Quality Speech and NLP workflows | João Freitas, Jorge Ribeiro, Daan Baldwijns, Sara Oliveira and Daniela Braga |
| 05.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 5 | S&T | Wed-S&T-1-1-4 | 3034 | Fully automatic speaker separation system, with automatic enrolling of recurrent speakers | Raphael Cohen, Orgad Keller, Jason Levy, Russell Levy, Micha Breakstone and Amit Ashkenazi |
| 05.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 5 | S&T | Wed-S&T-1-1-5 | 3035 | Online speech translation system for Tamil | Madhavaraj Ayyavu, Shiva Kumar H R and Ramakrishnan A G |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-1 | 1712 | Unsupervised Vocal Tract Length Warped Posterior Features for Non-Parallel Voice Conversion | Nirmesh Shah, Maulik C. Madhavi and Hemant Patil |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-2 | 1121 | Voice Conversion with Conditional SampleRNN | Cong Zhou, Michael Horgan, Vivek Kumar, Cristina Vasco and Dan Darcy |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-3 | 1131 | A Voice Conversion Framework with Tandem Feature Sparse Representation and Speaker-Adapted WaveNet Vocoder | Berrak Sisman, Mingyang Zhang and Haizhou Li |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-4 | 1190 | WaveNet Vocoder with Limited Training Data for Voice Conversion | Li-Juan Liu, Zhen-Hua Ling, Yuan Jiang, Ming Zhou and Li-Rong Dai |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-5 | 1210 | Collapsed Speech Segment Detection and Suppression for WaveNet Vocoder | Yi-Chiao Wu, Kazuhiro Kobayashi, Tomoki Hayashi, Patrick Lumban Tobing and Tomoki Toda |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-6 | 1528 | High-quality Voice Conversion Using Spectrogram-Based WaveNet Vocoder | Kuan Chen, Bo Chen, Jiahao Lai and Kai Yu |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-7 | 2417 | Spanish Statistical Parametric Speech Synthesis Using a Neural Vocoder | Antonio Bonafonte, Santiago Pascual and Georgina Dorca |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-8 | 2400 | Experiments with Training Corpora for Statistical Text-to-speech Systems. | Monika Podsiadło and Victor Ungureanu |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-9 | 1506 | Multi-task WaveNet: a Multi-task Generative Model for Statistical Parametric Speech Synthesis without Fundamental Frequency Conditions | Yu Gu and Yongguo Kang |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-10 | 1635 | Speaker-independent Raw Waveform Model for Glottal Excitation | Lauri Juvela, Vassilis Tsiaras, Bajibabu Bollepalli, Manu Airaksinen, Junichi Yamagishi and Paavo Alku |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-11 | 1757 | A New Glottal Neural Vocoder for Speech Synthesis | Yang Cui, Xi Wang, Lei He and Frank K. Soong |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-12 | 1857 | Exemplar-based Speech Waveform Generation | Oliver Watts, Cassia Valentini-Botinhao, Felipe Espic and Simon King |
| 05.09.18 | 10:00 | Hall 4-6: Poster1 | Voice Conversion and Speech Synthesis | Poster | Wed-P-1-1-13 | 43 | Frequency Domain Variants of Velvet Noise and Their Application to Speech Processing and Synthesis | Hideki Kawahara, Ken-Ichi Sakakibara, Masanori Morise, Hideki Banno, Tomoki Toda and Toshio Irino |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-1 | 1346 | Joint Learning of Interactive Spoken Content Retrieval and Trainable User Simulator | Pei-Hung Chung, Kuan Tung, Ching-Lun Tai and Hung-yi Lee |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-2 | 1777 | Attention-based End-to-End Models for Small-Footprint Keyword Spotting | Changhao Shan, Junbo Zhang, Yujun Wang and Lei Xie |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-3 | 991 | Prediction of Aesthetic Elements in Karnatic Music: a Machine Learning Approach | Ragesh Rajan M, Ashwin Vijayakumar and Deepu Vijayasenan |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-4 | 1283 | Topic and Keyword Identification for Low-resourced Speech Using Cross-Language Transfer Learning | Wenda Chen, Mark Hasegawa-Johnson and Nancy F. Chen |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-5 | 1836 | Automatic Speech Recognition and Topic Identification from Speech for Almost-Zero-Resource Languages | Matthew Wiesner, Chunxi Liu, Lucas Ondel, Craig Harman, Vimal Manohar, Jan Trmal, Zhongqiang Huang, Najim Dehak and Sanjeev Khudanpur |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-6 | 1100 | Play Duration Based User-Entity Affinity Modeling in Spoken Dialog System | Bo Xiao, Nicholas Monath, Shankar Ananthakrishnan and Abishek Ravi |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-7 | 1776 | Empirical Analysis of Score Fusion Application to Combined Neural Networks for Open Vocabulary Spoken Term Detection | Shi-wook Lee, Kazuyo Tanaka and Yoshiaki Itoh |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-8 | 1973 | Phonological Posterior Hashing for Query by Example Spoken Term Detection | Afsaneh Asaei, Dhananjay Ram and Herve Bourlard |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-9 | 2017 | Term Extraction via Neural Sequence Labeling a Comparative Evaluation of Strategies Using Recurrent Neural Networks | Maren Kucza, Jan Niehues, Thomas Zenkel, Alex Waibel and Sebastian Stüker |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-10 | 1318 | Semi-supervised Learning for Information Extraction from Dialogue | Anjuli Kannan, Kai Chen, Diana Jaunzeikare and Alvin Rajkomar |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-11 | 1808 | Slot Filling with Delexicalized Sentence Generation | Youhyun Shin, Kang Min Yoo and Sang-goo Lee |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-12 | 2045 | Music Genre Recognition Using Deep Neural Networks and Transfer Learning | Deepanway Ghosal and Maheshkumar H. Kolekar |
| 05.09.18 | 10:00 | Hall 4-6: Poster2 | Extracting Information from Audio | Poster | Wed-P-1-2-13 | 2204 | Efficient Voice Trigger Detection for Low Resource Hardware | Siddharth Sigtia, Rob Haynes, Hywel Richards, Erik Marchi and John Bridle |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-1 | 45 | A Novel Normalization Method for Autocorrelation Function for Pitch Detection and for Speech Activity Detection | Qiguang Lin and Yiwen Shao |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-2 | 1105 | Estimation of the Vocal Tract Length of Vowel Sounds Based on the Frequency of the Significant Spectral Valley | TV Ananthapadmanabha and Ramakrishnan AngaraiGanesan |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-3 | 1143 | Deep Learning Techniques for Koala Activity Detection | Ivan Himawan, Michael Towsey, Bradley Law and Paul Roe |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-4 | 1147 | Glottal Closure Instant Detection from Speech Signal Using Voting Classifier and Recursive Feature Elimination | Jindrich Matousek and Daniel Tihelka |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-5 | 1463 | Assessing Speaker Engagement in 2-Person Debates: Overlap Detection in United States Presidential Debates | Midia Yousefi, Navid Shokouhi and John H.L. Hansen |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-6 | 1522 | All-Conv Net for Bird Activity Detection: Significance of Learned Pooling | Arjun Pankajakshan, Anshul Thakur, Daksh Thapar, Padmanabhan Rajan and Aditya Nigam |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-7 | 1705 | Deep Convex Representations: Feature Representations for Bioacoustics Classification | Anshul Thakur, Vinayak Abrol, Pulkit Sharma and Padmanabhan Rajan |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-8 | 2014 | Detection of Glottal Excitation Epochs in Speech Signal Using Hilbert Envelope | Hirak Dasgupta, Prem C. Pandey and K S Nataraj |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-9 | 2115 | Analyzing Thai Tone Distribution through Functional Data Analysis | Hong Zhang |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-10 | 2275 | Articulatory Feature Classification Using Convolutional Neural Networks | Danny Merkx and Odette Scharenborg |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-11 | 2590 | A New Frequency Coverage Metric and a New Subband Encoding Model, with an Application in Pitch Estimation | Shoufeng Lin |
| 05.09.18 | 10:00 | Hall 4-6: Poster3 | Signal Analysis for the Natural, Biological and Social Sciences | Poster | Wed-P-1-3-12 | 1173 | Improved Epoch Extraction from Telephonic Speech Using Chebfun and Zero Frequency Filtering | Ganga Gowri B, Soman K.P and Govind D |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-1 | 2530 | An Empirical Analysis of the Correlation of Syntax and Prosody | Arne Köhn, Timo Baumann and Oskar Dörfler |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-2 | 2533 | Analysing the Focus of a Hierarchical Attention Network: the Importance of Enjambments When Classifying Post-modern Poetry | Timo Baumann, Hussein Hussein and Burkhard Meyer-Sickendiek |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-3 | 1962 | Language-Dependent Melody Embeddings | Daniil Kocharov and Alla Menshikova |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-4 | 1602 | Stress Distribution of Given Information in Chinese Reading Texts | Yuan Jia and Xiaoxiao Ma |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-5 | 2366 | Acoustic-prosodic Entrainment in Structural Metadata Events | Vera Cabarrão, Fernando Batista, Helena Moniz, Isabel Trancoso and Ana Isabel Mata |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-6 | 1126 | Formant Measures of Vowels Adjacent to Alveolar and Retroflex Consonants in Arrernte: Stressed and Unstressed Position | Marija Tabain, Richard Beare and Andrew Butcher |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-7 | 1386 | Automatic Assessment of L2 English Word Prosody Using Weighted Distances of F0 and Intensity Contours | Quy-Thao Truong, Tsuneo Kato and Seiichi Yamamoto |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-8 | 1476 | Homogeneity vs Heterogeneity in Indian English: Investigating Influences of L1 on f0 Range | Olga Maxwell, Elinor Payne and Rosey Billington |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-9 | 91 | Emotional Prosody Perception in Mandarin-speaking Congenital Amusics | Yixin Zhang, Tianzhu Geng and Jinsong Zhang |
| 05.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Prosody | Poster | Wed-P-1-4-10 | 1795 | Cultural Differences in Pattern Matching: Multisensory Recognition of Socio-affective Prosody | Takaaki Shochi, Jean-Luc Rouas, Marine Guerry and Donna Erickson |
| 05.09.18 | 12:00 | Hall 3 | Perspective Talk-3 | Oral | Wed-Perspective-3 | 4007 | Speech Processing in the Human Brain Meets Deep Learning | Nima Mesgarani |
| 05.09.18 | 12:30 | Hall 3 | Industry Presentation-4 | Wed-IP-4 | - | Industry Presentation by Microsoft | Yifan Gong | |
| 05.09.18 | 12:30 | Hall 1 | Industry Presentation-5 | Wed-IP-5 | - | Industry Presentation by Xiaomi | Wang Yujun | |
| 05.09.18 | 12:30 | Hall 2 | Industry Presentation-6 | Wed-IP-6 | - | Industry Presentation by Ministry of Electronics and Information Technology (MeitY), Government of India | Joint Secretary, MeitY | |
| 05.09.18 | 14:30 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-1 | 1456 | ESPnet: End-to-End Speech Processing Toolkit | Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, Adithya Renduchintala and Tsubasa Ochiai |
| 05.09.18 | 14:50 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-2 | 1339 | A GPU-based WFST Decoder with Exact Lattice Generation | Zhehuai Chen, Justin Luitjens, Hainan Xu, Yiming Wang, Daniel Povey and Sanjeev Khudanpur |
| 05.09.18 | 15:10 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-3 | 1085 | Automatic Speech Recognition System Development in the "Wild" | Anton Ragni and Mark Gales |
| 05.09.18 | 15:30 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-4 | 2453 | Semantic Lattice Processing in Contextual Automatic Speech Recognition for Google Assistant | Leonid Velikovich, Ian Williams, Justin Scheiner, Petar Aleksic, Pedro Moreno and Michael Riley |
| 05.09.18 | 15:50 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-5 | 2416 | Contextual Speech Recognition in End-to-end Neural Network Systems Using Beam Search | Ian Williams, Anjuli Kannan, Petar Aleksic, David Rybach and Tara Sainath |
| 05.09.18 | 16:10 | Hall 3 | Recurrent Neural Models for ASR | Oral | Wed-O-2-1-6 | 1160 | Forward-Backward Attention Decoder | Masato Mimura, Shinsuke Sakai and Tatsuya Kawahara |
| 05.09.18 | 14:30 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-1 | 1015 | Learning Discriminative Features for Speaker Identification and Verification | Sarthak Yadav and Atul Rai |
| 05.09.18 | 14:50 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-2 | 1209 | Triplet Loss Based Cosine Similarity Metric Learning for Text-independent Speaker Recognition | Sergey Novoselov, Vadim Shchemelinin, Andrey Shulipa, Alexandr Kozlov and Ivan Kremnev |
| 05.09.18 | 15:10 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-3 | 1226 | Speaker Embedding Extraction with Phonetic Information | Yi Liu, Liang He, Jia Liu and Michael T. Johnson |
| 05.09.18 | 15:30 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-4 | 993 | Attentive Statistics Pooling for Deep Speaker Embedding | Koji Okabe, Takafumi Koshinaka and Koichi Shinoda |
| 05.09.18 | 15:50 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-5 | 1685 | Robust and Discriminative Speaker Embedding via Intra-Class Distance Variance Regularization | Nam Le and Jean-Marc Odobez |
| 05.09.18 | 16:10 | Hall 1 | Speaker Verification Using Neural Network Methods I | Oral | Wed-O-2-2-6 | 1769 | Deep Discriminative Embeddings for Duration Robust Speaker Verification | Na Li, Deyi Tuo, Dan Su, Zhifeng Li and Dong Yu |
| 05.09.18 | 14:30 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-1 | 1358 | Impact of Different Speech Types on Listening Effort | Olympia Simantiraki, Martin Cooke and Simon King |
| 05.09.18 | 14:50 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-2 | 2053 | Who Are You Listening to? towards a Dynamic Measure of Auditory Attention to Speech-on-speech. | Moïra-Phoebé Huet, Christophe Micheyl, Etienne Gaudrain and Etienne Parizet |
| 05.09.18 | 15:10 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-3 | 1812 | Investigating the Role of Familiar Face and Voice Cues in Speech Processing in Noise | Jeesun Kim, Sonya Karisma, Vincent Aubanel and Chris Davis |
| 05.09.18 | 15:30 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-4 | 1088 | The Conversation Continues: the Effect of Lyrics and Music Complexity of Background Music on Spoken-Word Recognition | Odette Scharenborg and Martha Larson |
| 05.09.18 | 15:50 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-5 | 2089 | Loud and Shouted Speech Perception at Variable Distances in a Forest | Julien Meyer, Fanny Meunier, Laure Dentel, Noelia Do Carmo Blanco and Frédéric Sèbe |
| 05.09.18 | 16:10 | Hall 2 | Speech Perception in Adverse Conditions | Oral | Wed-O-2-3-6 | 1271 | Phoneme Resistance and Phoneme Confusion in Noise: Impact of Dyslexia | Noelia Do Carmo Blanco, Julien Meyer, Michel Hoen and Fanny Meunier |
| 05.09.18 | 14:30 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-1 | 38 | Conditional End-to-End Audio Transforms | Albert Haque, Michelle Guo and Prateek Verma |
| 05.09.18 | 14:50 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-2 | 1018 | Detection of Glottal Closure Instants in Degraded Speech Using Single Frequency Filtering Analysis | Gunnam Aneeja, Sudarsana Reddy Kadiri and Bayya Yegnanarayana |
| 05.09.18 | 15:10 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-3 | 2293 | Tone Recognition Using Lifters and CTC | Loren Lugosch and Vikrant Singh Tomar |
| 05.09.18 | 15:30 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-4 | 1613 | Epoch Extraction from Pathological Children Speech Using Single Pole Filtering Approach | Vikram C M and S R Mahadeva Prasanna |
| 05.09.18 | 15:50 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-5 | 1756 | Automated Classification of Vowel-Gesture Parameters Using External Broadband Excitation | Balamurali B T and Jer-Ming Chen |
| 05.09.18 | 16:10 | MR G.01-G.02 | Measuring Pitch and Articulation | Oral | Wed-O-2-4-6 | 2495 | Estimation of Fundamental Frequency from Singing Voice Using Harmonics of Impulse-like Excitation Source | Sudarsana Reddy Kadiri and Bayya Yegnanarayana |
| 05.09.18 | 14:30 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-1 | 57 | Investigating the Effect of Audio Duration on Dementia Detection Using Acoustic Features | Jochen Weiner, Miguel Angrick, Srinivasan Umesh and Tanja Schultz |
| 05.09.18 | 14:50 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-2 | 1288 | An Interlocutor-Modulated Attentional LSTM for Differentiating between Subgroups of Autism Spectrum Disorder | Yun-Shao Lin, Susan Shur-Fen Gau and Chi-Chun Lee |
| 05.09.18 | 15:10 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-3 | 1772 | Recognition of Echolalic Autistic Child Vocalisations Utilising Convolutional Recurrent Neural Networks | Shahin Amiriparian, Alice Baird, Sahib Julka, Alyssa Alcorn, Sandra Ottl, Sunčica Petrović, Eloise Ainger, Nicholas Cummins and Björn Schuller |
| 05.09.18 | 15:30 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-4 | 1562 | Modeling Interpersonal Influence of Verbal Behavior in Couples Therapy Dyadic Interactions | Sandeep Nallan Chakravarthula, Brian Baucom and Panayiotis Georgiou |
| 05.09.18 | 15:50 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-5 | 1583 | Computational Modeling of Conversational Humor in Psychotherapy | Anil Ramakrishna, Timothy Greer, David Atkins and Shrikanth Narayanan |
| 05.09.18 | 16:10 | MR G.03-G.04 | Speech and Language Analytics for Mental Health | Oral | Wed-O-2-5-6 | 2295 | Multimodal I-vectors to Detect and Evaluate Parkinson's Disease | Nicanor Garcia, Juan Camilo Vásquez Correa, Juan Rafael Orozco-Arroyave and Elmar Noeth |
| 05.09.18 | 14:30 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-1 | 97 | Overview of the 2018 Spoken CALL Shared Task | Claudia Baur, Andrew Caines, Cathy Chua, Johanna Gerlach, Mengjie Qian, Manny Rayner, Martin Russell, Helmer Strik and Xizi Wei |
| 05.09.18 | 14:50 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-2 | 1000 | The CSU-K Rule-Based System for the 2Nd Edition Spoken CALL Shared Task | Jülg Dominik, Mario Kunstek, Cem Philipp Freimoser, Kay Berkling and Mengjie Qian |
| 05.09.18 | 15:08 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-3 | 1309 | Liulishuo's System for the Spoken CALL Shared Task 2018 | Huy Nguyen, Lei Chen, Ramon Prieto, Chuan Wang and Yang Liu |
| 05.09.18 | 15:26 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-4 | 1328 | An Optimization Based Approach for Solving Spoken CALL Shared Task | Mohammad Ateeq, Abualsoud Hanani and Aziz Qaroush |
| 05.09.18 | 15:44 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-5 | 1372 | The University of Birmingham 2018 Spoken CALL Shared Task Systems | Mengjie Qian, Xizi Wei, Peter Jančovič and Martin Russell |
| 05.09.18 | 16:02 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-6 | 2362 | Improvements to an Automated Content Scoring System for Spoken CALL Responses: the ETS Submission to the Second Spoken CALL Shared Task | Keelan Evanini, Matthew Mulholland, Rutuja Ubale, Yao Qian, Robert Pugh, Vikram Ramanarayanan and Aoife Cahill |
| 05.09.18 | 16:20 | MR 1.01-1.02 | Spoken CALL Shared Task, Second Edition | Oral | Wed-SS-2-1-7 | - | Closing Remarks and General Discussion | - |
| 05.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 6 | S&T | Wed-S&T-2-1-1 | 3036 | Extracting speaker’s gender, accent, age and emotional state from speech | Nagendra Goel, Mousmita Sarma, Tejendra Kushwah, Dharmesh Agarwal, Zikra Iqbal and Surbhi Chauhan |
| 05.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 6 | S&T | Wed-S&T-2-1-2 | 3042 | Determining Speaker Location from Speech in a Practical Environment | BHVS Narayanamurthy, JV Satyanarayana and B Yegnanarayana |
| 05.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 6 | S&T | Wed-S&T-2-1-3 | 3043 | An Automatic Speech Transcription System for Manipuri Language | Tanvina Patel, Krishna D N, Noor Fathima, Nisar Shah, Mahima C, Deepak Kumar and Anuroop Iyengar |
| 05.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 6 | S&T | Wed-S&T-2-1-4 | 3009 | SPIRE-SST: An automatic web-based self-learning tool for syllable stress tutoring (SST) to the second language learners | Chiranjeevi Yarra, Anand P A, Kausthubha N K and Prasanta Kumar Ghosh |
| 05.09.18 | 14:30 | MR G.05-G.06 | Show and Tell 6 | S&T | Wed-S&T-2-1-5 | 3046 | Glotto Vibrato Graph: A Device and Method for Recording, Analysis and Visualization of Glottal Activity | Kishalay Chakraborty, Senjam Shantirani Devi, Sanjeevan Devnath, S R Mahadeva Prasanna and Priyankoo Sarmah |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-1 | 2456 | Multi-Modal Data Augmentation for End-to-end ASR | Adithya Renduchintala, Shuoyang Ding, Matthew Wiesner and Shinji Watanabe |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-2 | 1866 | Multi-task Learning with Augmentation Strategy for Acoustic-to-word Attention-based Encoder-decoder Speech Recognition | Takafumi Moriya, Sei Ueno, Yusuke Shinohara, Marc Delcroix, Yoshikazu Yamaguchi and Yushi Aono |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-3 | 1247 | Training Augmentation with Adversarial Examples for Robust Speech Recognition | Sining Sun, Ching-Feng Yeh, Mari Ostendorf, Mei-Yuh Hwang and Lei Xie |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-4 | 1211 | Data Augmentation Improves Recognition of Foreign Accented Speech | Takashi Fukuda, Raul Fernandez, Andrew Rosenberg, Samuel Thomas, Bhuvana Ramabhadran, Alexander Sorin and Gakuto Kurata |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-5 | 2209 | Speaker Adaptive Training and Mixup Regularization for Neural Network Acoustic Models in Automatic Speech Recognition | Natalia Tomashenko, Yuri Khokhlov and Yannick Estève |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-6 | 1241 | Neural Language Codes for Multilingual Acoustic Models | Markus Müller, Sebastian Stüker and Alex Waibel |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-7 | 1424 | Encoder Transfer for Attention-based Acoustic-to-word Speech Recognition | Sei Ueno, Takafumi Moriya, Masato Mimura, Shinsuke Sakai, Yusuke Shinohara, Yoshikazu Yamaguchi, Yushi Aono and Tatsuya Kawahara |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-8 | 1897 | Empirical Evaluation of Speaker Adaptation on DNN Based Acoustic Model | Ke Wang, Junbo Zhang, Yujun Wang and Lei Xie |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-9 | 1450 | Improving DNNs Trained with Non-Native Transcriptions Using Knowledge Distillation and Target Interpolation | Amit Das and Mark Hasegawa-Johnson |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-10 | 1182 | Improving Cross-Lingual Knowledge Transferability Using Multilingual TDNN-BLSTM with Language-Dependent Pre-Final Layer | Siyuan Feng and Tan Lee |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-11 | 1438 | Auxiliary Feature Based Adaptation of End-to-end ASR Systems | Marc Delcroix, Shinji Watanabe, Atsunori Ogawa, Shigeki Karita and Tomohiro Nakatani |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-12 | 1378 | Leveraging Native Language Information for Improved Accented Speech Recognition | Shahram Ghorbani and John H.L. Hansen |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-13 | 1864 | Improved Accented Speech Recognition Using Accent Embeddings and Multi-task Learning | Abhinav Jain, Minali Upreti and Preethi Jyothi |
| 05.09.18 | 14:30 | Hall 4-6: Poster1 | Adjusting to Speaker, Accent, and Domain | Poster | Wed-P-2-1-14 | 1990 | Fast Language Adaptation Using Phonological Information | Sibo Tong, Philip N. Garner and Herve Bourlard |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-1 | 1239 | Naturalness Improvement Algorithm for Reconstructed Glossectomy Patient's Speech Using Spectral Differential Modification in Voice Conversion | Hiroki Murakami, Sunao Hara, Masanobu Abe, Masaaki Sato and Shogo Minagi |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-2 | 2286 | Audio-visual Voice Conversion Using Deep Canonical Correlation Analysis for Deep Bottleneck Features | Satoshi Tamura, Kento Horio, Hajime Endo, Satoru Hayamizu and Tomoki Toda |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-3 | 1869 | An Investigation of Convolution Attention Based Models for Multilingual Speech Synthesis of Indian Languages | Pallavi Baljekar, SaiKrishna Rallabandi and Alan W Black |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-4 | 2066 | The Effect of Real-Time Constraints on Automatic Speech Animation | Danny Websdale, Sarah Taylor and Ben Milner |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-5 | 2587 | Joint Learning of Facial Expression and Head Pose from Speech | David Greenwood, Iain Matthews and Stephen Laycock |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-6 | 1306 | Acoustic-dependent Phonemic Transcription for Text-to-speech Synthesis | Kévin Vythelingum, Yannick Estève and Olivier Rosec |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-7 | 1791 | Multimodal Speech Synthesis Architecture for Unsupervised Speaker Adaptation | Hieu-Thi Luong and Junichi Yamagishi |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-8 | 999 | Articulatory-to-speech Conversion Using Bi-directional Long Short-term Memory | Fumiaki Taguchi and Tokihiko Kaburagi |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-9 | 1080 | Implementation of Respiration in Articulatory Synthesis Using a Pressure-Volume Lung Model | Keisuke Tanihara, Shogo Yonekura and Yasuo Kuniyoshi |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-10 | 1198 | Learning and Modeling Unit Embeddings for Improving HMM-based Unit Selection Speech Synthesis | Xiao Zhou, Zhen-Hua Ling, Zhi-Ping Zhou and Li-Rong Dai |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-11 | 1305 | Deep Metric Learning for the Target Cost in Unit-Selection Speech Synthesizer | Ruibo Fu, Jianhua Tao, Yibin Zheng and Zhengqi Wen |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-12 | 1460 | DNN-based Speech Synthesis for Small Data Sets Considering Bidirectional Speech-Text Conversion | Kentaro Sone and Toru Nakashika |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-13 | 1286 | A Weighted Superposition of Functional Contours Model for Modelling Contextual Prominence of Elementary Prosodic Contours | Branislav Gerazov, Gérard Bailly and Yi Xu |
| 05.09.18 | 14:30 | Hall 4-6: Poster2 | Speech Synthesis Paradigms and Methods | Poster | Wed-P-2-2-14 | 1753 | LSTBM: a Novel Sequence Representation of Speech Spectra Using Restricted Boltzmann Machine with Long Short-Term Memory | Toru Nakashika |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-1 | 1284 | Should Code-switching Models Be Asymmetric? | Barbara E. Bullock, Gualberto Guzmán, Jacqueline Serigos and Almeida Jacqueline Toribio |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-2 | 48 | Cross-language Perception of Mandarin Lexical Tones by Mongolian-speaking Bilinguals in the Inner Mongolia Autonomous Region, China | Kimiko Tsukada and Yu Rong |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-3 | 1336 | Automatically Measuring L2 Speech Fluency without the Need of ASR: a Proof-of-concept Study with Japanese Learners of French | Lionel Fontan, Maxime Le Coz and Sylvain Detey |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-4 | 1983 | Analysis of L2 Learners’ Progress of Distinguishing Mandarin Tone 2 and Tone 3 | Yue Sun, Win Thuzar Kyaw, Jinsong Zhang and Yoshinori Sagisaka |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-5 | 2027 | Unsupervised Discovery of Non-native Phonetic Patterns in L2 English Speech for Mispronunciation Detection and Diagnosis | Xu Li, Shaoguang Mao, Xixin Wu, Kun Li, Xunying Liu and Helen Meng |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-6 | 2224 | Wuxi Speakers’ Production and Perception of Coda Nasals in Mandarin | Lei Wang, Jie Cui and Ying Chen |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-7 | 2373 | The Diphthongs of Formal Nigerian English: a Preliminary Acoustic Analysis | Natalia Dyrenko and Robert Fuchs |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-8 | 1798 | Characterizing Rhythm Differences between Strong and Weak Accented L2 Speech | Chris Davis and Jeesun Kim |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-9 | 2422 | Analysis of phone errors attributable to phonological effects associated with language acquisition through bottleneck feature visualisations | Eva Fringi and Martin Russell |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-10 | 1938 | Category Similarity in Multilingual Pronunciation Training | Jacques Koreman |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-11 | 2078 | Talker Diarization in the Wild: the Case of Child-centered Daylong Audio-recordings | Alejandrina Cristia, Shobhana Ganesh, Marisa Casillas and Sriram Ganapathy |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-12 | 2523 | Automated Classification of Children’S Linguistic versus Non-Linguistic Vocalisations | Zixing Zhang, Alejandrina Cristia, Anne Warlaumont and Björn Schuller |
| 05.09.18 | 14:30 | Hall 4-6: Poster3 | Second Language Acquisition and Code-switching | Poster | Wed-P-2-3-13 | 1556 | Pitch Characteristics of L2 English Speech by Chinese Speakers: a Large-scale Study | Jiahong Yuan, Qiusi Dong, Fei Wu, Huan Luan, Xiaofei Yang, Hui Lin and Yang Liu |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-1 | 1343 | Dual Language Models for Code Switched Speech Recognition | Saurabh Garg, Tanmay Parekh and Preethi Jyothi |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-2 | 1711 | Multilingual Neural Network Acoustic Modelling for ASR of Under-Resourced English-isiZulu Code-Switched Speech | Astik Biswas, Febe de Wet, Ewald van der Westhuizen, Emre Yilmaz and Thomas Niesler |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-3 | 1580 | Fast ASR-free and Almost Zero-resource Keyword Spotting Using DTW and CNNs for Humanitarian Monitoring | Raghav Menon, Herman Kamper, John Quinn and Thomas Niesler |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-4 | 1668 | Text-Dependent Speech Enhancement for Small-Footprint Robust Keyword Detection | Meng Yu, Xuan Ji, Yi Gao, Lianwu Chen, Jie Chen, Jimeng Zheng, Dan Su and Dong Yu |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-5 | 1124 | Improved ASR for Under-resourced Languages through Multi-task Learning with Acoustic Landmarks | Di He, Boon Pang Lim, Xuesong Yang, Mark Hasegawa-Johnson and Deming Chen |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-6 | 2454 | Cross-language Phoneme Mapping for Low-resource Languages: an Exploration of Benefits and Trade-offs | Nick K Chibuye, Todd Rosenstock and Brian DeRenzi |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-7 | 1352 | User-centric Evaluation of Automatic Punctuation in ASR Closed Captioning | Máté Ákos Tündik, György Szaszák, Gábor Gosztolya and András Beke |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-8 | 1096 | Punctuation Prediction Model for Conversational Speech | Piotr Żelasko, Piotr Szymański, Jan Mizgajski, Adrian Szymczak, Yishay Carmiel and Najim Dehak |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-9 | 2457 | BUT OpenSAT 2017 Speech Recognition System | Martin Karafiát, Murali Karthick Baskar, Igor Szöke, Vladimír Malenovský, Karel Veselý, František Grézl, Lukáš Burget and Jan Černocký |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-10 | 2434 | Visual Recognition of Continuous Cued Speech Using a Tandem CNN-HMM Approach | Li Liu, Thomas Hueber, Gang Feng and Denis Beautemps |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-11 | 2112 | Building Large-vocabulary Speaker-independent Lipreading Systems | Kwanchiva Thangthai and Richard Harvey |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-12 | 2079 | CRIM's System for the MGB-3 English Multi-Genre Broadcast Media Transcription | Vishwa Gupta and Gilles Boulianne |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-13 | 2384 | Sampling Strategies in Siamese Networks for Unsupervised Speech Representation Learning | Rachid Riad, Corentin Dancette, Julien Karadayi, Neil Zeghidour, Thomas Schatz and Emmanuel Dupoux |
| 05.09.18 | 14:30 | Hall 4-6: Poster4 | Topics in Speech Recognition | Poster | Wed-P-2-4-14 | 1204 | Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting | Mengzhe Chen, ShiLiang Zhang, Ming Lei, Yong Liu, Haitao Yao and Jie Gao |
| 05.09.18 | 17:00 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-1 | 2334 | Multilingual Bottleneck Features for Subword Modeling in Zero-resource Languages | Enno Hermann and Sharon Goldwater |
| 05.09.18 | 17:20 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-2 | 1081 | Exploiting Speaker and Phonetic Diversity of Mismatched Language Resources for Unsupervised Subword Modeling | Siyuan Feng and Tan Lee |
| 05.09.18 | 17:40 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-3 | 1308 | Unsupervised Word Segmentation from Speech with Attention | Pierre Godard, Marcely Zanon Boito, Lucas Ondel, Alexandre Berard, François Yvon, Aline Villavicencio and Laurent Besacier |
| 05.09.18 | 18:00 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-4 | 2364 | Learning Word Embeddings: Unsupervised Methods for Fixed-size Representations of Variable-length Speech Segments | Nils Holzenberger, Mingxing Du, Julien Karadayi, Rachid Riad and Emmanuel Dupoux |
| 05.09.18 | 18:20 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-5 | 2148 | Full Bayesian Hidden Markov Model Variational Autoencoder for Acoustic Unit Discovery | Thomas Glarner, Patrick Hanebrink, Janek Ebbers and Reinhold Haeb-Umbach |
| 05.09.18 | 18:40 | Hall 1 | Zero-resource Speech Recognition | Oral | Wed-O-3-1-6 | 2194 | Unspeech: Unsupervised Speech Context Embeddings | Benjamin Milde and Chris Biemann |
| 05.09.18 | 17:00 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-1 | 1371 | Impact of Aliasing on Deep CNN-Based End-to-End Acoustic Models | Yuan Gong and Christian Poellabauer |
| 05.09.18 | 17:20 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-2 | 1526 | Keyword Based Speaker Localization: Localizing a Target Speaker in a Multi-speaker Environment | Sunit Sivasankaran, Emmanuel Vincent and Dominique Fohr |
| 05.09.18 | 17:40 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-3 | 1629 | End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction | Zhong-Qiu Wang, Jonathan Le Roux, DeLiang Wang and John Hershey |
| 05.09.18 | 18:00 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-4 | 1773 | PhaseNet: Discretized Phase Modeling with Deep Neural Networks for Audio Source Separation | Naoya Takahashi, Purvi Agrawal, Nabarun Goswami and Yuki Mitsufuji |
| 05.09.18 | 18:20 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-5 | 1940 | Integrating Spectral and Spatial Features for Multi-Channel Speaker Separation | Zhong-Qiu Wang and DeLiang Wang |
| 05.09.18 | 18:40 | Hall 2 | Spatial and Phase Cues for Source Separation and Speech Recognition | Oral | Wed-O-3-2-6 | 2516 | DNN Driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation | Mandar Gogate, Ahsan Adeel, Ricard Marxer, Jon Barker and Amir Hussain |
| 05.09.18 | 17:00 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-1 | 1256 | Exploring Temporal Reduction in Dialectal Spanish: a Large-scale Study of Lenition of Voiced Stops and Coda-s | Ioana Vasilescu, Nidia Hernandez, Bianca Vieru and Lori Lamel |
| 05.09.18 | 17:20 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-2 | 1130 | Dialect-geographical Acoustic-Tonetics: Five Disyllabic Tone Sandhi Patterns in Cognate Words from the Wu Dialects of ZhèJiāNg Province | Phil Rose |
| 05.09.18 | 17:40 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-3 | 1065 | Regional Variation of /r/ in Swiss German Dialects | Adrian Leemann, Stephan Schmid, Dieter Studer-Joho and Marie-José Kolly |
| 05.09.18 | 18:00 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-4 | 1944 | Variation in the FACE Vowel across West Yorkshire: Implications for Forensic Speaker Comparisons | Kate Earnshaw and Erica Gold |
| 05.09.18 | 18:20 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-5 | 65 | The ‘West Yorkshire Regional English Database’: Investigations into the Generalizability of Reference Populations for Forensic Speaker Comparison Casework | Erica Gold, Sula Ross and Kate Earnshaw |
| 05.09.18 | 18:40 | MR G.01-G.02 | Dialectal Variation | Oral | Wed-O-3-3-6 | 2381 | Studying Vowel Variation in French-Algerian Arabic Code-switched Speech | Jane Wottawa, Amazouz Djegdjiga, Martine Adda-Decker and Lori Lamel |
| 05.09.18 | 17:00 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-1 | 1942 | Fearless Steps: Apollo-11 Corpus Advancements for Speech Technologies from Earth to the Moon | John H. L. Hansen, Abhijeet Sangwan, Aditya Joglekar, Ahmet E. Bulut, Lakshmish Kaushik and Chengzhu Yu |
| 05.09.18 | 17:20 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-2 | 1516 | A Knowledge Driven Structural Segmentation Approach for Play-Talk Classification During Autism Assessment | Manoj Kumar, Pooja Chebolu, So Hyun Kim, Kassandra Martinez, Catherine Lord and Shrikanth Narayanan |
| 05.09.18 | 17:40 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-3 | 1349 | An Open Source Emotional Speech Corpus for Human Robot Interaction Applications | Jesin James, Li Tian and Catherine Inez Watson |
| 05.09.18 | 18:00 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-4 | 2330 | Speech Database and Protocol Validation Using Waveform Entropy | Itshak Lapidot, Héctor Delgado, Massimiliano Todisco, Nicholas Evans and Jean-Francois Bonastre |
| 05.09.18 | 18:20 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-5 | 2212 | A French-Spanish Multimodal Speech Communication Corpus Incorporating Acoustic Data, Facial, Hands and Arms Gestures Information | Lucas D. Terissi, Gonzalo Sad, Mauricio Cerda, Slim Ouni, Rodrigo Galvez, Juan C. Gómez, Bernard Girau and Nancy Hitschfeld-Kahler |
| 05.09.18 | 18:40 | MR G.03-G.04 | Spoken Corpora and Annotation | Oral | Wed-O-3-4-6 | 1110 | L2-ARCTIC: a Non-native English Speech Corpus | Guanlong Zhao, Sinem Sonsaat, Alif Silpachai, Ivana Lucic, Evgeny Chukharev-Hudilainen, John Levis and Ricardo Gutierrez-Osuna |
| 05.09.18 | 17:00 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-1 | 1252 | ZCU-NTIS Speaker Diarization System for the DIHARD 2018 Challenge | Zbynek Zajic, Marie Kunesova, Jan Zelinka and Marek Hrúz |
| 05.09.18 | 17:17 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-2 | 1742 | Speaker Diarization with Enhancing Speech for the First DIHARD Challenge | Lei Sun, Jun Du, Chao Jiang, Xueyang Zhang, Shan He, Bing Yin and Chin-Hui Lee |
| 05.09.18 | 17:34 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-3 | 1749 | BUT System for DIHARD Speech Diarization Challenge 2018 | Mireia Diez, Federico Landini, Lukáš Burget, Johan Rohdin, Anna Silnova, Katerina Zmolikova, Ondřej Novotný, Karel Veselý, Ondrej Glembek, Oldřich Plchot, Ladislav Mošner and Pavel Matějka |
| 05.09.18 | 17:51 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-4 | 1841 | Estimation of the Number of Speakers with Variational Bayesian PLDA in the DIHARD Diarization Challenge. | Ignacio Viñals, Pablo Gimeno, Alfonso Ortega, Antonio Miguel and Eduardo Lleida |
| 05.09.18 | 18:08 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-5 | 1893 | Diarization Is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge | Gregory Sell, David Snyder, Alan McCree, Daniel Garcia-Romero, Jesús Villalba, Matthew Maciejewski, Vimal Manohar, Najim Dehak, Daniel Povey, Shinji Watanabe and Sanjeev Khudanpur |
| 05.09.18 | 18:25 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-6 | 2172 | The EURECOM Submission to the First DIHARD Challenge | Jose Patino, Héctor Delgado and Nicholas Evans |
| 05.09.18 | 18:42 | MR 1.01-1.02 | The First DIHARD Speech Diarization Challenge | Oral | Wed-SS-3-1-7 | 2304 | Joint Discriminative Embedding Learning, Speech Activity and Overlap Detection for the DIHARD Speaker Diarization Challenge | Valter Akira Miasato Filho, Diego Augusto Silva and Luis Gustavo Depra Cuozzo |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-1 | 1626 | Multilingual Grapheme-to-Phoneme Conversion with Global Character Vectors | Jinfu Ni, Yoshinori Shiga and Hisashi Kawai |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-2 | 1694 | A Hybrid Approach to Grapheme to Phoneme Conversion in Assamese | Somnath Roy and Shakuntala Mahanta |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-3 | 2525 | Investigation of Using Disentangled and Interpretable Representations for One-shot Cross-lingual Voice Conversion | Seyed Hamidreza Mohammadi and Taehwan Kim |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-4 | 1174 | Using Pupillometry to Measure the Cognitive Load of Synthetic Speech | Avashna Govender and Simon King |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-5 | 1199 | Measuring the Cognitive Load of Synthetic Speech Using a Dual Task Paradigm | Avashna Govender and Simon King |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-6 | 42 | Attentive Sequence-to-Sequence Learning for Diacritic Restoration of YorùBá Language Text | Iroro Orife |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-7 | 70 | Gated Convolutional Neural Network for Sentence Matching | Peixin Chen, Wu Guo, Zhi Chen, Jian Sun and Lanhua You |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-8 | 1920 | On Training and Evaluation of Grapheme-to-Phoneme Mappings with Limited Data | Dravyansh Sharma |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-9 | 1093 | The Perception and Analysis of the Likeability and Human Likeness of Synthesized Speech | Alice Baird, Emilia Parada-Cabaleiro, Simone Hantke, Felix Burkhardt, Nicholas Cummins and Björn Schuller |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-10 | 1159 | Word Emphasis Prediction for Expressive Text to Speech | Yosi Mass, Slava Shechtman, Moran Mordechay, Ron Hoory, Oren Sar Shalom, Guy Lev and David Konopnicki |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-11 | 1313 | A Comparison of Speaker-based and Utterance-based Data Selection for Text-to-Speech Synthesis | Kai-Zhan Lee, Erica Cooper and Julia Hirschberg |
| 05.09.18 | 17:00 | Hall 4-6: Poster1 | Text Analysis, Multilingual Issues and Evaluation in Speech Synthesis | Poster | Wed-P-3-1-12 | 1316 | Data Requirements, Selection and Augmentation for DNN-based Speech Synthesis from Crowdsourced Data | Markus Toman, Geoffrey S. Meltzner and Rupal Patel. |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-1 | 2361 | Lightly Supervised vs. Semi-supervised Training of Acoustic Model on Luxembourgish for Low-resource Automatic Speech Recognition | Karel Veselý, Carlos Segura, Igor Szöke, Jordi Luque and Jan Černocký |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-2 | 1597 | Investigation on the Combination of Batch Normalization and Dropout in BLSTM-based Acoustic Modeling for ASR | Li Wenjie, Gaofeng Cheng, Fengpei Ge, Pengyuan Zhang and Yonghong Yan |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-3 | 1563 | Inference-Invariant Transformation of Batch Normalization for Domain Adaptation of Acoustic Models | Masayuki Suzuki, Tohru Nagano, Gakuto Kurata and Samuel Thomas |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-4 | 1162 | Active Learning for LF-MMI Trained Neural Networks in ASR | Yanhua Long, Hong Ye, Yijie Li and Jiaen Liang |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-5 | 2191 | An Investigation of Mixup Training Strategies for Acoustic Models in ASR | Ivan Medennikov, Yuri Khokhlov, Aleksei Romanenko, Dmitry Popov, Natalia Tomashenko, Ivan Sorokin and Alexander Zatvornitskiy |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-6 | 1972 | Comparison of Unsupervised Modulation Filter Learning Methods for ASR | Purvi Agrawal and Sriram Ganapathy |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-7 | 2517 | Improved Training for Online End-to-end Speech Recognition Systems | Suyoun Kim, Michael Seltzer, Jinyu Li and Rui Zhao |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-8 | 2335 | Combining Natural Gradient with Hessian Free Methods for Sequence Training | Adnan Haider and Philip Woodland |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-9 | 79 | Lattice-free State-level Minimum Bayes Risk Training of Acoustic Models | Naoyuki Kanda, Yusuke Fujita and Kenji Nagamatsu |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-10 | 2030 | A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition | Hao Tang, Wei-Ning Hsu, Francois Grondin and James Glass |
| 05.09.18 | 17:00 | Hall 4-6: Poster2 | Neural Network Training Strategies for ASR | Poster | Wed-P-3-2-11 | 1891 | Multilingual Deep Neural Network Training Using Cyclical Learning Rate | Andreas Søeborg Kirkedal and Yeon-Jun Kim |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-1 | 1541 | Development of the CUHK Dysarthric Speech Recognition System for the UA Speech Corpus | Jianwei Yu, Xurong Xie, Shoukang Hu, Shansong Liu, Max W. Y. Lam, Xixin Wu, Ka Ho Wong, Xunying Liu and Helen Meng |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-2 | 1266 | Automatic Evaluation of Speech Intelligibility Based on I-vectors in the Context of Head and Neck Cancers | Imed Laaridh, Corinne Fredouille, Alain Ghio, Muriel Lalain and Virginie Woisard |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-3 | 2250 | Dysarthric Speech Recognition Using Convolutional LSTM Neural Network | Myungjong Kim, Beiming Cao, Kwanghoon An and Jun Wang |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-4 | 1264 | Perceptual and Automatic Evaluations of the Intelligibility of Speech Degraded by Noise Induced Hearing Loss Simulation | Imed Laaridh, Julien Tardieu, Cynthia Magnen, Pascal Gaillard, Jérôme Farinas and Julien Pinquier |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-5 | 67 | Articulatory Features for ASR of Pathological Speech | Emre Yilmaz, Vikramjit Mitra, Chris Bartels and Horacio Franco |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-6 | 1806 | Mining Multimodal Repositories for Speech Affecting Diseases | Joana Correia, Bhiksha Raj, Isabel Trancoso and Francisco Teixeira |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-7 | 1428 | Long Distance Voice Channel Diagnosis Using Deep Neural Networks | Zhen Qin, Tom Ko and Guangjian Tian |
| 05.09.18 | 17:00 | Hall 4-6: Poster3 | Application of ASR in Medical Practice | Poster | Wed-P-3-3-8 | 40 | Speech Recognition for Medical Conversations | Chung-Cheng Chiu, Anshuman Tripathi, Katherine Chou, Chris Co, Navdeep Jaitly, Diana Jaunzeikare, Anjuli Kannan, Patrick Nguyen, Hasim Sak, Ananth Sankar, Justin Tansuwan, Nathan Wan, Yonghui Wu and Xuedong Zhang |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-1 | 1320 | Prosodic Focus Acquisition in French Early Cochlear Implanted Children | Chadi Farah, Stephane Roman and Mariapaola D'Imperio |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-2 | 1725 | The Role of Temporal Variation in Narrative Organization | Nassima Fezza |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-3 | 1827 | Interaction Mechanisms between Glottal Source and Vocal Tract in Pitch Glides | Tiina Murtola and Jarmo Malinen |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-4 | 1862 | Relating Articulatory Motions in Different Speaking Rates | Astha Singh, G. Nisha Meenakshi and Prasanta Kumar Ghosh |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-5 | 2371 | Estimation of the Asymmetry Parameter of the Glottal Flow Waveform Using the Electroglottographic Signal | Joao Cabral |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-6 | 1967 | Classification of Disorders in Vocal Folds Using Electroglottographic Signal | Tanumay Mandal, K Sreenivasa Rao and Sanjay Kumar Gupta |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-7 | 2572 | Automatic Glottis Localization and Segmentation in Stroboscopic Videos Using Deep Neural Network | Achuth Rao MV, Rahul Krishnamurthy, Pebbili Gopikishore, Veeramani Priyadharshini and Prasanta Kumar Ghosh |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-8 | 1948 | Respiratory and Respiratory Muscular Control in JL1’S and JL2’S Text Reading Utilizing 4-RSTs and a Soft Respiratory Mask with a Two-Way Bulb | Toshiko Isei-Jaakkola, Keiko Ochi and Keikichi Hirose |
| 05.09.18 | 17:00 | Hall 4-6: Poster4 | Source and Supra-segmentals | Poster | Wed-P-3-4-9 | 1849 | A Preliminary Study on Tonal Coarticulation in Continuous Speech | Lixia Hao, Wei Zhang, Yanlu Xie and Jinsong Zhang |
| 06.09.18 | 08:30 | Hall 3 | Plenary Talk-3 | Oral | Thu-Plenary-3 | 4004 | Speech and Language Processing for Learning and Wellbeing | Helen Meng |
| 06.09.18 | 10:00 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-1 | 2003 | Far-Field Speech Recognition Using Multivariate Autoregressive Models | Sriram Ganapathy and Madhumita Harish |
| 06.09.18 | 10:20 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-2 | 2566 | Efficient Implementation of the Room Simulator for Training Deep Neural Network Acoustic Models | Chanwoo Kim, Ehsan Variani, Arun Narayanan and Michiel Bacchiani |
| 06.09.18 | 10:40 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-3 | 1037 | Stream Attention for Distributed Multi-Microphone Speech Recognition | Xiaofei Wang, Ruizhi Li and Hynek Hermansky |
| 06.09.18 | 11:00 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-4 | 2284 | Recognizing Overlapped Speech in Meetings: a Multichannel Separation Approach Using Neural Networks | Takuya Yoshioka, Hakan Erdogan, Zhuo Chen, Xiong Xiao and Fil Alleva |
| 06.09.18 | 11:20 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-5 | 2196 | Integrating Neural Network Based Beamforming and Weighted Prediction Error Dereverberation | Lukas Drude, Christoph Boeddeker, Jahn Heymann, Reinhold Haeb-Umbach, Keisuke Kinoshita, Marc Delcroix and Tomohiro Nakatani |
| 06.09.18 | 11:40 | Hall 3 | Distant ASR | Oral | Thu-O-1-1-6 | 2427 | A Probability Weighted Beamformer for Noise Robust ASR | Suliang Bu, Yunxin Zhao, Meiyuh Hwang and Sining Sun |
| 06.09.18 | 10:00 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-1 | 2042 | Effects of Dimensional Input on Paralinguistic Information Perceived from Synthesized Dialogue Speech with Neural Network | Masaki Yokoyama, Tomohiro Nagata and Hiroki Mori |
| 06.09.18 | 10:20 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-2 | 2174 | Neural MultiVoice Models for Expressing Novel Personalities in Dialog | Shereen Oraby, Lena Reed, Sharath T.S., Shubhangi Tandon and Marilyn Walker |
| 06.09.18 | 10:40 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-3 | 2467 | Expressive Speech Synthesis Using Sentiment Embeddings | Igor Jauk, Jaime Lorenzo-Trueba, Junichi Yamagishi and Antonio Bonafonte |
| 06.09.18 | 11:00 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-4 | 1113 | Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder | Kei Akuzawa, Yusuke Iwasawa and Yutaka Matsuo |
| 06.09.18 | 11:20 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-5 | 1991 | Rapid Style Adaptation Using Residual Error Embedding for Expressive Speech Synthesis | Xixin Wu, Yuewen Cao, Mu Wang, Songxiang Liu, Shiyin Kang, Zhiyong Wu, Xunying Liu, Dan Su, Dong Yu and Helen Meng |
| 06.09.18 | 11:40 | Hall 1 | Expressive Speech Synthesis | Oral | Thu-O-1-2-6 | 1511 | EMPHASIS: an Emotional Phoneme-based Acoustic Model for Speech Synthesis System | Hao Li, Yongguo Kang and Zhenyu Wang |
| 06.09.18 | 10:00 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-1 | 996 | Bags in Bag: Generating Context-Aware Bags for Tracking Emotions from Speech | Jing Han, Zixing Zhang, Maximilian Schmitt, Zhao Ren, Fabien Ringeval and Björn Schuller |
| 06.09.18 | 10:20 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-2 | 1242 | An Attention Pooling Based Representation Learning Method for Speech Emotion Recognition | Pengcheng Li, Yan Song, Ian McLoughlin, Wu Guo and Lirong Dai |
| 06.09.18 | 10:40 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-3 | 2397 | Predicting Arousal and Valence from Waveforms and Spectrograms Using Deep Neural Networks | Zixiaofan Yang and Julia Hirschberg |
| 06.09.18 | 11:00 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-4 | 1353 | Emotion Identification from Raw Speech Signals Using DNNs | Mousmita Sarma, Pegah Ghahremani, Daniel Povey, Nagendra Kumar Goel, Kandarpa Kumar Sarma and Najim Dehak |
| 06.09.18 | 11:20 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-5 | 1455 | Encoding Individual Acoustic Features Using Dyad-Augmented Deep Variational Representations for Dialog-level Emotion Recognition | Jeng-Lin Li and Chi-Chun Lee |
| 06.09.18 | 11:40 | Hall 2 | Representation Learning for Emotion | Oral | Thu-O-1-3-6 | 1568 | Variational Autoencoders for Learning Latent Representations of Speech Emotion: a Preliminary Study | Siddique Latif, Rajib Rana, Junaid Qadir and Julien Epps |
| 06.09.18 | 10:00 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-1 | 1202 | Phoneme-to-Articulatory Mapping Using Bidirectional Gated RNN | Théo Biasutto-Lervat and Slim Ouni |
| 06.09.18 | 10:20 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-2 | 1108 | Tongue Segmentation with Geometrically Constrained Snake Model | Zhihua Su, Jianguo Wei, Qiang Fang, Jianrong Wang and Kiyoshi Honda |
| 06.09.18 | 10:40 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-3 | 1843 | Low Resource Acoustic-to-articulatory Inversion Using Bi-directional Long Short Term Memory | Aravind Illa and Prasanta Kumar Ghosh |
| 06.09.18 | 11:00 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-4 | 1570 | Automatic Visual Augmentation for Concatenation Based Synthesized Articulatory Videos from Real-time MRI Data for Spoken Language Training | Chandana S, Chiranjeevi Yarra, Ritu Aggarwal, Sanjeev Kumar Mittal, Kausthubha N K, Raseena K T, Astha Singh and Prasanta Kumar Ghosh |
| 06.09.18 | 11:20 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-5 | 1939 | Air-Tissue Boundary Segmentation in Real-Time Magnetic Resonance Imaging Video Using Semantic Segmentation with Fully Convolutional Networks | Valliappan CA, Renuka Mannem and Prasanta Kumar Ghosh |
| 06.09.18 | 11:40 | MR G.01-G.02 | Articulatory Information, Modeling and Inversion | Oral | Thu-O-1-4-6 | 1509 | Noise Robust Acoustic to Articulatory Speech Inversion | Nadee Seneviratne, Ganesh Sivaraman, Vikramjit Mitra and Carol Espy-Wilson |
| 06.09.18 | 10:00 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-1 | - | Welcome and Introduction | - |
| 06.09.18 | 10:05 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-2 | 1043 | Designing a Pneumatic Bionic Voice Prosthesis - A Statistical Approach for Source Excitation Generation | Farzaneh Ahmadi and Tomoki Toda |
| 06.09.18 | 10:20 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-3 | 1904 | A Neural Model to Predict Parameters for a Generalized Command Response Model of Intonation | Bastian Schnell and Philip N. Garner |
| 06.09.18 | 10:35 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-4 | 2484 | Articulation-to-Speech Synthesis Using Articulatory Flesh Point Sensors’ Orientation Information | Beiming Cao, Myungjong Kim, Jun R. Wang, Jan van Santen, Ted Mau and Jun Wang |
| 06.09.18 | 10:50 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-5 | 1565 | Effectiveness of Generative Adversarial Network for Non-Audible Murmur-to-Whisper Speech Conversion | Neil Shah, Nirmesh Shah and Hemant Patil |
| 06.09.18 | 11:05 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-6 | 2080 | Investigating Objective Intelligibility in Real-Time EMG-to-Speech Conversion | Lorenz Diener and Tanja Schultz |
| 06.09.18 | 11:20 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-7 | 2318 | Domain-Adversarial Training for Session Independent EMG-based Speech Recognition | Michael Wand, Tanja Schultz and Jürgen Schmidhuber |
| 06.09.18 | 11:35 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-8 | 1078 | Multi-Task Learning of Speech Recognition and Speech Synthesis Parameters for Ultrasound-based Silent Speech Interfaces | László Tóth, Gábor Gosztolya, Tamás Grósz, Alexandra Markó and Tamás Gábor Csapó |
| 06.09.18 | 11:50 | MR G.03-G.04 | Novel Paradigms for Direct Synthesis Based on Speech-Related Biosignals | Oral | Thu-SS-1-1-9 | - | Discussion and Closing | - |
| 06.09.18 | 10:00 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-1 | - | Introduction | |
| 06.09.18 | 10:15 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-2 | 1188 | Transcription Correction for Indian Languages Using Acoustic Signatures | Jeena JPrakash, Golda Brunet Rajan and Hema Murthy |
| 06.09.18 | 10:30 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-3 | 1302 | BUT System for Low Resource Indian Language ASR | Bhargav Pulugundla, Murali Karthick Baskar, Santosh Kesiraju, Ekaterina Egorova, Martin Karafiát, Lukáš Burget and Jan Černocký |
| 06.09.18 | 10:45 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-4 | 1553 | DA-IICT/IIITV System for Low Resource Speech Recognition Challenge 2018 | Hardik B. Sailor, Maddala V. Siva Krishna, Diksha Chhabra, Ankur T. Patil, Madhu Kamble and Hemant Patil |
| 06.09.18 | 11:00 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-5 | 1584 | An Exploration towards Joint Acoustic Modeling for Indian Languages: IIIT-H Submission for Low Resource Speech Recognition Challenge for Indian Languages, INTERSPEECH 2018 | Hari Krishna, Krishna Gurugubelli, Vishnu Vidyadhara Raju V and Anil Kumar Vuppala |
| 06.09.18 | 11:15 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-6 | 2117 | TDNN-based Multilingual Speech Recognition System for Low Resource Indian Languages | Noor Fathima, Tanvina Patel, Mahima C and Anuroop Iyengar |
| 06.09.18 | 11:30 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-7 | 2226 | Articulatory and Stacked Bottleneck Features for Low Resource Speech Recognition | Vishwas M. Shetty, Rini A Sharon, Basil Abraham, Tejaswi Seeram, Anusha Prakash, Nithya Ravi and S. Umesh |
| 06.09.18 | 11:45 | MR 1.01-1.02 | Low Resource Speech Recognition Challenge for Indian Languages | Oral | Thu-SS-1-2-8 | 2473 | ISI ASR System for the Low Resource Speech Recognition Challenge for Indian Languages | Jayadev Billa |
| 06.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 7 | S&T | Thu-S&T-1-1-1 | 3047 | An automated assistant for medical scribes | Gregory Finley, Erik Edwards, Amanda Robinson, Najmeh Sadoughi, James Fone, Mark Miller, David Suendermann-Oeft, Michael Brenndoerfer and Nico Axtmann |
| 06.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 7 | S&T | Thu-S&T-1-1-2 | 3048 | AGROASSAM: A Web Based Assamese Speech Recognition Application for Retrieving Agricultural Commodity Price and Weather Information | Abhishek Dey, Abhash Deka, Siddika Imani, Barsha Deka, Rohit Sinha, S R Mahadeva Prasanna, Priyankoo Sarmah, K Samudravijaya and Nirmala S.R. |
| 06.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 7 | S&T | Thu-S&T-1-1-3 | 3049 | Voice-powered solutions with Cloud AI | Dan Aharon |
| 06.09.18 | 10:00 | MR G.05-G.06 | Show and Tell 7 | S&T | Thu-S&T-1-1-4 | 3050 | Speech synthesis in the wild | Ganesh Sivaraman, Parav Nagarsheth and Elie Khoury |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-1 | 1020 | Deep Noise Tracking Network: a Hybrid Signal Processing/Deep Learning Approach to Speech Enhancement | Shuai Nie, Shan Liang, Bin Liu, Yaping Zhang, Wenju Liu and Jianhua Tao |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-2 | 1114 | A Deep Neural Network Based Harmonic Noise Model for Speech Enhancement | Zhiheng Ouyang, Hongjiang Yu, Wei-Ping Zhu and Benoit Champagne |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-3 | 1405 | A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement | Ke Tan and DeLiang Wang |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-4 | 1664 | All-Neural Multi-Channel Speech Enhancement | Zhong-Qiu Wang and DeLiang Wang |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-5 | 1484 | Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios | Hao Zhang and DeLiang Wang |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-6 | 1400 | The Conversation: Deep Audio-Visual Speech Enhancement | Triantafyllos Afouras, Joon Son Chung and Andrew Zisserman |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-7 | 2440 | Student-Teacher Learning for BLSTM Mask-based Speech Enhancement | Aswin Shanmugam Subramanian, Szu-Jui Chen and Shinji Watanabe |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-8 | 1730 | Speech Enhancement Using Deep Mixture of Experts Based on Hard Expectation Maximization | Pavan Karjol and Prasanta Kumar Ghosh |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-9 | 2461 | Adversarial Feature-Mapping for Speech Enhancement | Zhong Meng, Jinyu Li, Yifan Gong and Biing-Hwang (Fred) Juang |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-10 | 1237 | Biophysically-inspired Features Improve the Generalizability of Neural Network-based Speech Enhancement Systems | Deepak Baby and Sarah Verhulst |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-11 | 1439 | Error Modeling via Asymmetric Laplace Distribution for Deep Neural Network Based Single-Channel Speech Enhancement | Li Chai, Jun Du and Chin-Hui Lee |
| 06.09.18 | 10:00 | Hall 4-6: Poster1 | Deep Enhancement | Poster | Thu-P-1-1-12 | 2423 | A Priori SNR Estimation Based on a Recurrent Neural Network for Robust Speech Enhancement | Yangyang Xia and Richard Stern |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-1 | 1120 | Multiple Instance Deep Learning for Weakly Supervised Small-Footprint Audio Event Detection | Shao-Yen Tseng, Juncheng Li, Yun Wang, Florian Metze, Joseph Szurley and Samarjit Das |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-2 | 1243 | Unsupervised Temporal Feature Learning Based on Sparse Coding Embedded BoAW for Acoustic Event Recognition | Liwen Zhang, Jiqing Han and Shiwen Deng |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-3 | 1250 | Data Independent Sequence Augmentation Method for Acoustic Scene Classification | Zhang Teng, Kailai Zhang and Ji Wu |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-4 | 1299 | A Compact and Discriminative Feature Based on Auditory Summary Statistics for Acoustic Scene Classification | Hongwei Song, Jiqing Han and Shiwen Deng |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-5 | 1481 | ASe: Acoustic Scene Embedding Using Deep Archetypal Analysis and GMM | Pulkit Sharma, Vinayak Abrol and Anshul Thakur |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-6 | 1524 | Deep Convolutional Neural Network with Scalogram for Audio Scene Modeling | Hangting Chen, Pengyuan Zhang, Haichuan Bai, Qingsheng Yuan, Xiuguo Bao and Yonghong Yan |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-7 | 1637 | Time Aggregation Operators for Multi-label Audio Event Detection | Pankaj Joshi, Digvijaysingh Gautam, Ganesh Ramakrishnan and Preethi Jyothi |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-8 | 1821 | Early Detection of Continuous and Partial Audio Events Using CNN | Ian McLoughlin, Yan Song, Lam Dang Pham, Ramaswamy Palaniappan, Huy Phan and Yue Lang |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-9 | 1905 | Robust Acoustic Event Classification Using Bag-of-Visual-Words | Manjunath Mulimani and Shashidhar G Koolagudi |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-10 | 2083 | Wavelet Transform Based Mel-scaled Features for Acoustic Scene Classification | Shefali Waldekar and Goutam Saha |
| 06.09.18 | 10:00 | Hall 4-6: Poster2 | Acoustic Scenes and Rare Events | Poster | Thu-P-1-2-11 | 1138 | Multi-modal Attention Mechanisms in LSTM and Its Application to Acoustic Scene Classification | Teng Zhang, Kailai Zhang and Ji Wu |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-1 | 1122 | Contextual Language Model Adaptation for Conversational Agents | Anirudh Raju, Behnam Hedayatnia, Linda Liu, Ankur Gandhe, Chandra Khatri, Angeliki Metallinou, Anu Venkatesh and Ariya Rastrow |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-2 | 78 | Active Memory Networks for Language Modeling | Oscar Chen, Anton Ragni, Mark Gales and Xie Chen |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-3 | 1021 | Unsupervised and Efficient Vocabulary Expansion for Recurrent Neural Network Language Models in ASR | Yerbolat Khassanov and Eng Siong Chng | 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-4 | 1111 | Improving Language Modeling with an Adversarial Critic for Automatic Speech Recognition | Yike Zhang, Pengyuan Zhang and Yonghong Yan |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-5 | 1369 | Training Recurrent Neural Network through Moment Matching for NLP Applications | Yue Deng, Yilin Shen, KaWai Chen and Hongxia Jin |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-6 | 2476 | Investigation on LSTM Recurrent N-gram Language Models for Speech Recognition | Zoltán Tüske, Ralf Schlüter and Hermann Ney |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-7 | 2259 | Online Incremental Learning for Speaker-Adaptive Language Models | Chih Chi Hu, Bing Liu, John Shen and Ian Lane |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-8 | 1345 | Efficient Language Model Adaptation with Noise Contrastive Estimation and Kullback-Leibler Regularization | Jesús Andrés-Ferrer, Nathan Bodenstab and Paul Vozila |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-9 | 1413 | Recurrent Neural Network Language Model Adaptation for Conversational Speech Recognition | Ke Li, Hainan Xu, Yiming Wang, Daniel Povey and Sanjeev Khudanpur |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-10 | 84 | What to Expect from Expected Kneser-Ney Smoothing | Michael Levit, Sarangarajan Parthasarathy and Shuangyu Chang |
| 06.09.18 | 10:00 | Hall 4-6: Poster3 | Language Modeling | Poster | Thu-P-1-3-11 | 1070 | i-Vectors in Language Modeling: an Efficient Way of Domain Adaptation for Feed-Forward Models | Karel Beneš, Santosh Kesiraju and Lukáš Burget |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-1 | 2040 | How Did You like 2017? Detection of Language Markers of Depression and Narcissism in Personal Narratives | Eva-Maria Rathner, Julia Djamali, Yannik Terhorst, Björn Schuller, Nicholas Cummins, Gudrun Salamon, Christina Hunger-Schoppe and Harald Baumeister |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-2 | 1743 | Depression Detection from Short Utterances via Diverse Smartphones in Natural Environmental Conditions | Zhaocheng Huang, Julien Epps, Dale Joachim and Michael Chen |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-3 | 2169 | Multi-Lingual Depression-Level Assessment from Conversational Speech Using Acoustic and Text Features | Yasin Özkanca, Cenk Demiroglu, Aslı Besirli and Selime Celik |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-4 | 1059 | Dysarthric Speech Classification Using Glottal Features Computed from Non-words, Words and Sentences | Narendra N P and Paavo Alku |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-5 | 1079 | Identifying Schizophrenia Based on Temporal Parameters in Spontaneous Speech | Gábor Gosztolya, Anita Bagi, Szilvia Szalóki, István Szendi and Ildikó Hoffmann |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-6 | 2551 | Using Prosodic and Lexical Information for Learning Utterance-level Behaviors in Psychotherapy | Karan Singla, Zhuohao Chen, Nikolaos Flemotomos, James Gibson, Dogan Can, David Atkins and Shrikanth Narayanan |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-7 | 1630 | Automatic Speech Assessment for People with Aphasia Using TDNN-BLSTM with Multi-Task Learning | Ying Qin, Tan Lee, Siyuan Feng and Anthony Pak Hin Kong |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-8 | 1395 | Towards an Unsupervised Entrainment Distance in Conversational Speech Using Deep Neural Networks | Md Nasir, Brian Baucom, Shrikanth Narayanan and Panayiotis Georgiou |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-9 | 2186 | Patient Privacy in Paralinguistic Tasks | Francisco Teixeira, Alberto Abad and Isabel Trancoso |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-10 | 2155 | A Lightly Supervised Approach to Detect Stuttering in Children's Speech | Sadeen Alharbi, Madina Hasan, Anthony J H Simons, Shelagh Brumfitt and Phil Green |
| 06.09.18 | 10:00 | Hall 4-6: Poster4 | Speech Pathology, Depression, and Medical Applications | Poster | Thu-P-1-4-11 | 1298 | Learning Conditional Acoustic Latent Representation with Gender and Age Attributes for Automatic Pain Level Recognition | Jeng-Lin Li, Yi-Ming Weng, Chip-Jin Ng and Chi-Chun Lee |
| 06.09.18 | 12:00 | Hall 3 | Perspective Talk-4 | Oral | Thu-Perspective-4 | 4008 | Speaker and Language Recognition -- From Laboratory Technologies to the Wild | Sriram Ganapathy |
| 04.09.18 | 12:30 | Hall 3 | Industry Presentation-7 | Oral | Thu-IP-7 | - | Industry Presentation by Samsung | Vikram Vij |
| 04.09.18 | 12:30 | Hall 1 | Industry Presentation-8 | Oral | Thu-IP-8 | - | Industry Presentation by Baidu | Liang Gao |
| 04.09.18 | 12:30 | Hall 2 | Industry Presentation-9 | Oral | Thu-IP-9 | - | Industry Presentation by Nvidia | Ryan Leary |
| 06.09.18 | 14:30 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-1 | 1379 | A Deep Reinforcement Learning Based Multimodal Coaching Model (DCM) for Slot Filling in Spoken Language Understanding(SLU) | Yu Wang, Abhishek Patel, Yilin Shen and Hongxia Jin |
| 06.09.18 | 14:50 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-2 | 2256 | Is ATIS Too Shallow to Go Deeper for Benchmarking Spoken Language Understanding Models? | Frederic Bechet and Christian Raymond |
| 06.09.18 | 15:10 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-3 | 2358 | Robust Spoken Language Understanding via Paraphrasing | Avik Ray, Yilin Shen and Hongxia Jin |
| 06.09.18 | 15:30 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-4 | 1714 | Spoken SQuAD: a Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension | Chia-Hsuan Lee, Szu-Lin Wu, Chi-Liang Liu and Hung-yi Lee |
| 06.09.18 | 15:50 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-5 | 1149 | User Information Augmented Semantic Frame Parsing Using Progressive Neural Networks | Yilin Shen, Xiangyu Zeng, Yu Wang and Hongxia Jin |
| 06.09.18 | 16:10 | Hall 3 | Spoken Language Understanding | Oral | Thu-O-2-1-6 | 2403 | An Efficient Approach to Encoding Context for Spoken Language Understanding | Raghav Gupta, Abhinav Rastogi and Dilek Hakkani-Tur |
| 06.09.18 | 14:30 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-1 | 83 | Deep Speech Denoising with Vector Space Projections | Jeffrey Hetherly, Paul Gamble, Maria Alejandra Barrios, Cory Stephenson and Karl Ni |
| 06.09.18 | 14:50 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-2 | 1150 | A Shifted Delta Coefficient Objective for Monaural Speech Separation Using Multi-task Learning | Chenglin Xu, Wei Rao, Eng Siong Chng and Haizhou Li |
| 06.09.18 | 15:10 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-3 | 1406 | A Two-Stage Approach to Noisy Cochannel Speech Separation with Gated Residual Networks | Ke Tan and DeLiang Wang |
| 05.09.18 | 15:30 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-4 | 1140 | Monoaural Audio Source Separation Using Variational Autoencoders | Laxmi Pandey, Anurendra Kumar and Vinay Namboodiri |
| 06.09.18 | 15:50 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-5 | 2065 | Towards Automated Single Channel Source Separation Using Neural Networks | Arpita Gang, Pravesh Biyani and Akshay Soni |
| 06.09.18 | 16:10 | Hall 1 | Source Separation from Monaural Input | Oral | Thu-O-2-2-6 | 2441 | Investigations on Data Augmentation and Loss Functions for Deep Learning Based Speech-Background Separation | Hakan Erdogan and Takuya Yoshioka |
| 06.09.18 | 14:30 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-1 | 1019 | Annotator Trustability-based Cooperative Learning Solutions for Intelligent Audio Analysis | Simone Hantke, Christoph Stemp and Björn Schuller |
| 06.09.18 | 14:50 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-2 | 1063 | Semi-supervised Cross-domain Visual Feature Learning for Audio-Visual Broadcast Speech Transcription | Rongfeng Su, Xunying Liu and Lan Wang |
| 06.09.18 | 15:10 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-3 | 1943 | Deep Lip Reading: a Comparison of Models and an Online Application | Triantafyllos Afouras, Joon Son Chung and Andrew Zisserman |
| 06.09.18 | 15:30 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-4 | 1447 | Iterative Learning of Speech Recognition Models for Air Traffic Control | Ajay Srinivasamurthy, Petr Motlicek, Mittul Singh, Youssef Oualil, Matthias Kleinert, Heiko Ehr and Hartmut Helmke |
| 06.09.18 | 15:50 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-5 | 2359 | Speaker Adaptive Audio-Visual Fusion for the Open-Vocabulary Section of AVICAR | Leda Sari, Mark Hasegawa-Johnson, Kumaran S, Georg Stemmer and Krishnakumar N Nair |
| 06.09.18 | 16:10 | Hall 2 | Multimodal Systems | Oral | Thu-O-2-3-6 | 1748 | Multimodal Name Recognition in Live TV Subtitling | Marek Hrúz, Aleš Pražák and Michal Bušta |
| 06.09.18 | 14:30 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-1 | 46 | Dithered Quantization for Frequency-Domain Speech and Audio Coding | Tom Bäckström, Johannes Fischer and Sneha Das |
| 06.09.18 | 14:50 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-2 | 1026 | Postfiltering with Complex Spectral Correlations for Speech and Audio Coding | Sneha Das and Tom Bäckström |
| 06.09.18 | 15:10 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-3 | 1027 | Postfiltering Using Log-Magnitude Spectrum for Speech and Audio Coding | Sneha Das and Tom Bäckström |
| 06.09.18 | 15:30 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-4 | 2096 | Temporal Noise Shaping with Companding | Arijit Biswas, Per Hedelin, Lars Villemoes and Vinay Melkote |
| 06.09.18 | 15:50 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-5 | 2577 | Multi-frame Quantization of LSF Parameters Using a Deep Autoencoder and Pyramid Vector Quantizer | Yaxing Li, Eshete Derb Emiru, Shengwu Xiong, Anna Zhu, Pengfei Duan and Yichang Li |
| 06.09.18 | 16:10 | MR G.01-G.02 | Coding | Oral | Thu-O-2-4-6 | 2578 | Multi-frame Coding of LSF Parameters Using Block-Constrained Trellis Coded Vector Quantization | Yaxing Li, Shan Xu, Shengwu Xiong, Anna Zhu, Pengfei Duan and Yueming Ding |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-1 | 1044 | Training Utterance-level Embedding Networks for Speaker Identification and Verification | Heewoong Park, Sukhyun Cho, Kyubyong Park, Namju Kim and Jonghun Park |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-2 | 1102 | Analysis of Complementary Information Sources in the Speaker Embeddings Framework | Mahesh Kumar Nandwana, Mitchell McLaren, Diego Castan, Julien van Hout and Aaron Lawson |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-3 | 1158 | Self-Attentive Speaker Embeddings for Text-Independent Speaker Verification | Yingke Zhu, Tom Ko, David Snyder, Brian Mak and Daniel Povey |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-4 | 1515 | An Improved Deep Embedding Learning Method for Short Duration Speaker Verification | Zhifu Gao, Yan Song, Ian McLoughlin, Wu Guo and Lirong Dai |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-5 | 1608 | Avoiding Speaker Overfitting in End-to-End DNNs Using Raw Waveform for Text-Independent Speaker Verification | Jee-weon Jung, Hee-soo Heo, IL-ho Yang, Hye-jin Shim and Ha-jin Yu |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-6 | 1688 | Deeply Fused Speaker Embeddings for Text-Independent Speaker Verification | Gautam Bhattacharya, Md Jahangir Alam, Vishwa Gupta and Patrick Kenny |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-7 | 1804 | Employing Phonetic Information in DNN Speaker Embeddings to Improve Speaker Recognition Performance | Md Hafizur Rahman, Ivan Himawan, Mitchell McLaren, Clinton Fookes and Sridha Sridharan |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-8 | 2300 | End-to-end Text-dependent Speaker Verification Using Novel Distance Measures | Subhadeep Dey, Srikanth Madikeri and Petr Motlicek |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-9 | 50 | Robust Speaker Clustering using Mixtures of von Mises-Fisher Distributions for Naturalistic Audio Streams | Harishchandra Dubey, Abhijeet Sangwan and John H. L. Hansen |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-10 | 2305 | Triplet Network with Attention for Speaker Diarization | Huan Song, Megan Willi, Jayaraman J. Thiagarajan, Visar Berisha and Andreas Spanias |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-11 | 1680 | I-vector Transformation Using Conditional Generative Adversarial Networks for Short Utterance Speaker Verification | Jiacen Zhang, Nakamasa Inoue and Koichi Shinoda |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-12 | 92 | Analysis of Length Normalization in End-to-End Speaker Verification System | Weicheng Cai, Jinkun Chen and Ming Li |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-13 | 1545 | Angular Softmax for Short-Duration Text-independent Speaker Verification | Zili Huang, Shuai Wang and Kai Yu |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-14 | 1058 | An End-to-End Text-Independent Speaker Identification System on Short Utterances | Ruifang Ji, Xinyuan Cai and Xu Bo |
| 06.09.18 | 14:30 | Hall 4-6: Poster1 | Speaker Verification Using Neural Network Methods II | Poster | Thu-P-2-1-15 | 1023 | MTGAN: Speaker Verification through Multitasking Triplet Generative Adversarial Networks | Wenhao Ding and Liang HE |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-1 | 47 | Categorical vs Dimensional Perception of Italian Emotional Speech | Emilia Parada-Cabaleiro, Giovanni Costantini, Anton Batliner, Alice Baird and Björn Schuller |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-2 | 1820 | A Three-Layer Emotion Perception Model for Valence and Arousal-Based Detection from Multilingual Speech | Xingfeng Li and Masato Akagi |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-3 | 1778 | Cross-lingual Speech Emotion Recognition through Factor Analysis | Brecht Desplanques and Kris Demuynck |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-4 | 2222 | Modeling Self-Reported and Observed Affect from Speech | Jian Cheng, Jared Bernstein, Elizabeth Rosenfeld, Peter W. Foltz, Alex S. Cohen, Terje B. Holmlund and Brita Elvevåg |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-5 | 1327 | Stochastic Shake-Shake Regularization for Affective Learning from Speech | Che-Wei Huang and Shrikanth Narayanan |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-6 | 2350 | Investigating Speech Enhancement and Perceptual Quality for Speech Emotion Recognition | Anderson R. Avila, Md Jahangir Alam, Douglas O'Shaughnessy and Tiago Falk |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-7 | 1933 | Demonstrating and Modelling Systematic Time-varying Annotator Disagreement in Continuous Emotion Annotation | Mia Atcheson, Vidhyasaharan Sethu and Julien Epps |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-8 | 1432 | Speech Emotion Recognition from Variable-Length Inputs with Triplet Loss Function | Jian Huang, Ya Li, Jianhua Tao and Zhen Lian |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-9 | 1744 | Imbalance Learning-based Framework for Fear Recognition in the MediaEval Emotional Impact of Movies Task | Xiaotong Zhang, Xingliang Cheng, Mingxing Xu and Thomas Fang Zheng |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-10 | 2228 | Emotion Recognition from Variable-Length Speech Segments Using Deep Learning on Spectrograms | Xi Ma, Zhiyong Wu, Jia Jia, Mingxing Xu, Helen Meng and Lianhong Cai |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-11 | 1811 | Speech Emotion Recognition Using Spectrogram & Phoneme Embedding | Promod Yenigalla, Abhay Kumar, Suraj Tripathi, Chirag Singh, Sibsambhu Kar and Jithendra Vepa |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-12 | 1883 | On Enhancing Speech Emotion Recognition Using Generative Adversarial Networks | Saurabh Sahu, Rahul Gupta and Carol Espy-Wilson |
| 06.09.18 | 14:30 | Hall 4-6: Poster2 | Emotion Recognition and Analysis | Poster | Thu-P-2-2-13 | 1391 | Ladder Networks for Emotion Recognition: Using Unsupervised Auxiliary Tasks to Improve Predictions of Emotional Attributes | Srinivas Parthasarathy and Carlos Busso |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-1 | 1589 | Knowledge Distillation for Sequence Model | Mingkun Huang, Yongbin You, Zhehuai Chen, Yanmin Qian and Kai Yu |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-2 | 1475 | Improving CTC-based Acoustic Model with Very Deep Residual Time-delay Neural Networks | Sheng Li, Xugang Lu, Ryoichi Takashima, Peng Shen, Tatsuya Kawahara and Hisashi Kawai |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-3 | 1370 | Filter Sampling and Combination CNN (FSC-CNN): a Compact CNN Model for Small-footprint ASR Acoustic Modeling Using Raw Waveforms | Jinxi Guo, Ning Xu, Xin Chen, Yang Shi, Kaiyuan Xu and Abeer Alwan |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-4 | 1407 | Twin Regularization for Online Speech Recognition | Mirco Ravanelli, Dmitriy Serdyuk and Yoshua Bengio |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-5 | 1910 | Self-Attentional Acoustic Models | Matthias Sperber, Jan Niehues, Graham Neubig, Sebastian Stüker and Alex Waibel |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-6 | 1797 | Hierarchical Recurrent Neural Networks for Acoustic Modeling | Jinhwan Park, Iksoo Choi, Yoonho Boo and Wonyong Sung |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-7 | 2061 | Dictionary Augmented Sequence-to-Sequence Neural Network for Grapheme to Phoneme Prediction | Antoine Bruguier, Anton Bakhtin and Dravyansh Sharma |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-8 | 1156 | Leveraging Second-Order Log-Linear Model for Improved Deep Learning Based ASR Performance | Ankit Raj, Shakti P Rath and Jithendra Vepa |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-9 | 1417 | Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks | Daniel Povey, Gaofeng Cheng, Yiming Wang, Ke Li, Hainan Xu, Mahsa Yarmohammadi and Sanjeev Khudanpur |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-10 | 1800 | Completely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings | Da-Rong Liu, Kuan-yu Chen, Hung-yi Lee and Lin-shan Lee |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-11 | 1376 | Phone Recognition Using a Non-Linear Manifold with Broad Phone Class Dependent DNNs | Mengjie Qian, Linxue Bai, Peter Jančovič and Martin Russell |
| 06.09.18 | 14:30 | Hall 4-6: Poster3 | Acoustic Modelling | Poster | Thu-P-2-3-12 | 1535 | A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation | Ehsan Hosseini-Asl, Yingbo Zhou, Caiming Xiong and Richard Socher |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-1 | 2025 | Interactions between Vowels and Nasal Codas in Mandarin Speakers’ Perception of Nasal Finals | Chong Cao, Wei Wei, Wei Wang, Yanlu Xie and Jinsong Zhang |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-2 | 1245 | Weighting Pitch Contour and Loudness Contour in Mandarin Tone Perception in Cochlear Implant Listeners | Qinglin Meng, Nengheng Zheng, Ambika Prasad Mishra, Jacinta Dan Luo and Jan W. H. Schnupp |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-3 | 2081 | Implementing DIANA to Model Isolated Auditory Word Recognition in English | Filip Nenadić, Louis ten Bosch and Benjamin V. Tucker |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-4 | 2114 | Effects of Homophone Density on Spoken Word Recognition in Mandarin Chinese | Bhamini Sharma |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-5 | 1285 | Visual Timing Information in Audiovisual Speech Perception: Evidence from Lexical Tone Contour | Hui Xie, Biao Zeng and Rui Wang |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-6 | 73 | COSMO SylPhon: A Bayesian perceptuo-motor model to assess phonological learning | Marie-Lou Barnaud, Juien Diard, Pierre Bessière and Jean-Luc Schwartz |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-7 | 2104 | Experience-dependent Influence of Music and Language on Lexical Pitch Learning Is Not Additive | Akshay Raj Maggu, Patrick C. M. Wong, Hanjun Liu and Francis C. K. Wong |
| 06.09.18 | 14:30 | Hall 4-6: Poster4 | Speech and Speaker Perception | Poster | Thu-P-2-4-8 | 2331 | Influences of Fundamental Oscillation on Speaker Identification in Vocalic Utterances by Humans and Computers | Volker Dellwo, Thayabaran Kathiresan, Elisa Pellegrino, Lei He, Sandra Schwab and Dieter Maurer |